

; Intel syntax
locked: ; The lock variable. 1 = locked, 0 = unlocked.
dd 0
spin_lock:
mov eax, 1 ; Set the EAX register to 1.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
; This will always store 1 to the lock, leaving
; the previous value in the EAX register.
test eax, eax ; Test EAX with itself. Among other things, this will
; set the processor's Zero Flag if EAX is 0.
; If EAX is 0, then the lock was unlocked and
; we just locked it.
; Otherwise, EAX is 1 and we didn't acquire the lock.
jnz spin_lock ; Jump back to the MOV instruction if the Zero Flag is
; not set; the lock was previously locked, and so
; we need to spin until it becomes unlocked.
ret ; The lock has been acquired, return to the calling
; function.
spin_unlock:
mov eax, 0 ; Set the EAX register to 0.
xchg eax, [locked] ; Atomically swap the EAX register with
; the lock variable.
ret ; The lock has been released.
但是上述的代码在有些cpu上是没法正常工作的,这取决于xchg eax, [locked]这句指令中,xchg指令的实现中是否使用了内存屏障来保障内存读写顺序。
那内存屏障究竟具体做了什么呢?先看下面一张图:
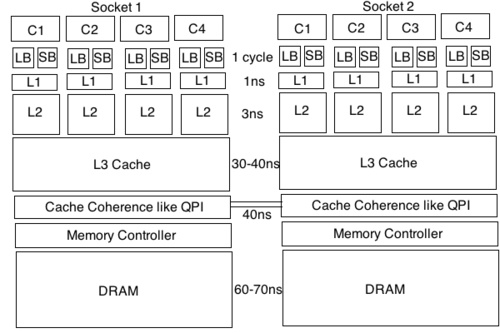
cpu对寄存器,store buffer,load buffer的访问是远远快于cache和memory的。而且在现代cpu的设计中,提升性能的主要方式就是提升并行度。而提升指令级并行的两种主要方式,包括增加流水线深度,和多发射流水线(每条流水线执行多条指令)。由于每条指令的执行时间由流水线上最耗时的阶段来决定,因此增加流水线的深度后,可以缩短每条指令的执行耗时。不过因为流水线每个阶段之间传递数据的耗时无法忽略,因此可增加的流水线的深度会存在上限。所以,另外一种方法就是让每条流水线执行多条指令。实现多发射流水线的方式包括静态多发射,和动态多发射。静态多发射可以理解为一条指令包含多个操作(VLIW[6])。动态多发射也叫超标量技术[7],一条流水线存在多个执行单元,可用于执行例如浮点计算,整型计算,store/load等。多条指令可以根据其依赖关系,实现并行执行。而且由于store/load buffer的存在,写入数据不必立马刷入内存,读取数据可以提前读取,因此可以进一步提升并行度。同时,对于分支指令,存在speculation execution(推测执行),最近爆出的cpu漏洞就是和这个技术有关。因此,从上面介绍的可知,我们的程序指令其实是乱序执行的。不过,为了保证正确性,执行后的结果却是顺序提交的,这样就防止出现分支预测失败,而导致执行了不该被执行的指令。在乱序执行的过程中,结果只会被暂存到物理寄存器和buffer中,只有当提交的时候,才会将更改写入ISA(指令级架构)寄存器和cache中。因此,当出现预测失败的时候,只要丢弃掉执行的结果就行,未提交的指令的修改不会对外暴露出来。多说一句,我们写汇编时候用到的寄存器其实是逻辑寄存器,或者说ISA寄存器,它们和真实的物理寄存器的之间存在映射关系。
通过我上述的介绍可以知道,首先,cpu写入的数据不会也没有必要直接写到cache中,而是会缓存在寄存器和store buffer中,读取到的数据也会缓存在load buffer中。然后,读写指令由于存在指令并行优化,顺序会被打乱。
写到这里,应该可以明白了,内存屏障的外在表现形式是:
阻止读写内存动作的重排序。比如,mfence阻止mfence指令之后的读写内存的动作被重排序到mfence之前,以及阻止mfence指令被重排序到更早的读写内存动作之前。sfence和mfence类似,但只是阻止写内存动作的重排序。lfence同样和mfence类似,但只是阻止读内存动作的重排序。
而内存屏障的实现,以x86架构举例:
sfence/mfence会将store buffer中缓存的修改刷入L1 cache中,使得其他cpu核可以观察到这些修改,而且sfence/mfence之后的写操作,不会被调度到sfence/mfence之前。
但是在新版本的intel的cpu实现中,为了提升性能,打破了上述的约束。
首先,允许预读取操作,将数据提前存到load buffer中。
然后,允许store buffer的缓存,因此导致之前的写->读操作,变成读->写操作。
最后,字符串操作指令在单指令内部,会存在乱序(启动fast string模式下);绕过cache的写指令(MOVNTI, MOVNTQ, MOVNTDQ, MOVNTPS, and MOVNTPD)之间,可以存在指令的重排序。
因此,此时需要内存屏障的出现,来保障memory order。 顺便说下,对x86架构下使用的x86-TSO内存一致性模型感兴趣的,可以看这里[10]。
上面,我们提到了sequential consistency,但是cpu在不断优化的过程中,会降低一致性的要求,来逐渐提升性能。此时,为了保障程序的正确,需要开发者使用例如内存屏障这些工具,来保障一致性。因此,cpu选择实现怎样的一致性内存模型,本质上是以降低指令排序约束来提升并发度,和提升编程复杂度,这两者之间的一个tradeoff的过程。
