

简介
本文会手把手教你- 服务端配置puppeteer
- 截图关键代码实现
- 截图服务压测
依赖
- puppeteer
- nestjs
- pm2
背景
🐟 近一年多都在开发优化公司的一个前端较重的项目,类似于一个网页版的ppt(如下图,这里拿keynote做一个展示,毕竟不能透露公司内部项目的啦~),功能很多,性能一直是项目里面难于突破的瓶颈😿,随着业务功能从0到1,功能已经满足于公司业务,组里前端从11名同学,就剩下4名同学(加上我)维护,产品也是走了一波又一波,领导换了一波又一波。言归正传,为了将左侧大纲作为图片展示,减少页面的dom数量,并且图片的用处很多,例如生成pdf,预览等等。所以一个截图服务就此诞生了~
前端与服务端截图优劣
前端利用 html2canvas 等框架也可以在前端页面进行HTML截图
优点:截图运行在客户端,不用担心服务器资源与并发等相关问题,对于纯前端小伙伴是一个很容易上手的项目。
缺点:第一个缺点是,html2canvas中(html2canvas原理是foreignObject与canvas)跨域以及一些不能序列化的元素无法生成正确的截图;第二个缺点是,js是单线程的,截图时会占用主线程,使得页面进入假死状态,无法进行UI操作。
服务端利用puppeteer调用chromium截图方法
优点:相对于前端实现,接口请求服务端为异步事件,不占用主线程资源。
缺点:截图服务生成需要渲染时间,且时间因页面的复杂度而定,所以无法同步生成截图。异步生成截图带来的问题就是,客户端需要定时去轮询资源是否存在,(当然你可以用长连接生成截图)判断资源存在之后再去展示。并且要考虑服务器的并发与任务调度等问题。
服务端准备工作
安装puppeteer-core
首先在puppeteer官网上查找想要使用的chromium版本github.com/puppeteer/p…
我是使用是"puppeteer": "3.3.0"对应chromium版本是83
如何下载puppeteer中对应的chromium
下载链接在puppeteer\src\BrowserFetcher.js中,如下图:
对应版本在package.json中,如下图:
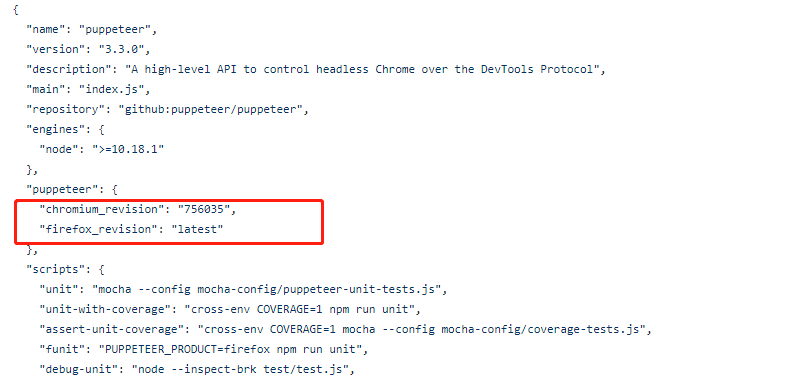
完整链接
https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/756035/chrome-linux.zip服务器配置chromium
下载chromium
wget https://storage.googleapis.com/chromium-browser-snapshots/Linux_x64/756035/chrome-linux.zip
检测缺失的依赖包
ldd chrome | grep not如果缺失依赖包,如下图
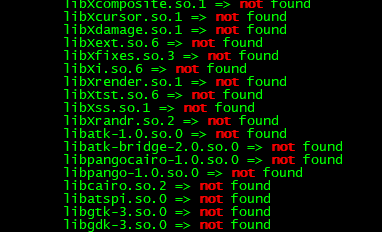
则运行安装如下:
#依赖库
yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 -y
#字体
yum install ipa-gothic-fonts xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc -y试运行chromium
const puppeteer = require("puppeteer");
(async () => {
const browser = await puppeteer.launch({ headless: false,
executablePath : '/home/homework/local-chrome/chrome-linux/chrome'
});
const page = await browser.newPage();
await page.goto("https://google.com");
await page.screenshot({ path: "example.png" });
await browser.close();
})();
截图关键代码实现
流程介绍
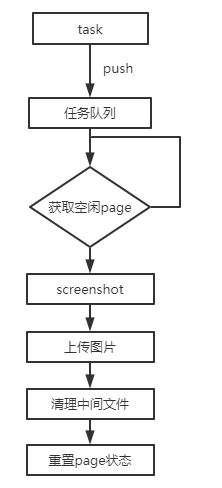
预加载逻辑
为了节约browser openpage的时间,预先加载10个page实例;
let ready = false;
let domCaptureBrowser: CreateBrowserPage;
(async () => {
const time = +new Date().getTime();
const filePath = 'domcapture.html';
domCaptureBrowser = new CreateBrowserPage(10);
const init = await domCaptureBrowser.init();
if (!init) {
Log({data: '初始化domcapture preopen error', logType: 'error'});
return;
}
const html = await getFile({serverWebroot: config.serverWebroot, filePath});
const htmlFile = path.join(config.outputPath, `/domcapture.html`);
try {
fs.writeFileSync(htmlFile, html);
} catch (error) {
Log({data: `初始化domcapture preopen html write error`, logType: 'error'});
}
await (async () => {
const len = domCaptureBrowser.pageList.length;
for (let i = 0; i < len; i++) {
try {
await domCaptureBrowser.pageList[i].page.goto(`${config.serverProtocol}${htmlFile}`, {
waitUntil: ['load', 'networkidle0'],
timeout: 1000 * 3 * 60,
});
} catch (error) {
Log({data: `初始化domcapture preopen page No.${i} error`, logType: 'error'});
}
}
})();
ready = true;
Log({data: `初始化domcapture preopen success, newpage用时: ${(+ new Date().getTime() - time) / 1000}s`});
})();
export {
ready,
domCaptureBrowser,
};截图服务压测
压测使用的是stress,公司测试大佬们搭建的一套服务。
建议压测一下服务,因为本地测试单点不会触发并发引起的问题,因为在压测的过程中还是发现了代码page调度的问题。

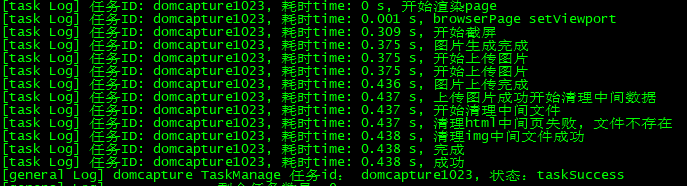
最后展示一下生成日志
总结
总体来讲截图服务开发及搭建还是很简单的一个过程,不过就是第一次搭建node服务走了很多弯路,比如:服务器没有连网.. 变量没有配,新申请的机器一些配置没有初始化,最后找了op解决,但是发现这些问题浪费了一些时间,以及pm2多进程造成taskId生成异常等...
关于pm2以及nestjs的使用会在其他文章中继续讲述,感谢阅读~
