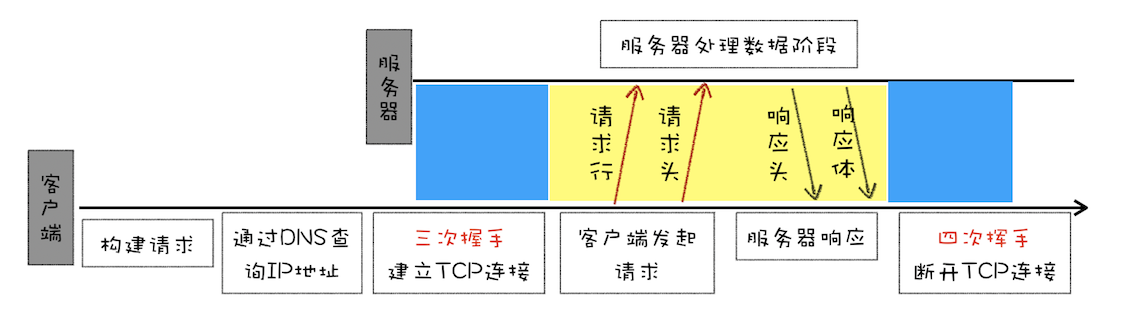
HTTP 都是基于 TCP 协议的,所以客户端先要根据 IP 地址、端口和服务器建立 TCP 连接,而建立连接的过程就是 TCP 协议三次握手的过程。
HTTP/1.0 的方案是通过请求头和响应头来进行协商,在发起请求时候会通过 HTTP 请求头告诉服务器它期待服务器返回什么类型的文件、采取什么形式的压缩、提供什么语言的文件以及文件的具体编码。最终发送出来的请求头内容如下:
请求头信息
accept: text/html//期望服务器返回 html 类型的文件
accept-encoding: gzip, deflate, br//期望服务器可以采用 gzip、deflate 或者 br 其中的一种压缩方式
accept-Charset: ISO-8859-1,utf-8//期望返回的文件编码是 UTF-8 或者 ISO-8859-1
accept-language: zh-CN,zh//
响应头信息
浏览器需要根据响应头的信息来处理数据
content-encoding: br //采用br压缩
content-type: text/html; charset=UTF-8 返回html文件 使用utf-8编码
HTTP 1.0中 每进行一次通讯,都需要发TCP连接 传输 HTTP 数据和断开 TCP 。这样无疑效率太低。
队头阻塞
持久连接虽然能减少 TCP 的建立和断开次数,但是它需要等待前面的请求返回之后,才能进行下一次请求。如果 TCP 通道中的某个请求因为某些原因没有及时返回,那么就会阻塞后面的所有请求,这就是著名的队头阻塞的问题。
HTTP1.1的改进
HTTP/1.1 为网络效率做了大量的优化,最核心的有如下三种方式:
- 增加了持久连接;
- 浏览器为每个域名最多同时维护 6 个 TCP 持久连接;
- 使用 CDN 的实现域名分片机制。
HTTP/1.1 中增加了持久连接的方法,它的特点是在一个 TCP 连接上可以传输多个 HTTP 请求,只要浏览器或者服务器没有明确断开连接,那么该 TCP 连接会一直保持。
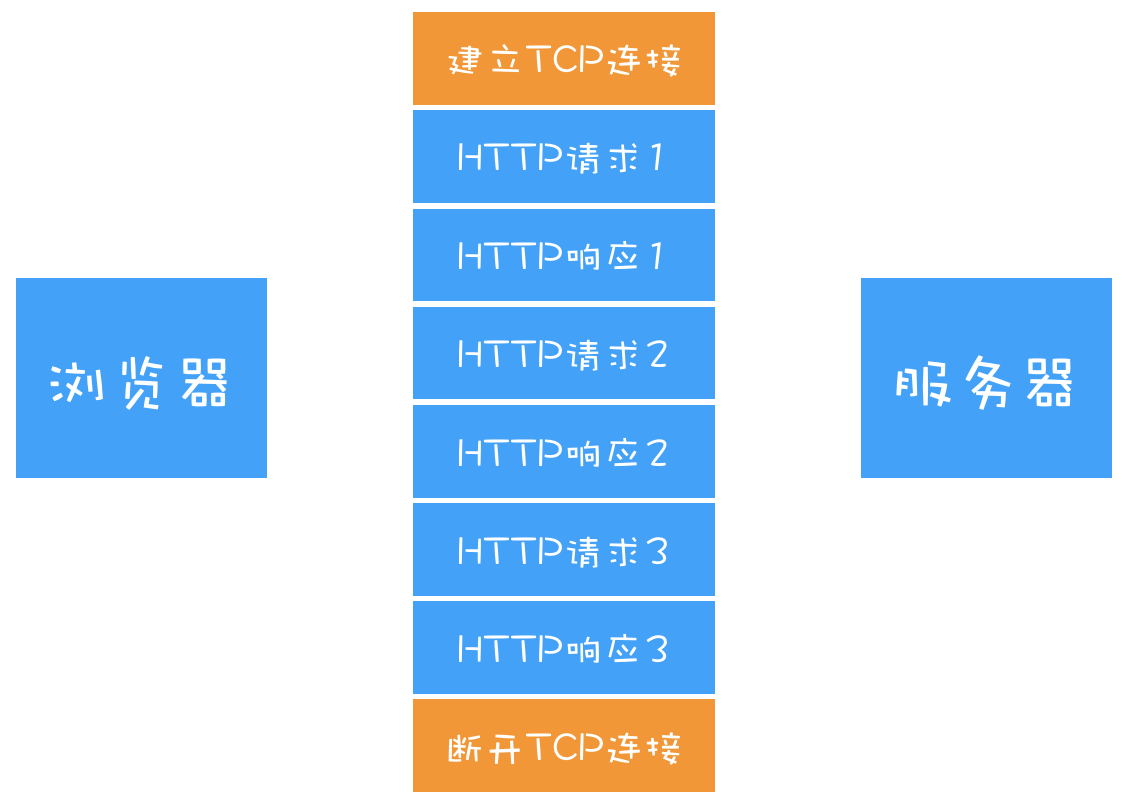
开启TCP长连接的标识 Connection:keep-alive
HTTP1.0中以及HTTP1.1中,引入了重用连接的机制,就是在http请求头中加入 Connection:keep-alive来告诉对方这个请求完成后不要关闭。
keep-alive的优点:
- 较少的CPU和内存的使用
- 允许请求和应答的HTTP管线化
- 降低堵塞控制(TCP连接减少了)
HTTP 的持久连接可以有效减少 TCP 建立连接和断开连接的次数,这样的好处是减少了服务器额外的负担,并提升整体 HTTP 的请求时长。
持久连接在 HTTP/1.1 中是默认开启的
Connection: keep-alive /close
目前浏览器中对于同一个域名,默认允许同时建立 6 个 TCP 持久连接。
HTTP1.1带来的问题
上行带宽:带宽是指每秒最大能发送或者接收的字节数。我们把每秒能发送的最大字节数称为上行带宽。 下行带宽:每秒能够接收的最大字节数称为下行带宽。
1 TCP 的慢启动
慢启动是 TCP 为了减少网络拥塞的一种策略,我们是没有办法改变的。
一旦一个 TCP 连接建立之后,就进入了发送数据状态,刚开始 TCP 协议会采用一个非常慢的速度去发送数据,然后慢慢加快发送数据的速度,直到发送数据的速度达到一个理想状态,我们把这个过程称为慢启动。
慢启动会带来性能问题,是因为页面中常用的一些关键资源文件本来就不大,如 HTML 文件、CSS 文件和 JavaScript 文件,通常这些文件在 TCP 连接建立好之后就要发起请求的,但这个过程是慢启动,所以耗费的时间比正常的时间要多很多,这样就推迟了宝贵的首次渲染页面的时长了。
2开启了多条 TCP 连接,那么这些连接会竞争固定的带宽
想象一下,系统同时建立了多条 TCP 连接,当带宽充足时,每条连接发送或者接收速度会慢慢向上增加;而一旦带宽不足时,这些 TCP 连接又会减慢发送或者接收的速度。比如一个页面有 200 个文件,使用了 3 个 CDN,那么加载该网页的时候就需要建立 6 * 3,也就是 18 个 TCP 连接来下载资源;在下载过程中,当发现带宽不足的时候,各个 TCP 连接就需要动态减慢接收数据的速度。
因为有的 TCP 连接下载的是一些关键资源,如 CSS 文件、JavaScript 文件等,而有的 TCP 连接下载的是图片、视频等普通的资源文件,但是多条 TCP 连接之间又不能协商让哪些关键资源优先下载,这样就有可能影响那些关键资源的下载速度了。
3 HTTP/1.1 队头阻塞的问题
HTTP/1.1 中使用持久连接时,虽然能公用一个 TCP 管道,但是在一个管道中同一时刻只能处理一个请求,在当前的请求没有结束之前,其他的请求只能处于阻塞状态。这意味着我们不能随意在一个管道中发送请求和接收内容。
假如有的请求被阻塞了 5 秒,那么后续排队的请求都要延迟等待 5 秒,在这个等待的过程中,带宽、CPU 都被白白浪费了。
HTTP/1.1 所存在的一些主要问题:慢启动和 TCP 连接之间相互竞争带宽是由于 TCP 本身的机制导致的,而队头阻塞是由于 HTTP/1.1 的机制导致的。
HTTP2.0 一个域名只使用一个 TCP 长连接和消除队头阻塞问题
- 改善慢启动 和多个TCP抢占带宽
HTTP/2 的思路就是一个域名只使用一个 TCP 长连接来传输数据,这样整个页面资源的下载过程只需要一次慢启动,同时也避免了多个 TCP 连接竞争带宽所带来的问题。
- 队头阻塞的问题
- 以 HTTP/2 需要实现资源的并行请求,也就是任何时候都可以将请求发送给服务器,而并不需要等待其他请求的完成,然后服务器也可以随时返回处理好的请求资源给浏览器。
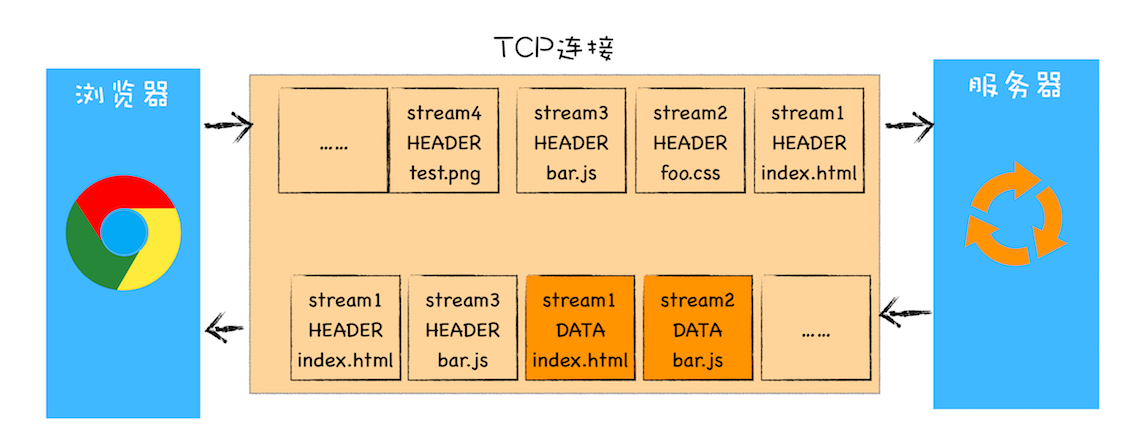
HTTP/2 使用了多路复用技术,可以将请求分成一帧一帧的数据去传输,这样带来了一个额外的好处,就是当收到一个优先级高的请求时,比如接收到 JavaScript 或者 CSS 关键资源的请求,服务器可以暂停之前的请求来优先处理关键资源的请求。
HTTP/2 的最核心功能,它能实现资源的并行传输。多路复用技术是建立在二进制分帧层的基础之上。其实基于二进制分帧层,HTTP/2 还附带实现了很多其他功能。
特点:
- 多路复用技术。
- 提供了请求优先级,可以在发送请求时,标上该请求的优先级,这样服务器接收到请求之后,会优先处理优先级高的请求。
- 服务器推送,当用户请求一个 HTML 页面之后,服务器知道该 HTML 页面会引用几个重要的 JavaScript 文件和 CSS 文件,那么在接收到 HTML 请求之后,附带将要使用的 CSS 文件和 JavaScript 文件一并发送给浏览器,这样当浏览器解析完 HTML 文件之后,就能直接拿到需要的 CSS 文件和 JavaScript 文件,这对首次打开页面的速度起到了至关重要的作用。
- 头部压缩,HTT2.0对请求头进行压缩。
GET VS POST
- 数据传输方式不同。GET请求通过URL传输,POST通过请求体传输。
- GET请求主要是获取资源重复刷新没什么问题,POST请求可能重复提交表单。
- GET请求是幂等的。POST请求不是幂等。
什么是幂等?
幂等的概念是指同一个请求方法执行多次和执行一次的效果是相同的。
POST VS PUT
put都是向服务端发送新增资源,PUT方法是幂等的,POST方法是非幂等的。
假设我们要创建一篇文章通过POST www.baidu.com.articles,我们post提交多次可以创建多条数据,这样是非幂等的。如果使用PUT多次提交只会影响相同的一条数据。
PUT VS PATCH PUT和PATCH都可以用来更新资源,但是PUT会更新所有资源,PATCH只会更新局部的资源。
如通过PUT更新
{
article = {
author:'day',
createTime:'2019-11',
content:'小王'
}
}
通过PATH更新
{
article = {
content:'小王'
}
}
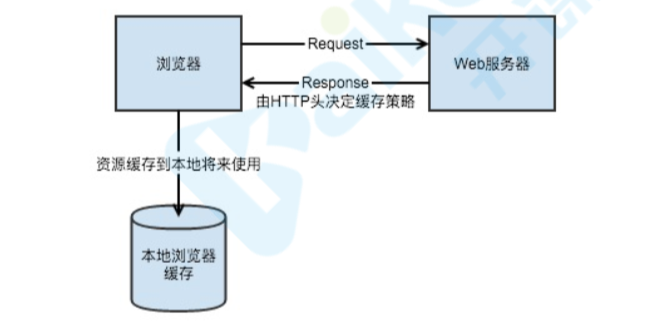
HTTP缓存过程?
过程
- 1 客户端向服务器发出请求,请求资源
- 2 服务器返回资源,并通过响应头决定缓存策略
- 3 客户端根据响应头的策略决定是否缓存资源,并将响应头与资源
- 4 在客户端再次请求且命中资源时,此时客户端去检查上次缓存的缓存策略,根据策略判断是直接读取本地缓存还是与服务器协商缓存。