

引言:更多相关请看 个人知识系列
概述
Apache Airflow
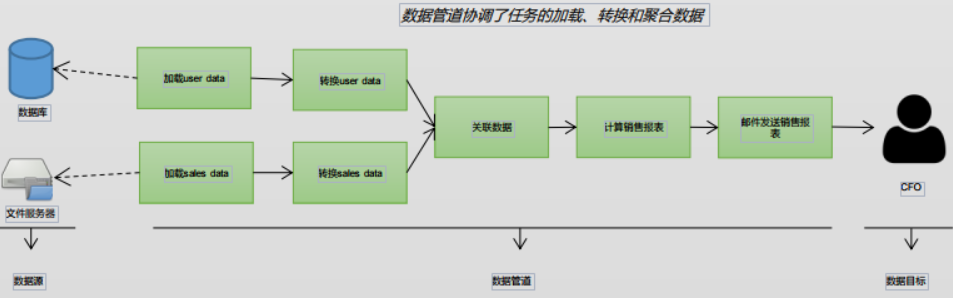
数据管道是指通过一系列步骤来完成某个数据处理任务的流程。想一下在ETL作业中,每天一次合并多个数据源并 计算汇总统计信息以用于报表。 有一些管道使用实时数据,而另一些管道通常使用批量数据。每种方法都有其自身的优点。Apache Airflow是一个用于以 编程方式开发和监控批量处理数据管道的平台。 Airflow提供了一个Python框架来开发由不同技术组成的数据管道。Airflow管道本身也以Python脚本进行编写,Airflow 框架提供了一组用于构建管道的小组件,而且小组件可与多种技术进行集成。 可将Airflow想象成管理数据管道的管家;他可以启动和停止在不同系统中或不同技术上运行的任务。
认识流程管理系统
许多数据管道由多个任务组成,这些任务必须按一定顺序执行,这些任务可以用一个流程图来定义: a.哪些任务组成了这个流程
b.这些任务按什么顺序执行
概括说,流程的定义包括两点:
1.一系列任务的定义,所有任务组成一个流程。
2.任务之间的依赖性
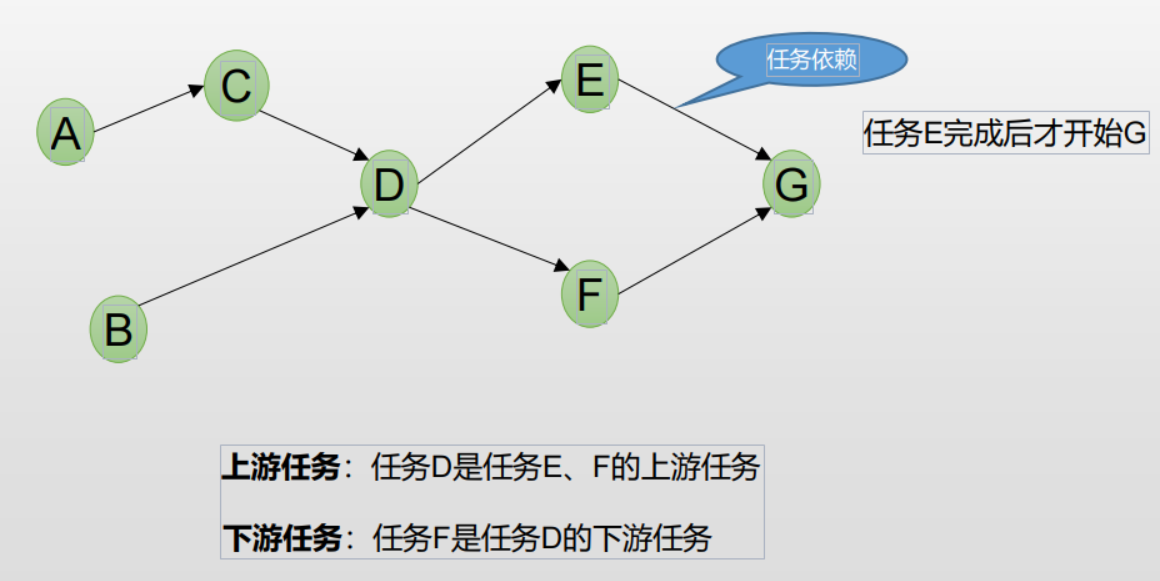
为了确定何时运行指定任务,流程管理系统需要知道在可以运行该任务之前需要执行哪些任务。任务之间的这种关系通常 称为任务依赖关系。 更复杂的数据流程,也是一个有向无环图,即DAG(Directed acyclic graph) 。 在Airflow里我们通过DAG来指代数据流程图。
常用数据流程管理工具的对比
| Oozie | Azkaban | Kettle | Airflow | |
|---|---|---|---|---|
| 起源 | Airbnb | |||
| Workflow定义方式 | XML | YAML | 图形界面 | Python代码 |
| 易用性 | 中 | 良 | 中 | 良 |
| 扩展性 | 中 | 良 | 良 | 优 |
| 稳定性 | 优 | 优 | 良 | 优 |
| 用户界面 | 依赖于Hue | 优 | 执行时无界面 | 优 |
| 调度功能 | 有 | 有 | 无 | 有 |
| 回填功能 | 无 | 无 | 无 | 有 |
| 开发语言 | Java | Java | Java | Python |
| 功能扩展性 | 差 | 差 | 中 | 优 |
| Github热度 | 419star | 2078star | 2064star | 9681star |
| 社区活跃度 | 差 | 中 | 中 | 优 |
关于历 史 和 现 状
比较精简的代码库,只有30K+行数的Python代码 。 诞生于Airbnb,15年 6月开源,现在是Apache的顶级孵化项目。 社区活跃 。 5年的开源项目,8872个提交,1148位贡献者,每周20+的提交。 有很多新兴互联网公司开始使用:Airbnb, Groupon, New Relic , PayPal, Reddit, Spotify, Tes la, Twitter, Google • 完成的有7000+ Pull Request。 国内也有很多公司开始评估和采用Airflow。
配置即代码
通常,数据流程编程可以分为两个阵营:以代码(例如 Python)配置的方法和以静态文件(例如XML)配置的方法。 Python代码允许使用for循环和其他编程结构生成动态而灵活的工 作流。另一方面,静态配置在这种意义上不太灵活,通常遵循严格 的架构。 配置为代码既可以是肯定的,也可以是否定的;代码的动态性 质可以为许多任务提供简洁的代码;但是,有无数种方法来定义代 码,因此,数据流程的定义也不太严格。
Airflow云服务(Google)
CLOUD COMPOSER特性:
多云端:创建跨云端连接数据、处理任务和服务的工作流,从而实现统一的数据环境。
混合式:通过编排跨本地和公有云的工作流,轻松过渡到云端或维护混合式数据环境。
Python编程语言:利用已有的Python技能在Cloud Composer中动态编写和安排工作流。
完全托管:Cloud Composer的托管特性使您可以专心编写、安排和监控工作流,而无需在资源的预配上费神。
开源:Cloud Composer基于Apache Air low构建而成, 可让用户避免供应商锁定问题并实现可移植性。
集成:内置集成了Big Query、Dataflow、Data proc、Datastore、Cloud Storage、Pub/Sub、Cloud ML Engine等诸多产品,让您能够编排端到端GCP工作负载。
可靠性:通过易于使用的图表来监控和排查问题的根本原因,提高工作流的可靠性。
架构
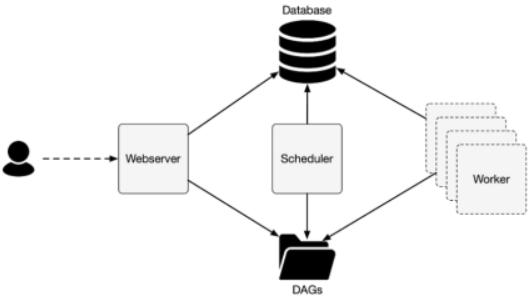
Airflow可以以多种架构方式运行,从High Level看,它包括三个组件:
1.Web服务器:向用户提供可视界面,以查看和管理数据流程的状态。
2.调度程序:调度程序负责解析DAG定义(读取DAG文件并提取有 用的片段),确定应启动的任务(调度/手动触发/回 填),并将任务发送给工作进程以执行。
3.工作进程:工作进程由调度程序在内部启动,真实执行任务的进程 。
在最简单的设置中,所有进程都在一台计算机上运行。如果单台计算 机达到资源极限,则Airflow可以在多台计算机上运行并扩展 。 Celery和Kubernetes支持分布式工作负 载 。 所有进程都需要访问数据库以存储元数据。需要对任务状态进行修改,储存DAG配置等。同样,所有进程都需要访问DAG文件。
日志:所有三种进程都会生成日志: Web服务器记录浏览器的活动,调度程序记录有关其正在执行的任务的各种信息,而工作进程记录其正在执行的任务。 日志可以存储在本地文件系统上,也可以配置为存储在其他位置。
安装
安装前提: a)C e n t O S > = 7 . 4 , 推荐7 . 8
b)python 3.6
c)docker19.03社区版
d)yum install需要有root权限的用户,下面的命令默认不带sudo,如果使用非root用户请自行加上sudo。pip、pipenv和docker-
compose都不要root权限
pip安装
a)安装 python3
yum install python3 python3-devel -y
b)安装 airflow 的依赖包(用于 python 包的编译)
yum install gcc
c)安装 pipenv
pip3 install pipenv --user
d)创建 python3 虚拟环境,创建一个目录 , 进入目录后执行
sudo -H pip install -U pipenv
mkdir -p /opt/module/airflow
cd /opt/module/airflow/
pipenv --three
pipenv shell #创建一个虚拟环境,可以退出
Launching subshell in virtual environment...
[root@slave1 airflow]# . /root/.local/share/virtualenvs/airflow-eDhhvR35/bin/activate
(airflow) [root@slave1 airflow]#
pipenv --python 3.6
cat /opt/module/airflow/Pipfile
[[source]]
name = "pypi"
url = "https://pypi.org/simple"
verify_ssl = true
[dev-packages]
[packages]
[requires]
python_version = "3.6"
e)安装 airflow
pip3 install apache-airflow==1.10.9
f)修复 SQLAlchemy 的兼容性问题
pip3 uninstall SQLAlchemy
pip3 install SQLAlchemy==1.3.15
g)airflow needs a home, ~/airflow is the default
export AIRFLOW_HOME=~/airflow
h)创建 airflow db
airflow initdb
i)启动 web server (窗口不要关掉)
airflow webserver -p 10099 & (后台执行)
j)启动 scheduler(另外起一个窗口)
airflow scheduler
docker-compose安装
a) 安装docker-compose工具: pip3 install docker-compose --user b) 下载docker-compose.yml 文件, 放在新建目录下
vim /opt/module/airflow/docker-compose.yml
version: '3.7'
services:
postgres:
image: postgres:9.6
environment:
- POSTGRES_USER=airflow
- POSTGRES_PASSWORD=airflow
- POSTGRES_DB=airflow
logging:
options:
max-size: 10m
max-file: "3"
webserver:
image: puckel/docker-airflow:1.10.9
restart: always
depends_on:
- postgres
environment:
- LOAD_EX=n
- EXECUTOR=Local
logging:
options:
max-size: 10m
max-file: "3"
volumes:
- ./dags:/usr/local/airflow/dags
# - ./plugins:/usr/local/airflow/plugins
ports:
- "8080:8080"
command: webserver
healthcheck:
test: ["CMD-SHELL", "[ -f /usr/local/airflow/airflow-webserver.pid ]"]
interval: 30s
timeout: 30s
retries: 3
c) 进入目录执行docker-compose up -d创建容器并启动, 第一次执行需要下载镜像会需要一点时间
注意:必须保证/opt/module/airflow下有/opt/module/airflow/docker-compose.yml配置文件。
cd /opt/module/airflow
docker-compose up -d 开启
docker-compose down 关闭
d) 容器启动成功后,检查用docker-compose ps,
[root@slave1 airflow]# docker-compose ps
/usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.22) or chardet (2.2.1) doesn't match a supported version!
RequestsDependencyWarning)
Name Command State Ports
---------------------------------------------------------------------------------------------------------------
airflow_postgres_1 docker-entrypoint.sh postgres Up 5432/tcp
airflow_webserver_1 /entrypoint.sh webserver Up (healthy) 5555/tcp, 0.0.0.0:8080->8080/tcp, 8793/tcp
查看日志用
docker-compose logs -f --tail 100 webserver
注意:这种方式启动是访问http://slave1:8080/ 8080端口。

访问
浏览器里打开http://<机器ip>:10099访问 。pip和docker-compose 如需修改配置,pip安装请修改目录下的airflow.cfg文件,然后重启服务。docker安装需要通过设置环境变量来修改配置。
执行器
Airflow内置4种执行模型: Sequential、Local、Celery、Mesos,扩展Dask(Python并行计算框架)和Kubernetes,执行模型很容易扩展出新的 。
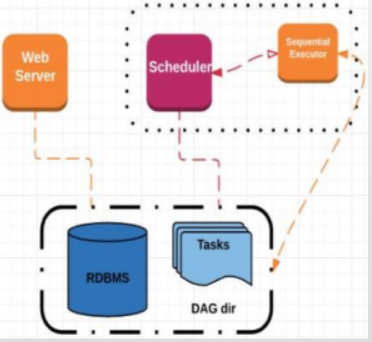
Sequential顺序执行器(默认)
最小配置,可以和sqlite使用
一次只能处理一个任务
只适用于演示
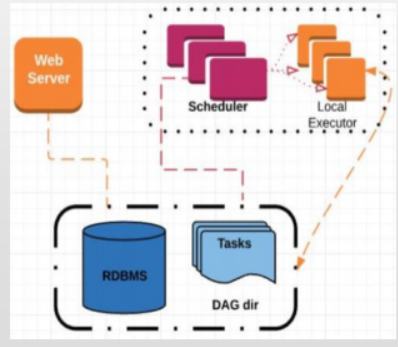
local本地
生成多个调度进程
可垂直扩展
可用于生产环境
无其他环境依赖,推荐新手使用
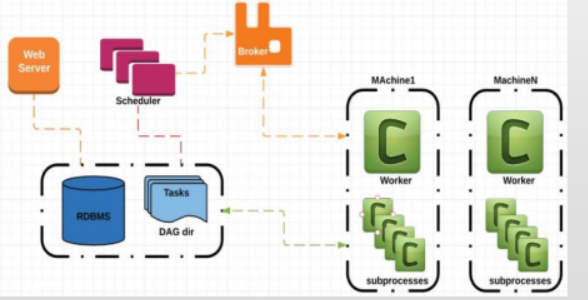
Celery执行器
可水平和垂直扩展,组件集群
可以通过Flower来监控
支持Pools和队列(如kafka)
部署稍麻烦,代码需要同步
可用于生产环境
Airflow CLI命令行管理工具 常用命令
backfill: 回填历史数据
run: 执行一个任务实例
list_dags: 列出所有的DAG
test: 测试一个任务实例,没有依赖检查
还有些其他命令,但是使用UI操作更加方便 .
Docker Airflow
• 使用Docker部署Airflow • magicwind.coding.net/p/bigdata-c… • 建议先使用Local Executor • 使用docker-compose exec webserver bash可 以 登 录 容 器 运行airflow cli
[root@slave1 airflow]# docker-compose exec webserver bash
/usr/lib/python2.7/site-packages/requests/__init__.py:91: RequestsDependencyWarning: urllib3 (1.22) or chardet (2.2.1) doesn't match a supported version!
RequestsDependencyWarning)
airflow@99d03cb247f0:~$ ls
airflow.cfg airflow-webserver.pid dags logs unittests.cfg
编写AirflowDAG
vim dags/tutorial.py
[root@slave1 airflow]# mkdir -p /opt/module/airflow/dags/sire/operators
[root@slave1 airflow]# vim /opt/module/airflow/dags/sire/operators/mysql2mysql_operators.py
chmod +x /opt/module/airflow/dags/sire/operators/mysql2mysql_operators.py
[root@slave1 dags]# chmod +x /opt/module/airflow/dags/tutorial.py
[root@slave1 dags]# chmod +x /opt/module/airflow/docker-compose.yml
核心术语
DAG:向无环图(DirectedAcyclicGraph),将所有需要运行的tasks按照依赖关系组织起来,描述的是所有tasks执行的顺序。 DagRun:DAG的一次运行,分为手动的和调度的两种。 Operator:可以以简单理解为一个class,描述了DAG中一个具体的task具体要做的事。其中,airflow内置了很多operators,如BashOperator执行一个bash命令,PythonOperator调用任意的Python函数,EmailOperator用于发送邮件,HTTPOperator用于发送HTTP请求,SqlOperator用于执行SQL命令…同时,用户可以自定义Operator,这给用户提供了极大的便利性。 Task:Task是Operator的一个实例,也就是DAGs中的一个node。 TaskInstance:task的一次运行。taskinstance状态包括“running”,“success”,“failed”,“skipped”,“upforretry”等。 TaskRelationships:DAGs中的不同Tasks之间可以有依赖关系,如TaskA>>TaskB,表明TaskB依赖于TaskA。 通过将DAGs和Operators结合起来,用户就可以创建各种复杂的workflow了。
Airflow对象之间的关系
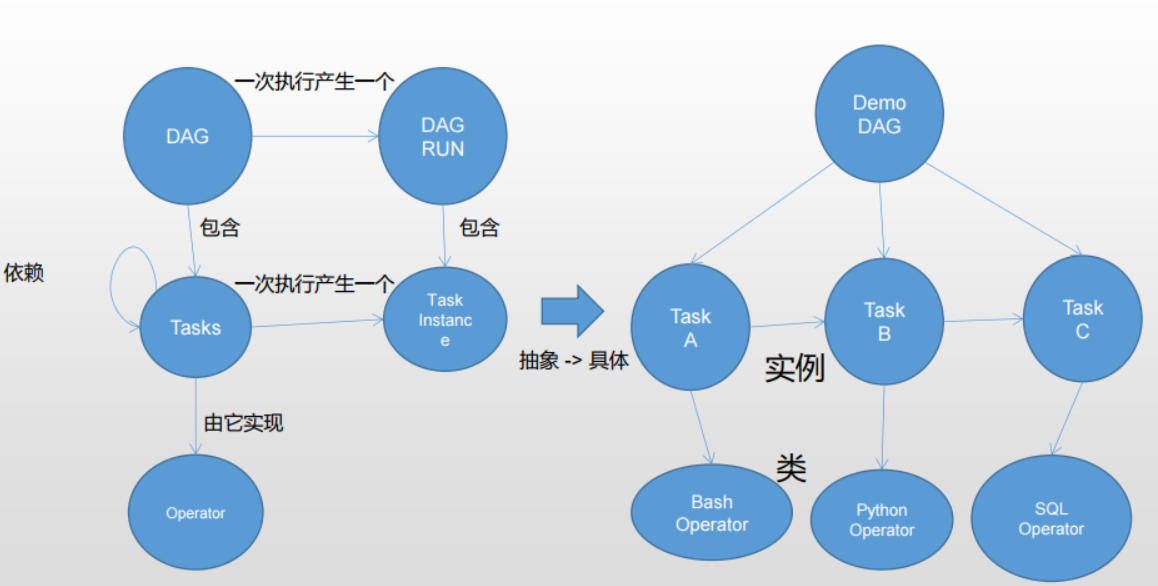
DAG
运行一个DAG:schedule定时或者manual手动。 DAG在指定时间执行–通过设置scheduleinterval。 处理失败的任务(Task):DAGGraphView里点击Task操作对话框->点击Clear按钮
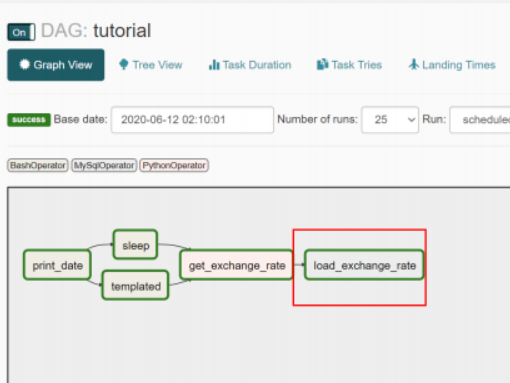
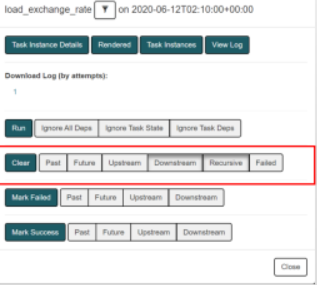
调度
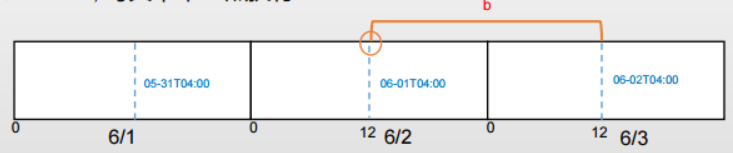
三种调度方式: 1.内置的固定间隔的调度:None,@once,@hourly,@daily,@weekly,@monthly,@yearly 2.(推荐)基于Cron的灵活的调度:分 时 日 月 年,比如0 0 * * * 3.基于指定频率的调度:timedelta(days=3) 增量处理任务:动态获取executiondate,然后传入task
理解ExecutionDate 使用回填功能(仅支持命令行)
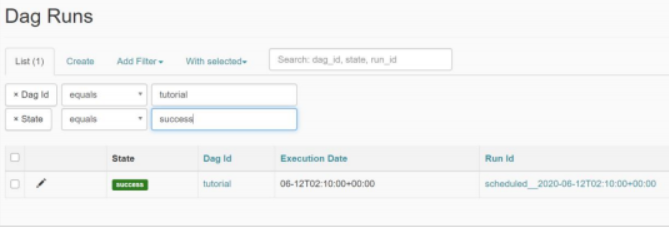
时区问题
数据库里默认储存的是UTC时间,界面上显示的也是UTC时间(见下面的截图)。支持时区设置,默认的时区可以通过airflow.cfg配置修改。DAG也分为时区敏感的和不敏感的,构建时区感知的DAG,需要在构建DAG时将时区信息传入,之后就可以按照指定时区的时间来调度任务了;时区不敏感的DAG,默认按照UTC时间来调度。
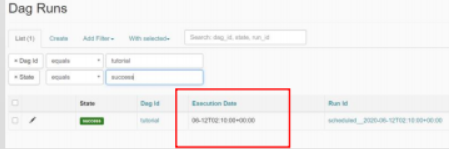
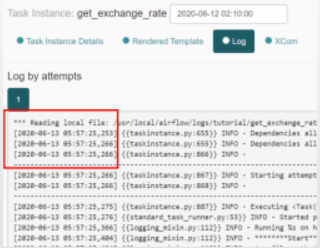
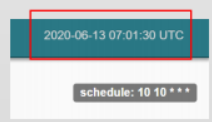
Execution Date
DAG设置为中国时区 一日一次: 0 6 * * *, 每天早上6点执行

一日一次: 0 12 * * *, 每天中午12点执行
一日两次: 0 6,12 * * *, 每天早上6点和中午12点执行
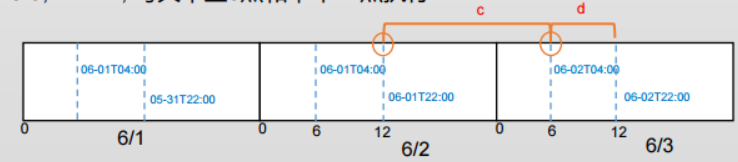
扩展
Operator内置和自定义
1.Default Variables和 Macro {{ ds }}, {{ yesterday_ds }}, {{ tomorrow_ds }}
{{ ds_add(ds, days) }} 2.模版参数和模版文件:Jinja模版 3.MySqlOperator 4.扩展Operator在 contrib里 5.自定义Operator: MySQLToMySQLOperator
其它常用术语
Variable:提供通用的、用户可以自定义的变量存储和获取功能,可在UI上操作。 Connection:管理外部系统的连接信息,如外部MySQL、HTTP服务等,连接信息包括conn_id/hostname/login/password/schema等,可以通过界面查看和管理,编排workflow时,使用conn_id进行使用。可在UI上操作。 Pool:用来控制tasks执行的并行数。将一个task赋给一个指定的pool,并且指明priority_weight,可以干涉tasks的执行顺序。可在UI上操作。

Xcoms:在airflow中,operator一般(notalways)是原子的,也就是说,他们一般独立执行,同时也不需要和其他operator共享信息,如果两个operators需要共享信息,如filename之类的,推荐将这两个operators组合成一个operator。如果实在不能避免,则可以使用XComs(cross-communication)来实现。XComs用来在不同tasks之间交换信息。 Hook:访问各种数据源的钩子,被Operator所使用。 TriggerRule:指task的触发条件。默认情况下是task的直接上游执行成功后开始执行,airflow允许更复杂的依赖设置,包括all_success(所有的父节点执行成功),all_failed(所有父节点处于failed或upstream_failed状态),all_done(所有父节点执行完成),one_failed(一旦有一个父节点执行失败就触发,不必等所有父节点执行完成),one_success(一旦有一个父节点执行成功就触发,不必等所有父节点执行完成),dummy(依赖关系只是用来查看的,可以任意触发)。另外,airflow提供了depends_on_past,设置为True时,只有上一次调度成功了,才可以触发。 SubDAG:DAG可以嵌套。
Best Practice
注意DAG代码规范
使用Connection管理密码
使用Variable管理配置
DAG的定义尽量简单,避免复杂逻辑使用代码来动态生成Task
不要一次性处理大量数据
不要把文件储存在本地文件系统上
使用Pool来管理任务的并发
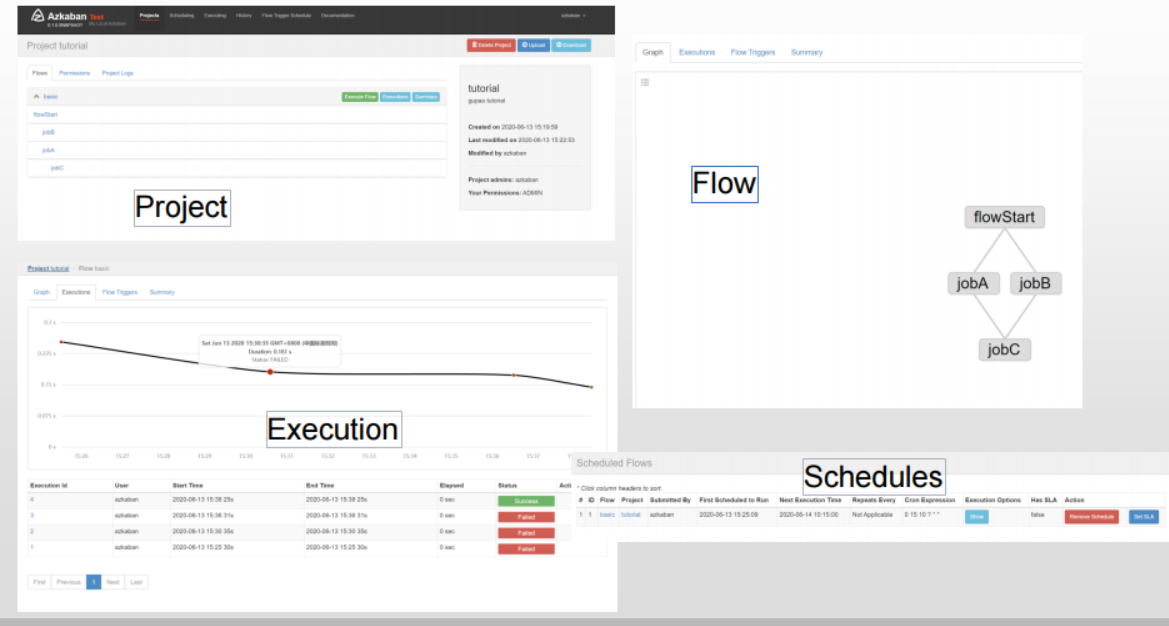
Azkaban
部署
JDK 单节点(测试,低负载) 多节点(高可用,生产) 以项目、Flow和Job三级结构进行管理 代码yaml是配置文件,打包成zip文件后在Web管理界面里上传支持手工调度、定时调度和任务依赖管理 界面友好,比较好上手
job type
Command, HadoopShell
Java, javaprocess, hadoopJava Hive
