写在前面:该算法
- 目的是在HUI-Miner算法的基础上提高效率,关键在于两个新上界:revised sub-tree utility、local utility来压缩高效检索空间。
- 并且通过快速效用值计算算法FAC(Fast Utility Counting)来在线性时间内获取上界值和检索空间。
- 更进一步,通过HDP(High-utility Database Projection)和HTM(High-utility Transaction Merging)在线性时间内完成对数据库的映射和事务归并。
EFIM: A Fast and Memory Efficient Algorithm for High-Utility Itemset Mining
样例



定义
HUI-Miner算法
-
p(i):i是项,p(i)是外部效用值,代表着该项对用户的相对重要性,也可以看作是该项的利润
-
q(i,Tc):是内部效用值,也可以看作是该项i的交易数量
-
u(i,Tc):是在某个事务T中的项i所产生的总利润,即 u(i,Tc)=p(i)∗q(i,Tc)
-
u(X,Tc):是项集X在某个事务T中所产生总利润和,即 u(X,Tc)=∑i∈Xu(i,Tc)∪[X⊆Tc⇒u(X,Tc)=0]。例如项集 u({a,c},T2)=u(a,T2)+u(c,T2)=5×2+1×6=16
-
g(X):是包含项集X的事务集,投影映射 g:2t→2D,g(X)={t∈D∣∀i∈X,i∈t},称g(x)为项集 X⊆I 的支持集
-
u(X):找出所有包含项集X的事务集T,求项集X在这些事务T可以产生的总利润和,即 u(X)=∑Tc∈g(X)u(X,Tc)。例如项集 u({a,c})=u({a,c},T1)+u({a,c},T2)+u({a,c},T3)=28
-
tu(Tc):求某个事务T内所有项集X的总利润和,即 tu(Tc)=∑X⊆Tcu(X,Tc)
-
twu(X):求包含项集X的所有事务T的总利润和,即 twu(X)=∑X⊆T∪Tc⊆Tu(X,Tc)
定理:
twu(X)≥u(X)、twu(X)≥u(Y)[∀X⊂Y](TWU具备反单调性)故当twu(X) < minutil,则直接忽略项集X的超集Y
证明:
twu(X)=∑Tc∈g(X)tu(Tc)=∑Tc∈g(X)∑x∈Tcu(x,Tc)
u(X)=∑Tc∈g(X)u(X,Tc)=∑Tc∈g(X)∑x∈Xu(x,Tc)
这两个推导式看起来好像一样,但在最终 “x” 的所属范畴确是这两者间的最大差别,显然 X 是 Tc 的子集,自然上式成立
当 项集X 是 项集Y 的子集时,X 内的项数量小于 Y,但 twu(X) 计算的是那些包含 整个项集X 的事务项的总效用值,随着项集X的规模扩大,能够符合twu计算条件的 事务项 就越少,故有 twu(X) >= twu(Y) >= u(Y)
-
re(X,Tc):是在各事务项中 大于 项集X的所有项的效用值之和,即 ∑i∈Tc∧i≻x∧∀x∈Xu(i,Tc)
-
效用表(Utility-list)构成:(Tc,iutil[u(X,Tc)],rutil[re(X,Tc)])
-
剩余效用边界(remaining utility upper-bound):这个概念是区别于“两步走”算法的关键之处,因为这个边界值比 TWU 是更为紧凑,能够裁剪更精细。定义为 reu(X)=re(X)+u(X)
定理:
如果reu(X)<minutil,则项集X和它的超集都是低效用值项集
证明:
设项集X和它的超集Y,事务项T,其中有关系 X⊂Y⊆T⇒(Y∖X)⊆(T∖X)当把所有包含项集X的事务项都计算起来,自然可知当 reu(X) < minUtil,那么超集必然也小于,那么
u(Y,T)=u(X,T)+u(Y∖X,T)=u(X,T)+∑i∈(Y∖X)u(i,T)
≤u(X,T)+∑i(∈T∖X)u(i,T)=u(X,T)+re(X,T)=reu(X,T)
Ps. 结合上面的定义9也可以看出来,其实 Y\X 就是所有大于项(集)X的项组成的剩余项集
EFI-Ming算法
-
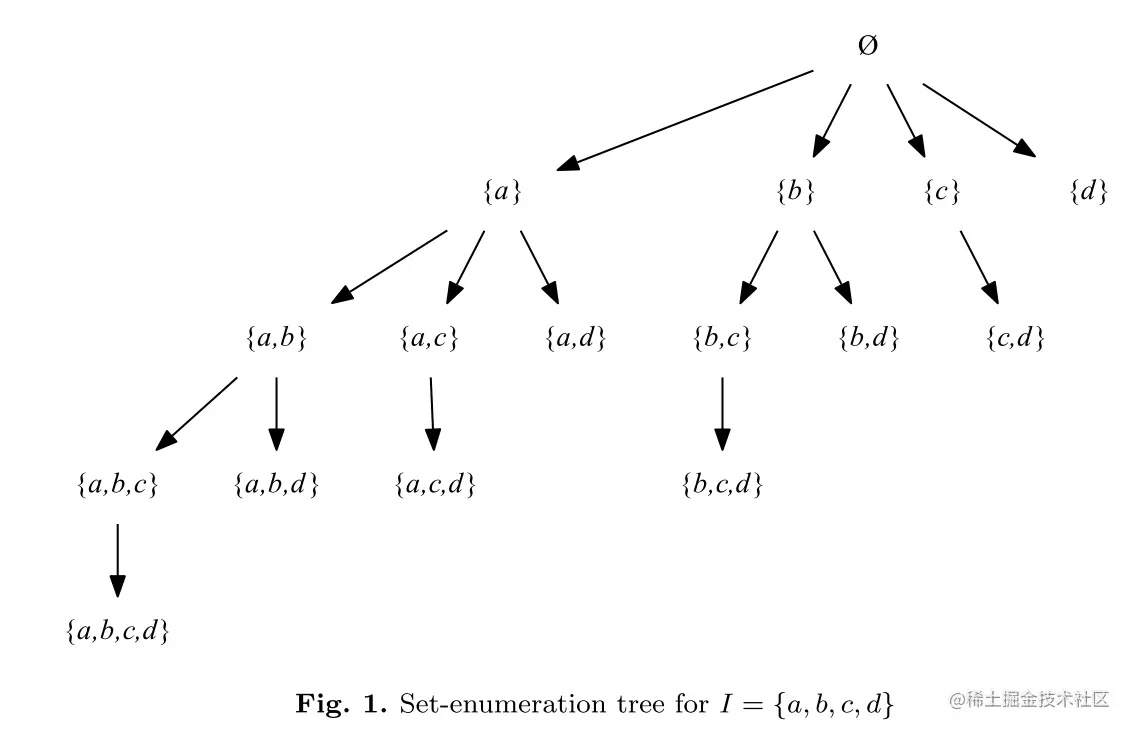
E(α):表示根据深度优先搜索遍历所有项,得到大于 α 的所有项集,有E(α)={z∣z∈I∧z≻x,∀x∈α},如Fig.1,设 α={c},则 E(α)={a,b,d}
-
扩展项集(Extension of an itemset):设项集 Z 是项集α的扩展,若 Z=α∪W 且W∈2E(α),则有W=∅且 Z 是项集α的子树和枚举树
-
一元扩展项集(Single-item extension of an itemset):设项集Z是项集α的一元扩展,若Z=α∪W,则Z是项集α的子树和枚举树
Ps.例子:假设α={d},E(α)={e,f,g},那么一元扩展项集就是 {d,e}、{d,f}、{d,g},多元扩展集为 {d,e,f}、{d,f,g}、{d,e,f,g}
-
映射事务(Projected transaction):由 α-T={i∣i∈T∧i∈E(α)}表示,其中T是事务项,α是项集,E(α)是扩展项集(处理一行事务项,也就是该事务项排在项集α的之后的项组成的新的事务项)
-
映射数据库(Projected database):由 α-D={α-T∣T∈D∧α-T=∅}表示,其中D是数据库,α是项集,T是事务表(处理多行事务项,也就是对整个事务表进行映射事务处理,组成一个新的数据库)
Ps. 当某交易项不包含指定的项集α,那么在映射过程中会删除这个交易项
-
相同的事务(Indentical transaction):当 Ta、Tb 两个交易项的所有的项元素都相同时,我们认为事务项Ta和事务Tb是相同的事务
-
归并事务(Transaction merging):当在数据库D中存在相同的事务项Tr1、Tr2…Trm时,我们设置一个新的事务TM来替代这些,且每项 i∈TM 都被定义为 q(i,TM)=∑k=1…mq(i,Trk)
-
映射归并交易(Projected transaction merging):在映射数据库 α-D 中,将所有重复的事务项 Tr1、Tr2、…Trm用一个新的事务项 TM 来替代,且每项 i∈TM 都被定义为 q(i,TM)=∑k=1…mq(i,Trk)
-
交易项总顺序(Total order on transactions):我们用 ≻T 来表示,有以下四种情况则判定成立:
- Tb 的TID全都大于 Ta 的TID,则Tb≻Ta
- 当 k>m 且 im−x=jk−x 且对 ∀x∈Z,0≤x<m,则 Tb≻TTa
- 当 ∃x 且 0≤x<y<min(m,k),有 jk−x≻im−y 和 im−y=jk−y 成立,则 Tb≻TTa
- 其它情况是 Ta≻TTb
-
第一阶梯项(Primary items):设存在项集 α,那么有 Primary(α)={z∣z∈E(α)∧su(α,z)≥minuti}
-
第二阶梯项(Secondary items):设存在项集 α,那么有 Secondary(α)={z∣z∈E(α)∧lu(α,z)≥minutil}
-
修正子树效用值(Redefined Sub-tree utility):设存在项集 α 和项 z,重新定义的 su(α,z)=∑T∈g(α∪{z})[u(α,T)+u(z,T)+∑i∈T∧i∈E(α∪{z}∧i∈Secondary(α))u(i,T)]
Ps.因为有 lu(α,z)≥su(α,z),所以 Primary(α)⊆Secondary(α),意味着只需检索以 Primary(α) 中的子项集与 α 的并集为根结点的子树,且其它项集不做考虑。例如项 α = {a},Primary(α) = {c, e},Secondary(α) = {c, d, e},这意味着对于项集 α,我们只要检索以 α∪{c} 和 α∪{e} 为根节点的子枚举树,并且在这两个枚举树中,除了项c、d、e,其它的项都不考虑
四个关键点
- 需要设计一种单一算法来避免因产生候选项集问题-Utility List
- 通过使用“模式增长方法”来避免多花时间去考虑数据库中那些可能不会出现的模式,而且算法要减少对数据库的扫描-HDP & HTM
- 通过设计一个紧凑的上界来缩小检索空间,且这个上限应该比当下算法中通过保留有效上界更紧凑-local utility & revised sub-tree utility
- 算法在时间和空间上的操作都要尽可能地简单-FUC
HDP(High-utility Database Projection)
采用该技术的目的是通过某个项来投影出更小的数据库,达到减少扫描量的效果
原理:
当一个项集α出现在深度优先遍历结果中,存在项集x∈/E(α)时,通过扫描数据库在α的子树或效用值上界中,可以不用计算这些项集x的效用值。我们称这种删除后的数据库为投影数据库(projected database),同理还有投影事务(projected transaction)
方法:
- 按照“≻”关系对源数据库的每个交易项目进行升序排序
- 每个投影事务由对应的源交易上的偏移指针来表示,也称为伪投影
HTM(High-utility Transaction Merging)
采用该技术的目的通过减小数据库规模来减少对数据库扫描的开销
原理:
交易数据库中常常包含重复的交易信息(Identical transaction),本技术需要找出这些相同的交易信息,然后在梳理它们效用值得过程中只保留一条交易信息
方法:
- 找出相同的交易信息(Identical transaction),进行归并处理,用一个新的交易项 TM 来代表这些重复的
- 对映射数据库做同样的处理,称为映射归并交易(Projected transaction merging)
- 最后得出交易总订单(Total order on transaction),这之间的交易项集是按序从小到大排列
Ps.以上两个技术是配套使用的:“归并 -> 投影 -> 归并 -> 投影 -> ...”,一边通过归并使得共同前缀不断增长(上界),一边投影事务表(缩小,因为有共同前缀,那么前缀就可以暂时不考虑)
排序≻T
其实在每次投影开始前,都要对交易表进行交易项排序,这样是在一定程度上提高投影和归并效率,不必重复扫描数据项
排序判定有以下四个标准,我们设有交易项 Ta={i1,⋯,im},Tb={j1,⋯,jk}:
-
当 m=k,∀x∈[0,m∣k],有 ix=jx,但是 b > a,则 Tb≻TTa(翻译一下就是从后往前依次对比两个交易项的各项元素,发现两个交易项一模一样,差别就是交易项b的角标数字大于交易项a,所以交易项b大于交易项a)
-
当 ∀x∈[0,m),若 k>m,im−x=jk−x,则 Tb≻TTa(翻译一下就是从后往前依次对比两个交易项的各项元素都相等,但交易项a没交易项b长,所以交易项b大于交易项a)
-
当 ∀x∈[x,min(m,k)),y∈(x,min(m,k)),有 im−y=jk−y,jk−x≻im−x,则 Tb≻TTa(翻译一下就是从后往前依次对比两个交易项的各项元素,发现比到一个位置n这两个项元素有 jn≻in,所以交易项b大于交易项a,类似于比较字符串字串大小一样)
-
其它情况统统设定为 Ta≻TTb
以下两个概念是定义了新的上边界值,不同于 Remain Utility 和 Transaction Weighted Utilization 这两个上边界值,他们分别是在搜索枚举树中的项目集α的子树中定义的,时刻动态变化的上界值,而不是像twu这样的定值,所以新提出的上界值会更紧凑,对检索空间的有效删减程度更大
Local utility
定义:
设项集 α 和项 z∈E(α),有 lu(α,z)=∑T∈g(α∪{z})[u(α,T)+re(α,T)],例如:设 α={a},则有 lu(α,c)=(8+27+30),lu(α,d)=30,lu(α,e)=57(通过观察Table 1,你会发现 lu(a,c)=TU(T1)+TU(T2)+TU(T3),当然这只适用于排在第一位的项,比如对于项 {c} 就不是这样的了,有没有对 {c} 计算更简便的方法,利用前面已经算出来的值?)
定理:
设存在项集 α 和项 z∈E(α),且有 z∈Z,其中 Z 是 α 的扩展集,对于 lu(α,z)≥u(Z) 仍然成立,故当 lu(α,z)<minutil 时,在项集 α 的扩展项集中所有包含项 z 的项集都是低效用值,简而言之就是在遍历 α 的子树中,可以忽略掉项 z 和项集 α 为根节点的子树
证明:
设 项集 Y = α ∪ {z},项集Z 的效用值定义为 u(Z)=∑Tc∈g(Z)u(Z,Tc)=∑Tc∈g(Z)[u(α,Tc)+u(Z∖α,Tc)],那么项集α 的局部效用值(local utility)就为 lu(α,z)=∑Tc∈g(Y)[u(α,Tc)+re(α,Tc)](这个公式是不是很像 reu = iutils + rutils???)。原因在于 g(Z)⊆g(Y) 且 Z∖Y⊆E(α),故必有 u(Z∖α,Tc)≤re(α,Tc)、u(Z)≤lu(α,z)
Ps. 其实这部分证明只要对着上图中的枚举树(图Fig. 1.),把上述公式套进去就很容易看出来
Sub-tree utility
定义:
设有一个项集 α 且有一个项 z 可以对 α 通过深度优先遍历进行扩展,其中 z∈E(α),那么有 su(α,z)=∑T∈g(α∪{z})[u(α,T)+u(z,T)+∑i∈T∧i∈E(α∪{z})u(i,T)],例如:设 α = {a},则有
su(\alpha, c) = \\ [u(a, T_1) + u(c, T_1) + u(d, T_1)] + \\ [u(a, T_2) + u(c, T_2) + u(e, T_2) + u(g, T_2)] + \\ [u(a, T_3) + u(c, T_3) + u(d, T_3) + u(e, T_3) + u(f, T_3)] \\ = 61
su(α,d)=25,su(α,e)=34
定理:
1.设存在项集 α 和项 z∈E(α),对于 su(α,z)≥u(α∪{z}) 仍然成立,并且有 su(α,z)≥Z∧Z⊆α∪{z},故当 su(α,z)<minutil 时,在一元项集 α∪{z} 和它的扩展集都是低效用值,简而言之可以剪去枚举树中的 α∪{z} 子树
2.设存在项集 α、Y=α∪{z} 和项 z,则存在不等式 twu(Y)≥lu(α,z)≥reu(Y)=su(α,z)
证明:
1.设项集 Y = α ∪ {z},那么
u(Y)=Tc∈g(Y)∑u(Y,Tc),su(α,z)=Tc∈g(Y)∑[u(α,Tc)+u(z,Tc)+i∈Tc∧i∈E(α∪{z})∑u(i,Tc)]=Tc∈g(Y)∑u(Y,Tc)+Tc∈g(Y)∑i∈T∧∈E(α∪{z})∑u(i,Tc)≥Tc∈g(Y)∑u(Y,Tc)=u(Y)
2.设项集Z是项集Y的扩展,那么 u(Z)=∑Tc∈g(Z)u(Y,Tc)+∑Tc∈g(Z)u(Z∖Y,Tc),因为有 g(Z)⊆g(Y),Z∖Y⊆E(α),故有 su(α,z)≥u(Z)
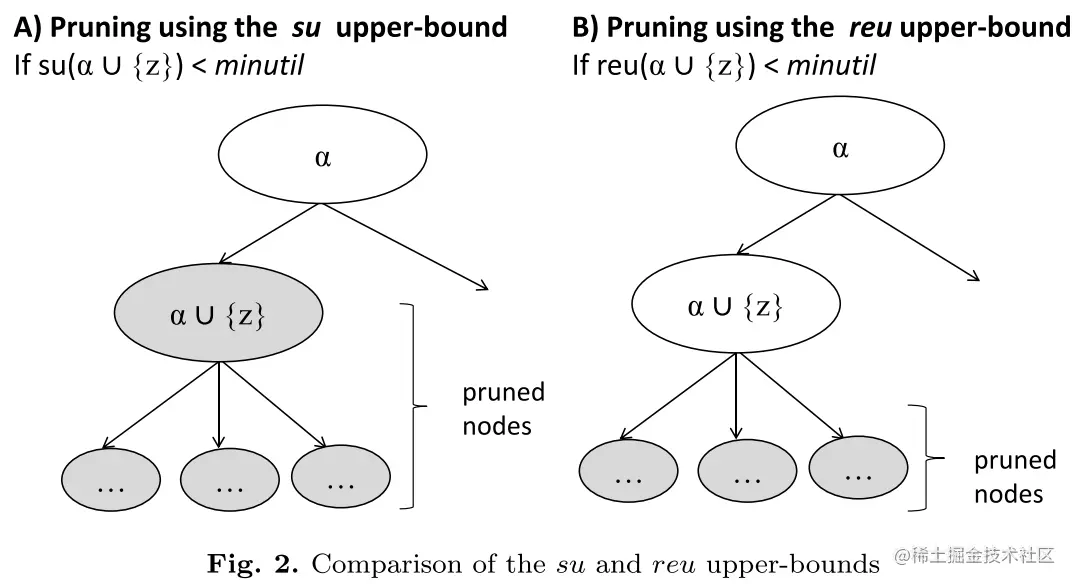
下图表示EFI-Ming算法的裁剪优势:
FUC(Fast Utility Counting)
采用该剪枝技术的目的是通过一种数组结构(utility-bin)在线性时间和空间内计算出上界
定义:
效用箱(utility-bin):设 I 是数据库中的一个项集,效用箱数组 U 的长度为length(I),在数组 U 中每项表示为 U[z](z∈I),数组内存储的是效用值,效用箱数组通常是用来在O(n)时间复杂度内去高效计算上界值
使用:
-
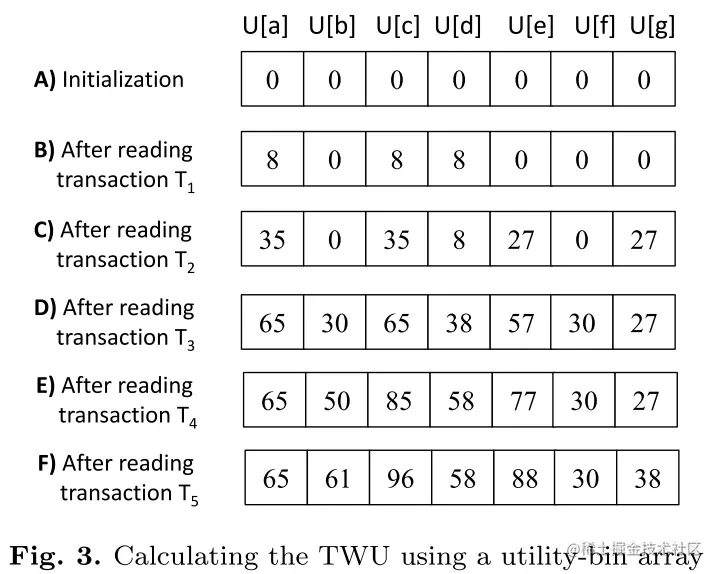
利用utility-bin计算twu(X),有公式 U[z]=U[z]+tu(T),其中 z∈T,在处理完最后一个事务时,对于 ∀i∈I,twu(i)=U[i]
下图是个示例:
-
利用utility-bin计算su(α,Tj),对于项集 α,
有公式 U[z]=U[z]+u(α,Tj)+u(z,Tj)+∑i∈Tj∧i≻z∧i∈Secondary(α)u(i,Tj),其中 z∈Tj∧E(α),在处理完最后一个事务时,对于 ∀i∈E(α),U[i]=su(α,i)
-
利用utility-bin计算lu(α,Tj),对于项集 α,有公式 U[z]=U[z]+u(α,Tj)+re(α,Tj),其中 z∈Tj∧E(α),在处理完最后一个事务时,对于 ∀i∈E(α),U[i]=lu(α,i)
关键算法实现


个人总结
花了很长时间去研究这个算法,不得不说很多地方设计得很精彩,例如使用utility-bin来使得twu的计算控制在线性范畴内,local utility和sub-tree utility能得出更紧凑的上界。思路可以认为是先构造一元项的枚举树,这里是第一次缩减检索空间;然后围绕枚举树,开始对事务表进行操作;通过检查出的共同前缀,来进进一步对枚举树进行删减,这是第二次缩减检索空间;利用共同前缀,对项e进行一个个扩展(增长模式法),留下符合的项集并输出,删除不符合条件的;重复进行以上过程最终枚举树无法延伸即可结束。在这个过程中还有各种参数的转换、留存,详情可见代码。
参考
- EFIM算法演示教程-www.philippe-fournier-viger.com/spmf/EFIM.p…
- EFIM: A Fast and Memory Efficient Algorithm for High-Utility Itemset Mining-philippe-fournier-viger.com/EFIM_JOURNA… KAIS 2016.pdf
- EFIM原作的ppt-www.philippe-fournier-viger.com/EFIM_and_EF…


