

ARTS是什么?
Algorithm:每周至少做一个leetcode的算法题;
Review:阅读并点评至少一篇英文技术文章;
Tip:学习至少一个技术技巧;
Share:分享一篇有观点和思考的技术文章。
Algorithm
题目解析:
这两道题目都是围绕着 H-Index 来展开的,因此在解题前需要了解下这个概念。H-Index 是通过论文的引用次数来反映一个学者的影响力的。H-Index 的定义为,“如果一个人所发表的论文中有 h 篇文章的被引用次数高于 h,剩下的 N - h 篇的文章的被引用次数都不高于 h,那么这个人的 H-Index 就是 h”,这道题目输入的是一堆论文的引用次数,然后让你求出 H-Index,可能有多个符合条件的 H-Index,求出最大的那个即可。I 和 II 的区别仅仅是输入的数组是否排好序。
如果是第一次来做这道题,可能会被定义弄得有点理不清头绪。主要是这里的 h 把引用次数和文章的个数弄在了一起。不管怎么样,我们要先知道所要求的 h 的范围是什么,很明显 h 不可能为负,另外 h 和文章数量挂钩,所以 h 的最大值就是文章的个数,于是 h 的范围就是 [0, n]。剩下的问题就是如何得到 h,由于两道题目的输入条件是不一样的,我们可以采取不一样的策略,分别来看看。
对于第一道题来说,因为输入数组未排序,我们必须通过遍历求解。我们要找到 h 篇文章,这 h 篇的文章的引用要足够高,每篇文章的引用次数都要高于或等于 h,之前我们说到 h 的范围是 [0, n],那么如果一篇文章的引用次数大于 n,那么这篇文章是肯定可以归入这 h 篇文章之中的,也就是说不管文章的引用是 2n, 3n 还是 4n,对计算 h 都没有任何的区别,因此我们可以把大于 n 的文章归为一类,但如果文章的引用在 [0, n] 之间,那就会有区别,如果我们分别统计出文章的引用在 [0, n] 上的个数,然后倒着遍历,不断累加文章的个数,只要发现累加的文章个数大于当前文章的引用,我们就输出当前的引用,因为是倒着遍历,往前还没遍历到的文章的引用个数也小于当前的累加的文章数,说的可能有点绕,具体可以看代码注释。
第二题,因为数组是排好序的,这样其实更简单,我们都不用计数了,每到一个位置,我们都可以知道比当前文章的引用多的文章个数,如果比当前文章的引用多的文章的个数大于当前文章的引用,那么比当前文章的引用多的文章个数就是 h,我们需要尽可能找到大的 h。这个可以很好地用二分法来实现,就是用二分法去找边界条件。用 O(lgn) 的时间就可以完成。
参考代码(274):
func hIndex(citations []int) int {
n := len(citations)
// 最后一个位置用于存放引用数大于 n 的文章
counts := make([]int, n + 1)
// 计数排序
for i := 0; i < n; i++ {
if citations[i] >= n {
counts[n]++
} else {
counts[citations[i]]++
}
}
// sum 表示此时的文章个数
sum := 0
// 从后往前遍历
// i 表示的是 i 个引用,i == n 表示的是 > n 个引用
// counts[i] 表示的是文章数,除 n 以外,这些文章都有且仅有 i 个引用
for i := n; i >= 0; i-- {
sum += counts[i]
// 如果引用大于等于 i 的文章的总数大于 i
// 那么 i 就是我们要找的 h
// 找到就返回,这样我们得到的就是最大的 h
if sum >= i {
return i
}
}
return 0
}
参考代码(275):
func hIndex(citations []int) int {
if len(citations) == 0 {
return 0
}
start, end, n := 0, len(citations) - 1, len(citations)
for start + 1 < end {
mid := start + (end - start) / 2
// n - mid 表示的大于等于当前文章引用的文章数
// 如果 n - mid 小于或等于当前文章引用
// 那说明当前文章也可以算作到 h 篇文章之中
// 我们要让 n - mid 尽量的大,mid 尽量的小
if n - mid <= citations[mid] {
end = mid
} else {
start = mid
}
}
if n - start <= citations[start] {
return n - start
}
if n - end <= citations[end] {
return n - end
}
return 0
}
Review
Six programming paradigms that will change how you think about coding
这篇文章主要讲述了六中不太常见的编程范式,然后每个编程范式中给出了一些不常见的编程语言。作者之所以写出来一是觉得有趣,因为这些编程语言的设计理念相比于当代流行的编程语言来说有很大的区别,但是这些设计看似又十分巧妙,看完不仅让人感叹,原来还有这样的编程语言;二是觉得这些东西非常有借鉴意义,或者说其背后的一些思想能够改变对编程的单一化的认识,来分别看看这几个编程范式:
-
Concurrent by default(默认支持并发)
如果一门语言每行代码并不是按着行号顺序执行,而是每行同时执行会发生什么?刚看到这个,我想起了之前学的电路设计类语言,比如 VHDL,Verilog,之所以这些语言设计成默认支持并发是因为这些语言直接跟硬件打交道,因为每行代码定义的其实是电路上的一个组件,电路上的组件和状态是同时存在的。但如果一门正常的编程语言如果默认支持并发,一个首要考虑的问题就是 “如果变量之间有相互依赖怎么办?” 文章中的例子语言(ANI)会根据依赖关系来运行代码,先运行那些没有依赖的代码块(想起了算法中的拓扑排序。。。)。但是无论怎么说,并发下的程序都要额外考虑很多问题,比如共享资源,操作的先后顺序等等,并发不利于人理解还提升了程序出错的风险,但其优势也是很明显的,那就是运行效率能够在很大程度上得到提升。这种编程范式需要考虑并解决的问题就是 “如果默认支持并发,是否能让并发更容易被管理?”
-
Dependent types(类型依赖)
目前流行的语言基本上分为两种,类似于 Python 这样的动态语言,和类似 Java 和 C++ 这样的静态编译型语言,对于后者来说更稳定些,因为在运行程序之前,编译器会帮助你进行语法检查,这样就大大降低了程序在运行时出错的概率。但是你有没有想过这些运行前的语法检测具体检测什么?基本上会检测类型定义和使用是否符合规定,比如说在 Java 中下面的定义就是不符合规范的
int a = 9.0;但这里想强调的是这些规则和语法检测的逻辑都是定义在编译器里的,你是没有办法改变的。假如说现在有一门语言,你可以定义并改变编译器的语法检测逻辑,让其去根据你的需要进行检测,比如说规定一个变量必须是正数,两个进行相加操作的数组中的元素个数必须相同。在这种模式下,通过恰当的前期操作,我们可以更容易地找出程序中出现的漏洞,大幅度降低程序在运行时出错的概率。这类语言都是基于类型的,类型在这类语言中有统治的地位,也许在不远的将来,类型依赖这样的思想可以在静态类型系统中大放光彩。
-
Concatenative languages(连接型语言)
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
计算机科学当中最难的两件事 - 让缓存失效和命名,前者我们先不考虑,对于后者你是不是深有体会?有没有想过如何解决这个千古难题?如果现在有一门不需要给变量命名的编程语言,你是不是会觉得不可思议?文章中给了 CAT 语言的一个例子:
2 3 +上面的语句是将 2 和 3 相加。这类语言的实现主要是运用了栈和一些默认的逻辑,比如说 if-else 在 CAT 中就是这样实现的:
10 < [ 0 ] [ 42 ] if你可以看到这类语言都是靠一个个小模块拼接而成,模块之中可以继续套模块,这种语言的模块重用率会很高,代码也会变得非常简洁。虽然说我们可以不用通过查看变量名来得知当前程序运行状态,但是我们还是得通过栈的情况来推断一些程序的基本信息,要知道的是,这些栈状态相比于直白的文字,可没那么好让人理解。
-
Declarative programming(声明式编程)
相对来说,应用这类编程范式的语言我们应该会比较熟悉。比如 HTML,SQL,但我们却不常知道这类编程范式本身。相比于普通的编程(命令式的编程),这类编程范式会更加的直接,想要得到某个结果,我们并不需要实现具体的逻辑和代码细节,我们只需要告诉程序我们想要什么即可。比如说下面的 SQL 语句:
SELECT * FROM language;我们告诉机器,我们想获取 language 表中的全部信息,简单明了,至于机器如何去获取,我们并不用管。
应用这类编程范式的语言可以说是更为高层次的语言,它更容易被理解,应用起来更为方便,但是带来的就是性能上的不足,性能和方便上手往往是一个 trade-off。
-
Symbolic programming(符号式编程)
有些时候,我们很难直观地看到我们写的每一行程序背后所代表的意义,每一行代码在你面前展现的仅仅是一堆文字,有时候一堆变量名交织在一起,至于每个变量所代表的东西是什么,我们不能马上反应过来。
Aurora 是符号式编程的代表,在 Aurora 中,程序中的变量不再仅仅只由单一的变量名来呈现,而是可以由生动的图片,图表,数学公式等表现方式呈现,这可以让你很直观的知道当前的变量背后的数据具体是什么,有哪些依赖关系等等。
-
Knowledge-based programming(基于知识的编程)
这类语言的代表是 Wolfram Language,这类编程语言堪比百科全书,通过简单的命令,它可以告诉你几乎任何事情,比如当前的天气,你的 Facebook 好友连接拓扑图,操作图片,解数学公式等等。作者形象地说,基于这种语言,我们可以发明一个 IDE,这个 IDE 可以基于 Google Search 进行 Auto-Complete,这会大幅度提高编程的效率。但不可否认的是,这类语言的标准库函数肯定比一般语言的标准库函数要大的多的多。
Tip
当需要存入中文到 MySQL 的时候,MySQL 很可能因为编码不同而导致报错,因为 MySQL 默认编码是 UTF-8,当然这也要看 MySQL 的版本,如果是 8.0 以后的话,貌似是没有这个问题。
在 MySQL 中可以通过下面的指令查看编码设定:
$> show variables like %character%;
在我的电脑上显示是这样的:
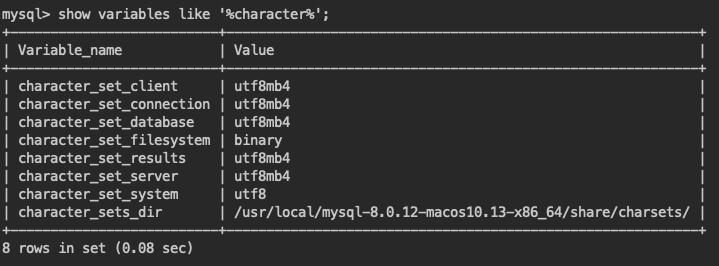
我 Mac 上的 MySQL 是 8.0 的版本,如果 character_set_server 对应的是 utf8 而不是 utf8mb4 ,那样的话是不能插入中文的。我们需要更改对应的配置文件。
看了网上的一些帖子,说的五花八门,但我在 Ubuntu server 上试,只需要改一个地方就好,就是在 /etc/mysql/mysql.cnf 中添加下面的代码
[client]
default-character-set = utf8mb4
[mysql]
default-character-set = utf8mb4
[mysqld]
character-set-client-handshake = FALSE
character-set-server = utf8mb4
collation-server = utf8mb4_unicode_ci
init_connect = 'SET NAMES utf8mb4'
然后需要重启 mysql 服务:
$> sudo service mysql restart
这时再进入到数据库查看编码设定,如果发现 character_set_server 那里对应的是 utf8mb4,那就没有问题。
记得把已经建立好的数据库和表格都删掉重建,因为之前建的表是对应的 UTF-8,重新建立才能改变数据库和表的配置。
Share
这周阅读一本讲关于如何有效阅读的书籍,这里写写读书笔记和感想。
