

一、认识文档数据库MongoDB
1、什么是mongoDB?
一个以JSON为数据模型的文档数据库
2、为什么叫文档数据库?
文档来自于"JSON Document"
3、主要用途
应用数据库 类似于Oracle、MySQL 海量数据处理,数据平台
4、主要特点
建模为可选
JSON数据模型比较适合开发者
横向扩展可以支撑很大数据量和并发
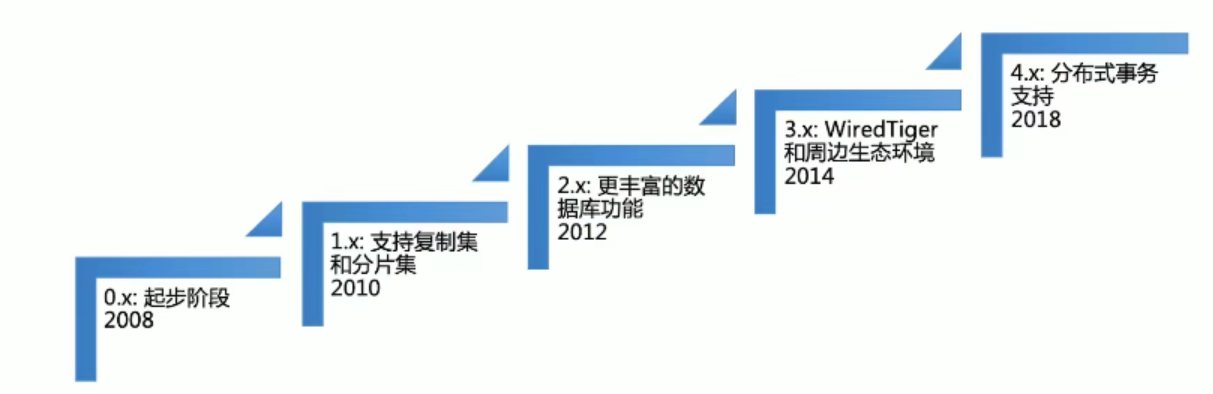
5、发展历史
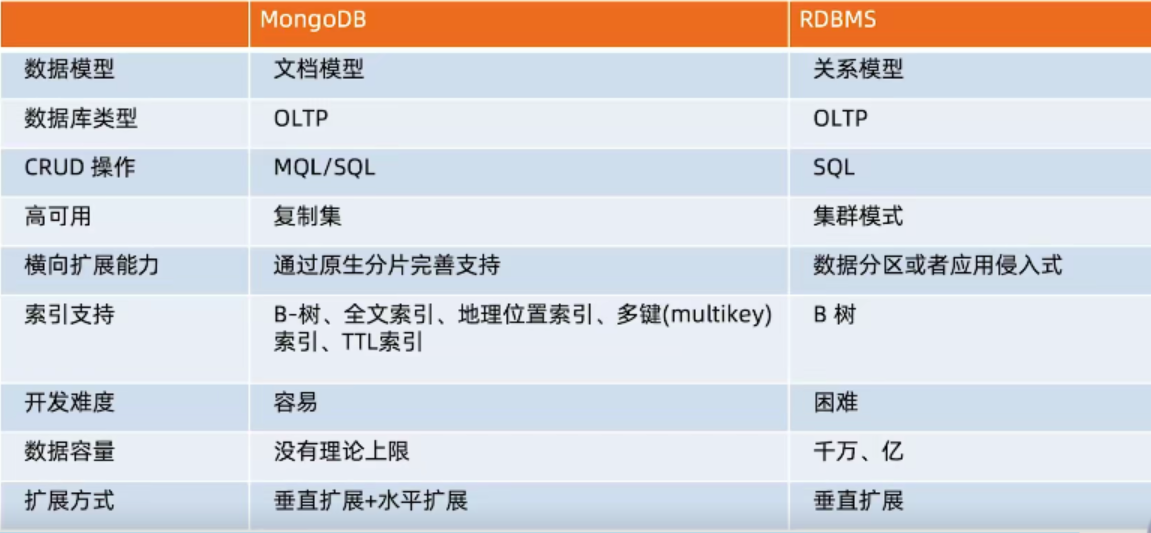
6、MongoDB和关系型数据库的对比
7、特色、优势
- 面向开发者的易用+高效数据库
- 简单直观
一目了然的对象模型
- 结构灵活 对业务场景变化有很好的支持

- 快速开发 更少的代码做更多的事


2)原生的高可用和易扩展能力
- Replica Set 2-50 个成员
- 自恢复
- 多中心容灾能力
- 滚动服务-最小优化服务终端
3)横向扩展能力
通过分片集群实现
- 需要的时候无缝扩展
- 应用全透明
- 多种数据分布策略
- 轻松支持TB-PB数量级
二、安装MongoDB
下载地址: www.mongodb.com/try/downloa…
云服务:
创建一个集群:
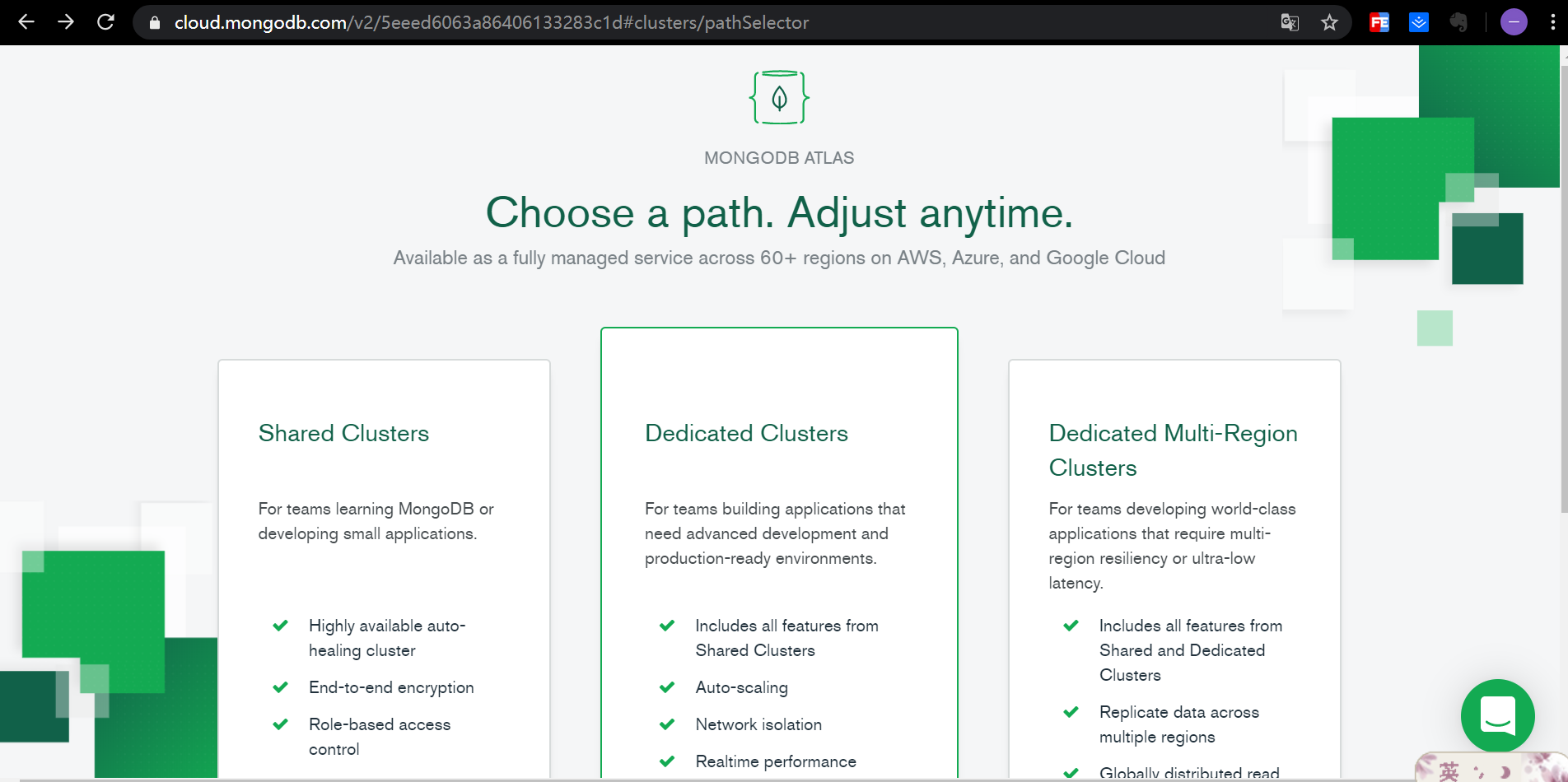
选择免费版本
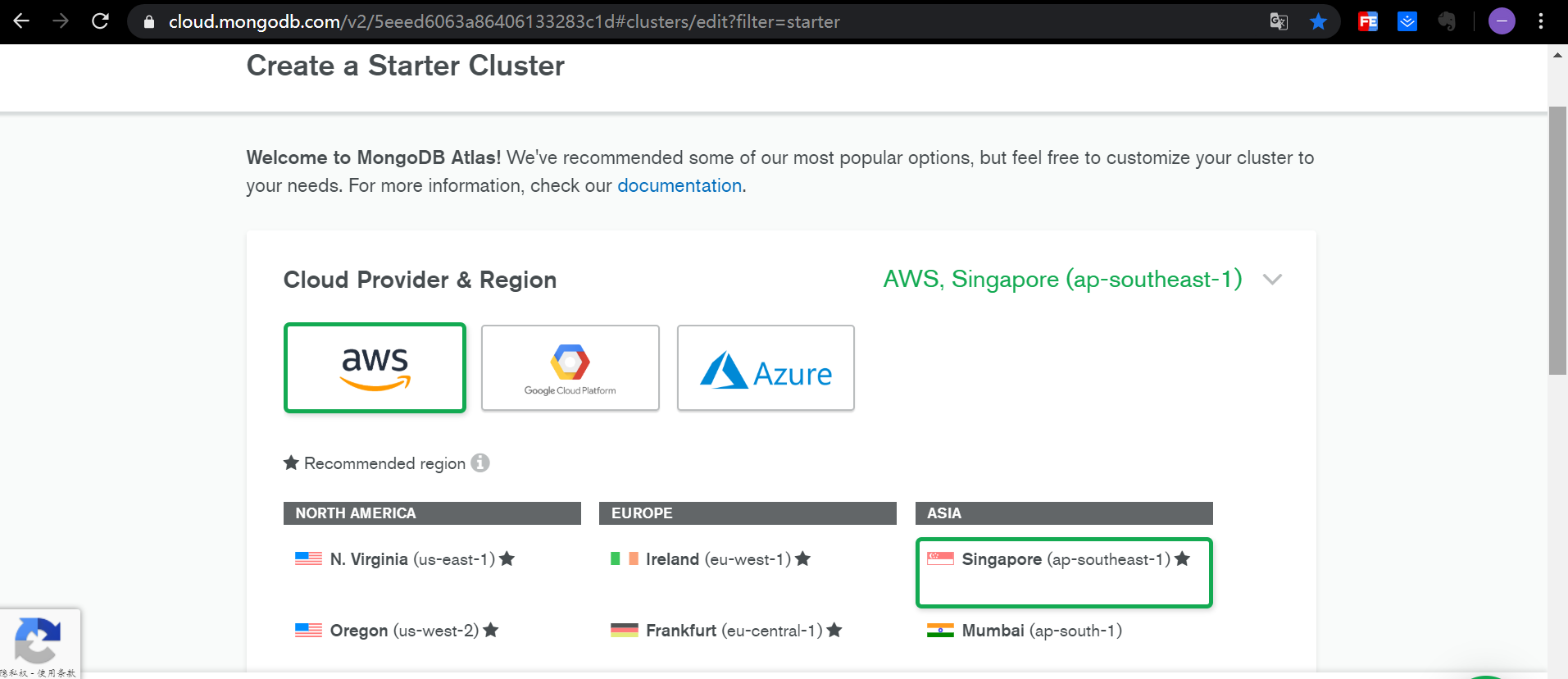

其他的配置可以选默认 点击创建。
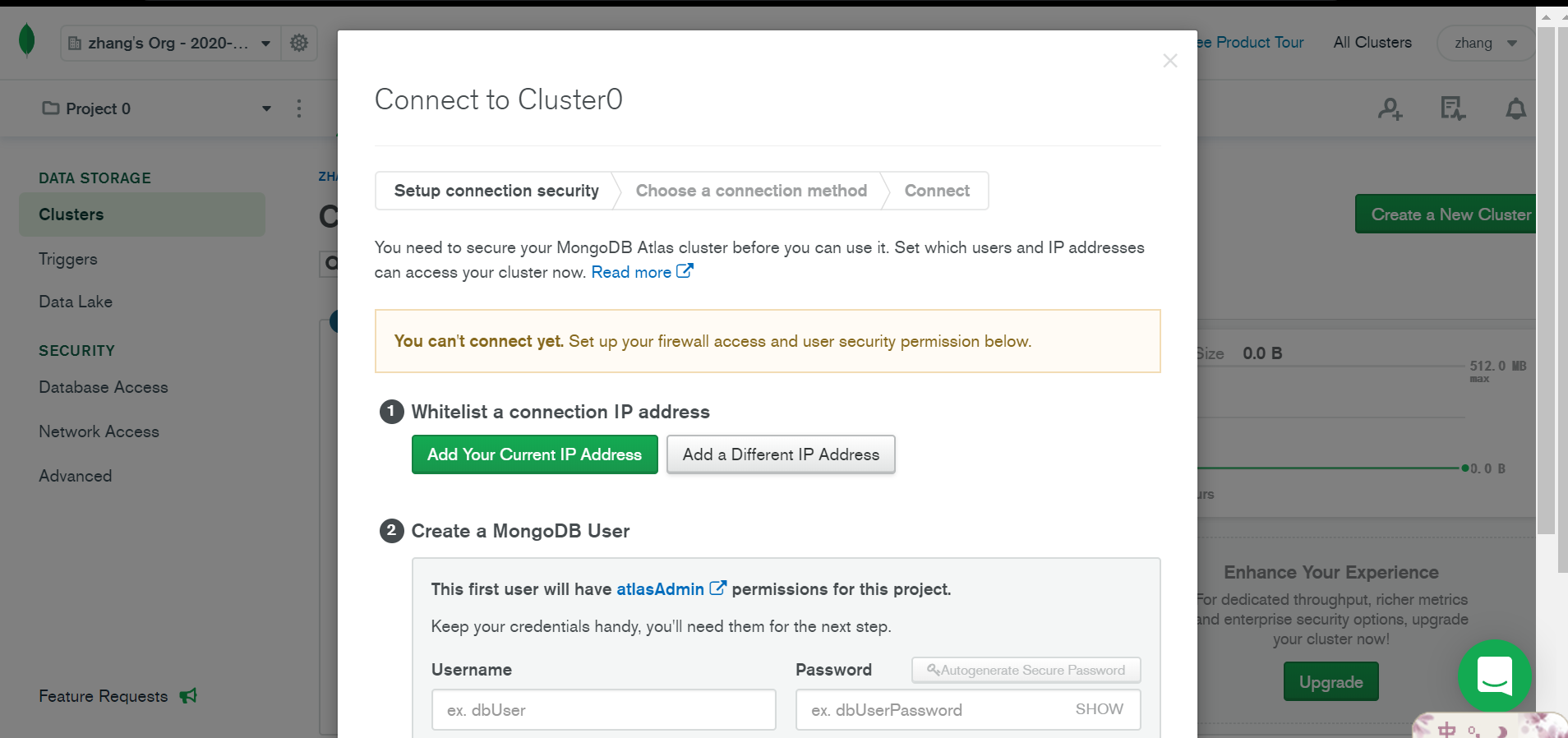
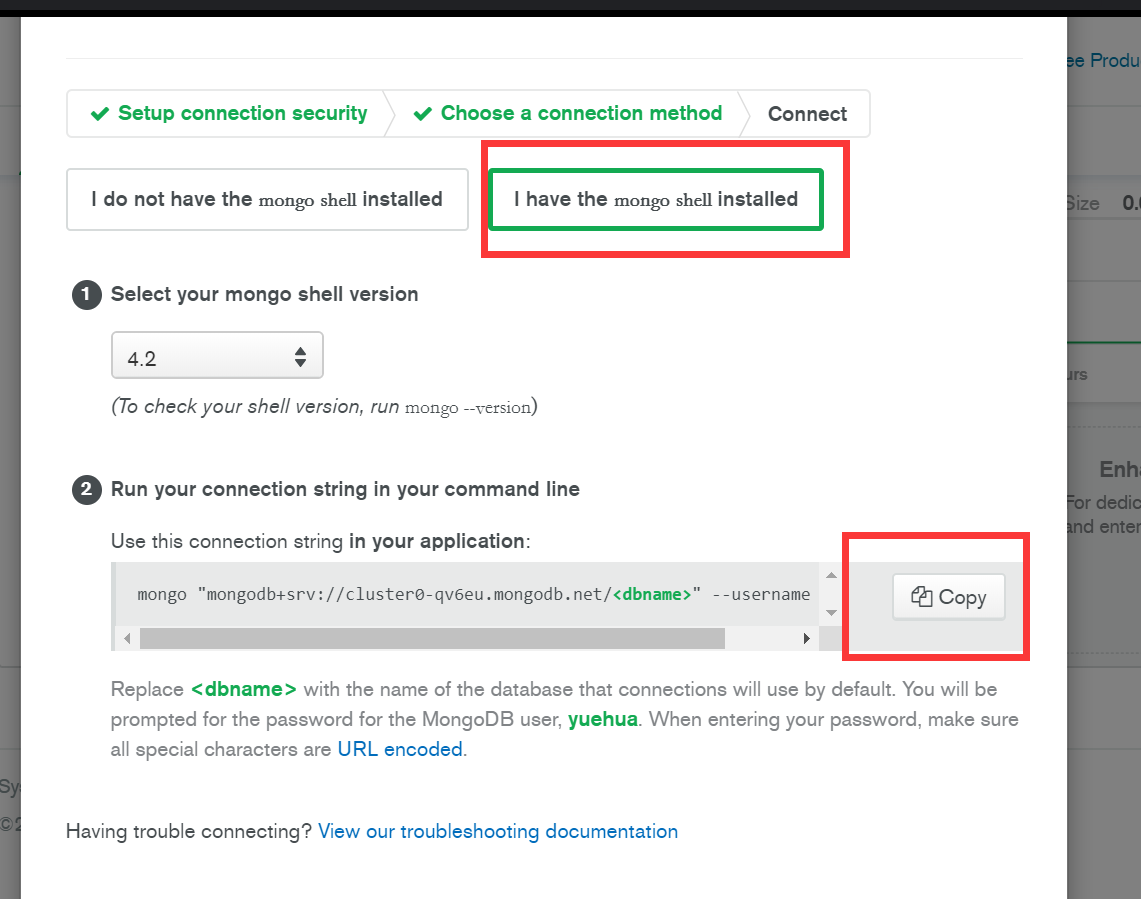
选择使用mongo shell 复制连接字符串。

并在cmd中运行,输入密码。

导入样本数据:
使用 命令 :curl -O -k raw.githubusercontent.com/tapdata/gee…
tar -xvf dump.tar.gz
三、基本操作
使用mongoimort 导入数据
mongoimport -d app -c user --file "E:\data\app\user.json" "要用双引号把你的路径引起来"
使用insert完成插入
- db.collection.insertOne({"name":"apple"})
- db.collection.insertMany([{},{}])
使用find完成查询
- find返回的是游标
- db.movies.find({"year":1975}) 单条件查询
- db.movies.find({"year":1975,"title":"Batman"}) 多条件查询
- db.movies.find({$and:[{"title":"Batman},{"category":"action"}]}) and另一种形式
- db.movies.find({$or:[{"year":1989},{"title":"Batman}]}) 多条件or查询
- db.movies.find({"title":/^B/})按正则表达式查找
查询条件对照
- 查询条件对照
- sql********************************mql
- a=1********************************{a:1}
- a<>1********************************{a:{$ne:1}}
- a>1********************************{a:{$gt:1}}
- a>=1********************************{a:{$gte:1}}
- a<1********************************{a:{$let:1}}
- a<=1 ******************************** {a:{$lte:1}}
- 查询逻辑对照表
- a=1 AND b=1********************************{a:1,b=1}或{$and:[{a:1},{b:1}]}
- a=1 or b=1 ******************************** {$or:[{a:1},{b:1}]}
- a IS NULL ******************************** {a:{$exists:false}}
- a IN (1,2,3)********************************{a:{$in:[1,2,3]}}
查询逻辑运算符
- $lt 存在并小于
- $lte 存在并小于等于
- $gt 存在并大于
- $gte 存在并大于等于
- $ne 不存在或存在但不等于
- $in 存在并在指定数组中
- $nin 不存在或不在指定数组中
- $or 匹配两个或多个条件中的一个
- $and 匹配全部条件
使用find搜索子文挡
假设有一个文档
db.fruit.insertOne({
name:"apple",
from:{
country:"china",
province:"guangdong"
}
})
db.fruit.find({"from.country":"china"}) 成功返回数据
db.fruit.find({"from":{country:"China"}}) 错误的 什么也查不到
使用find搜索数组中的对象

在数组重搜索子对象的多个字段时,如果是用$elemMatch,他必须表示是同一个对象满足多个条件。
db.getCollection('movies').find({"filming_locations:{$elemMatch:{"city":"Rome","country":"USA"})
控制find 返回的字段
- find可以指定只返回指定的字段
- _id字段必须明确指明不返回 默认返回
- 在mongodb 中称为投影 projection
- db.movies.find({"category":"action"},{"_id":0,title:1}) 返回title
删除文档
- remove 需要配合查询条件使用
- 匹配查询条件的文档会被删除
- 指定一个空文档 会删除所有文档
db.testcol.remove({a:1}) 删除a=1的记录
db.testcol.remove({a:{$lt:5}}) 删除a小于五的记录
db.testcol.remove({}) 删除所有
db.testcol.remove() 报错
update更新文档
db.集合名.update(<查询字段>,<更新字段>)
db.fruit.updateOne({name:"apple"},{$set:{from:"China"}})
db.fruit.find().pretty() 显示更友好
updateOne只更新第一条
updateMany 匹配多少条就更新多少
updateOne/updateMany 要求更新条件部分必须具有以下之一
- $set
- $unset
- $push 增加一个对象到数组底部
- $pushall 增加多个对象到数组底部
- $pop 从数组底部删除一个对象
- $pull 如果匹配指定的值,从数组中删除相应的对象
- $pullAll 如果匹配任意的值,从数组中删除相应的对象
- $addToSet 如果不存在则增加一个值到数组
删除
删除集合 db.collection.drop()
db.dropDatabase()删除数据库
四、hello world 程序开发
1、安装Python MongoDB驱动程序
在Python中使用MongoDB之前必须先安装用于访问数据库的驱动程序
pip install pymongo
检查驱动
import pymongo
print(pymongo.version)
2、创建连接
确定MongoDB连接串
mongodb://127.0.0.1:27017
初始化数据库连接
mongo先运行在默认端口
from pymongo import MongoClient
uri = "mongodb://127.0.0.1:27017"
client = MongoClient(uri)
print client
3、数据库操作
初始化数据库和集合
db = client["eshop"]
user_coll = db["users"]
插入一条新的用户数据
new_user = {"username":"nina","password":"xxxx","email":"1234567897@qq.com"}
result = user_coll.insert_one(new_user)
print result
4、更新用户
需求变化,要求改变用户属性 ,增加字段phone
(没有在数据库修改该表结构)
result = user_coll.update_one({"username":"nina"},{"$set":{"phone":"123456789"}})
print result
五、聚合查询
1、介绍

2、管道和步骤
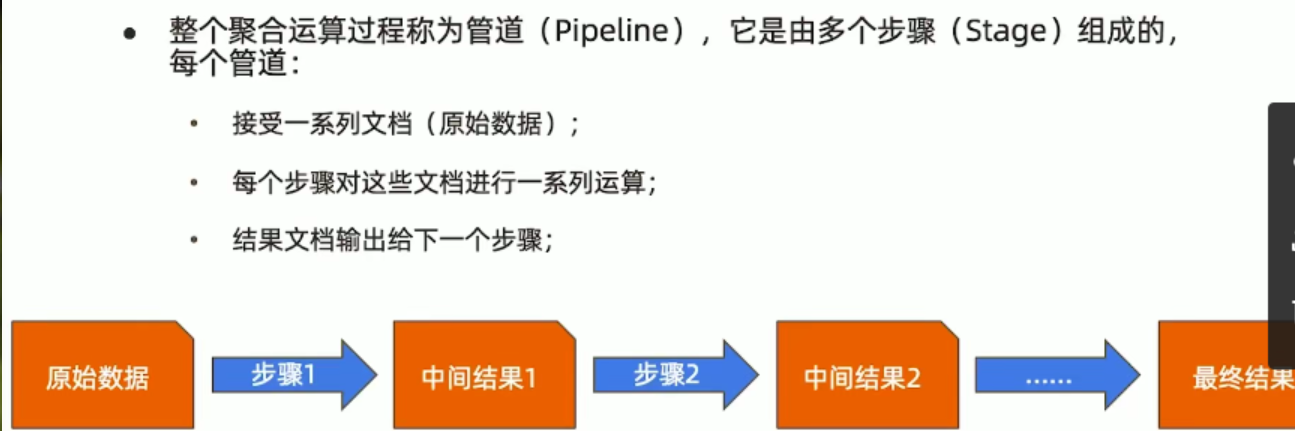
3、基本格式
//$stage1 一个步骤 JSON格式
pipeline = [$stage1,$stage2,...$stagen]
db.<COLLECTION>.aggregate(pipeline,{options})
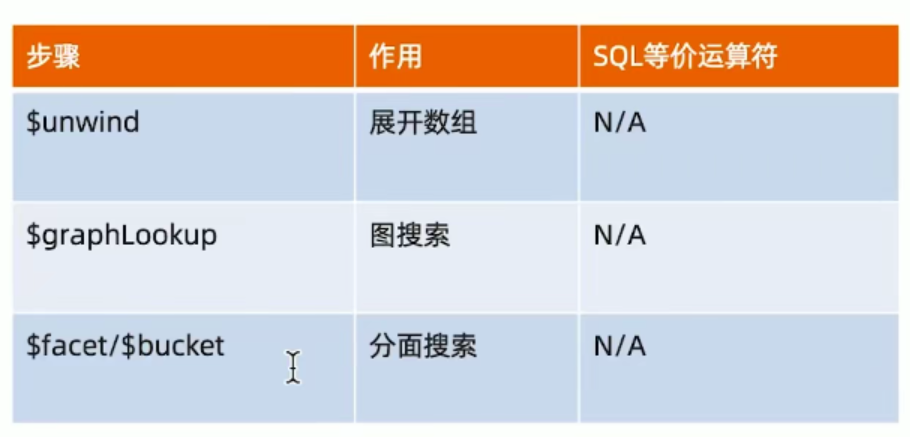
4、常见步骤
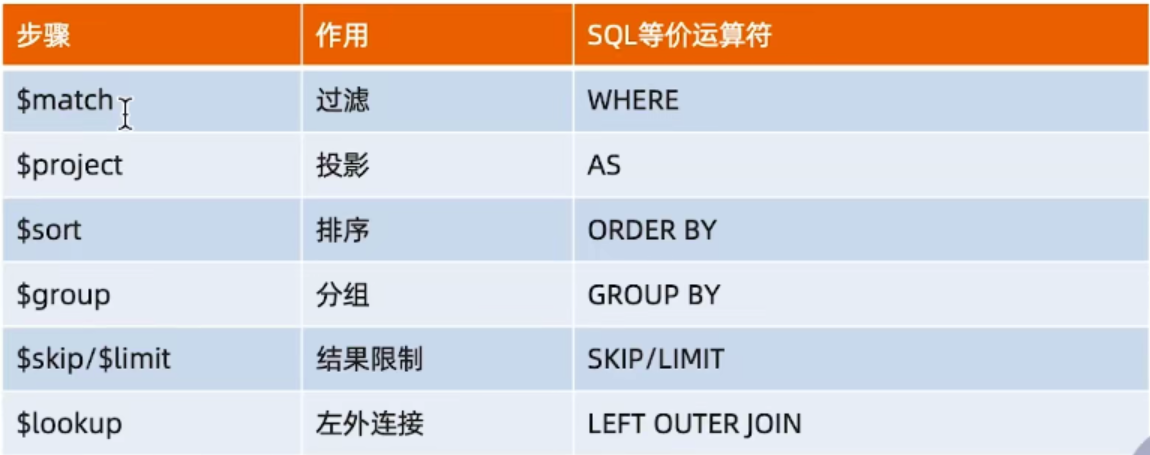
常见步骤中的运算符

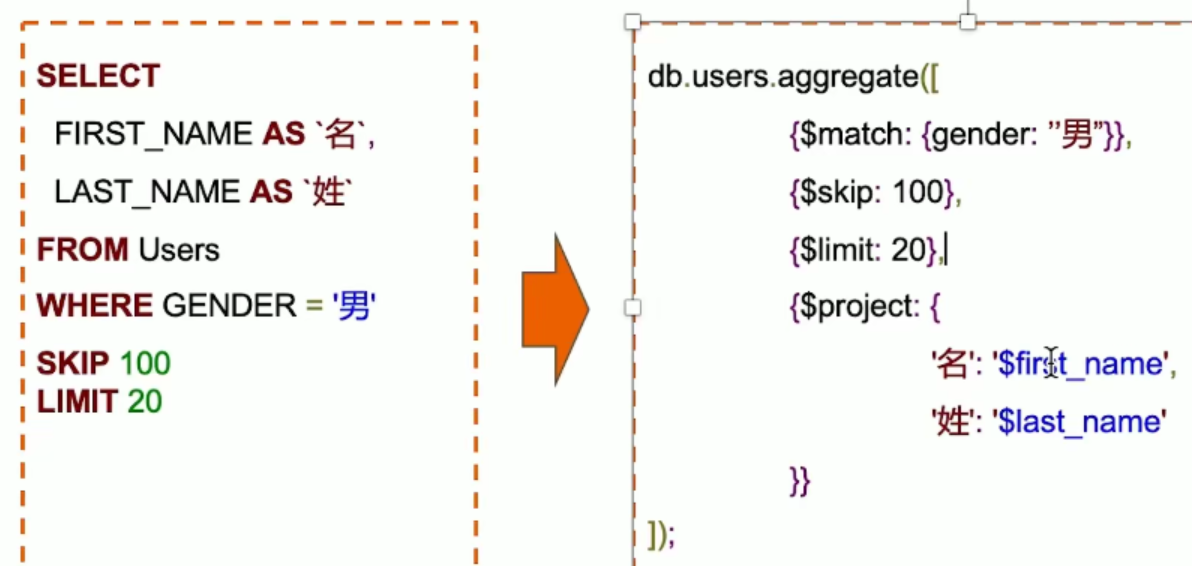
聚合查询使用场景

对比
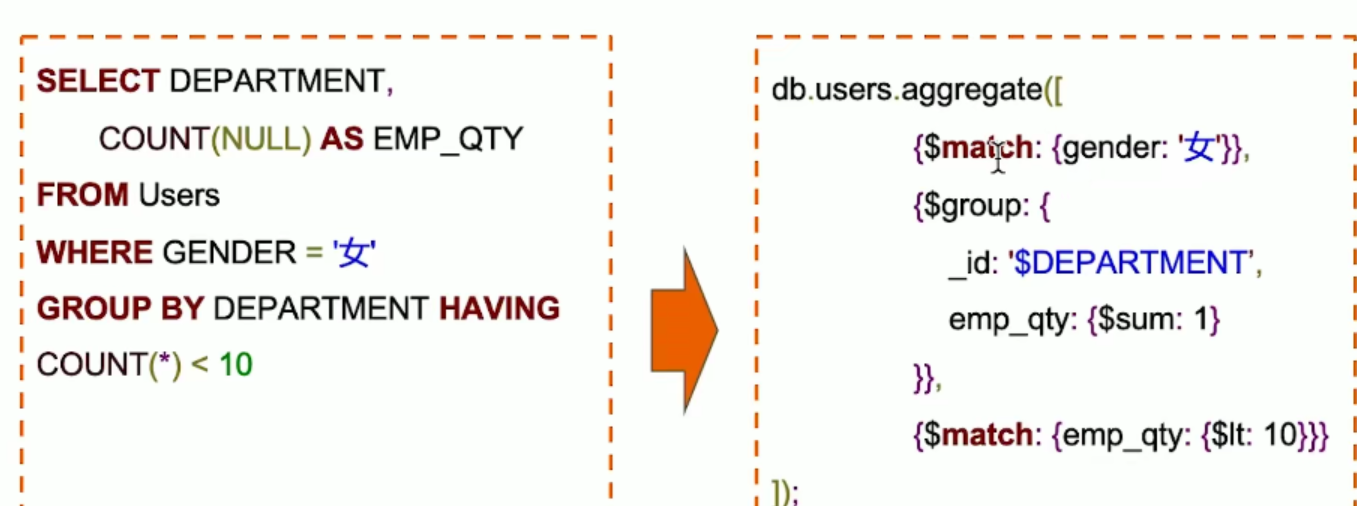
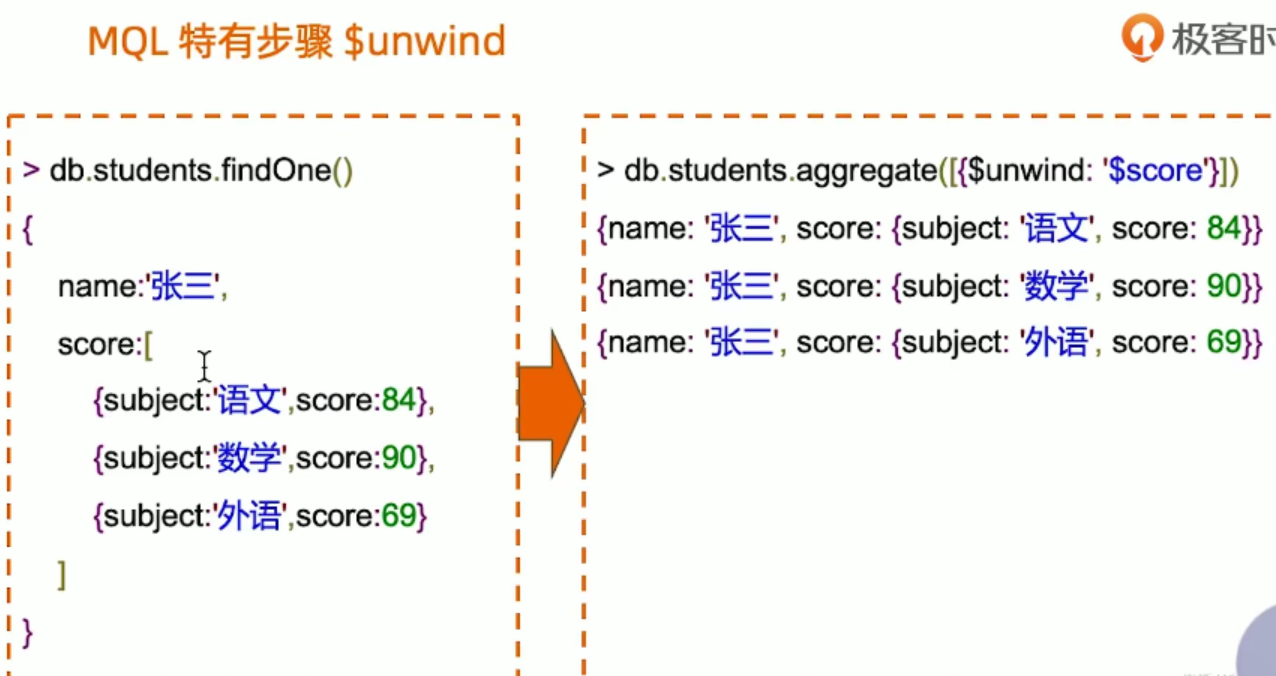
展开
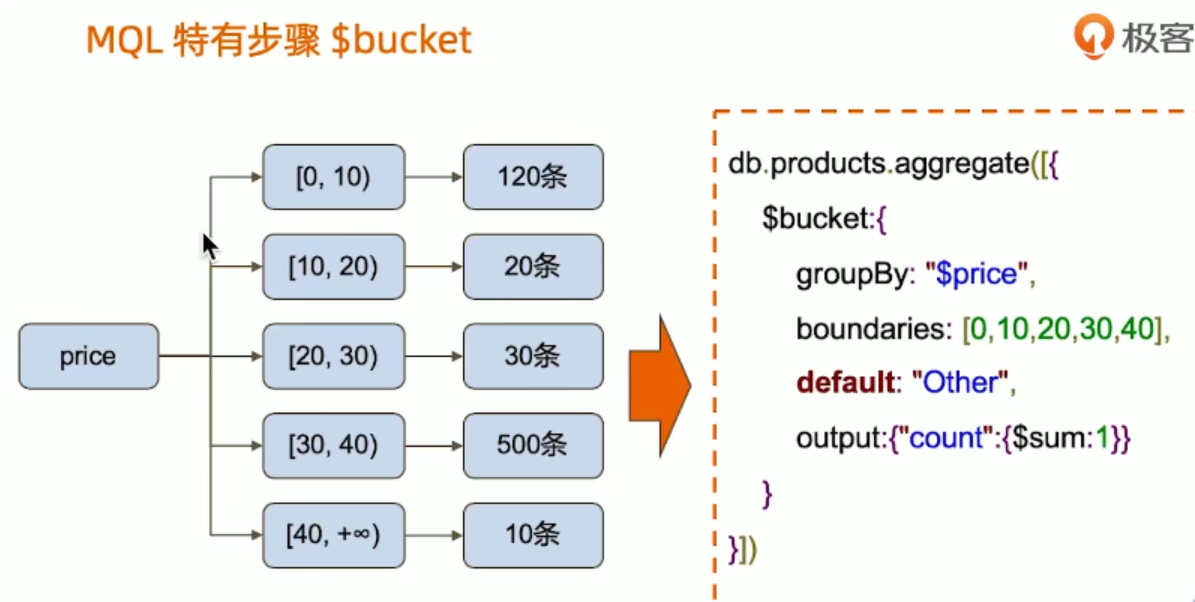
分组
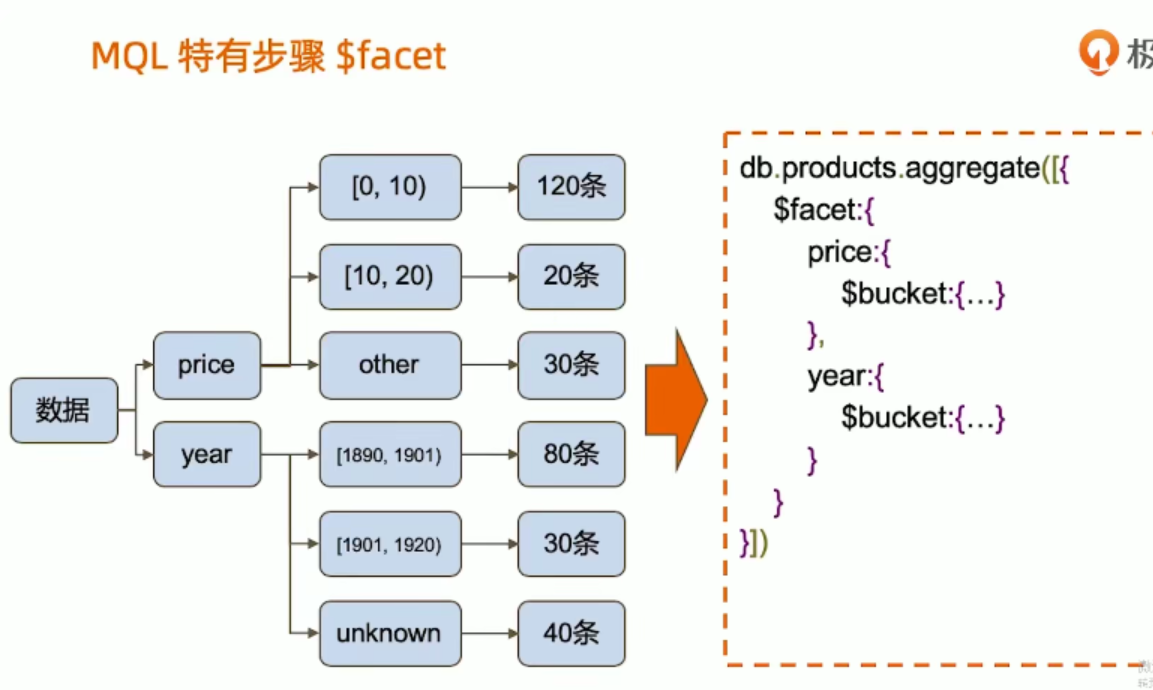
从不同的维度分组
六、聚合实验
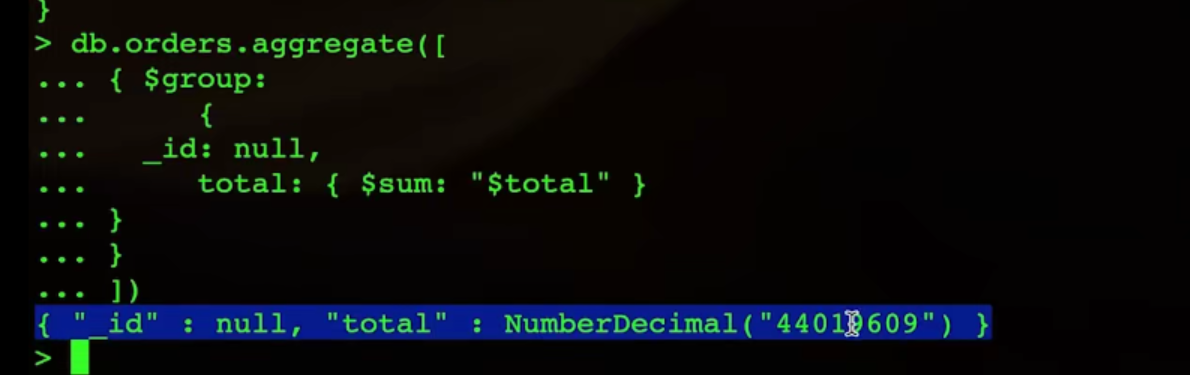
数据
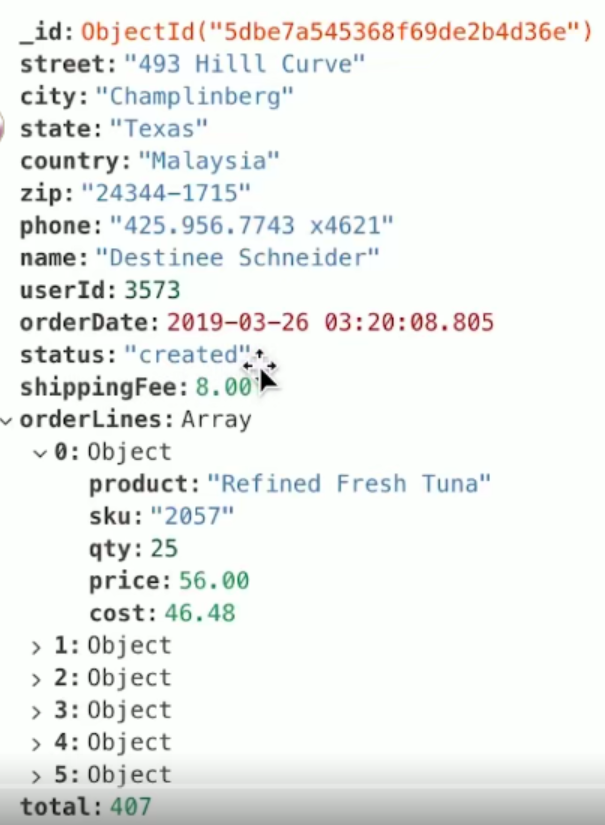
db.orders(集合名).aggregate(方法名)([
{
$group:{
_id:null,//没有分组,把一个表当成一个大分组
total:{ $sum:"$total"
}
}
}
])

七、 复制集机制及其原理
意义:实现服务高可用
它的实现主要依赖于两个方面的功能:
-
数据写入是将数据迅速复制到另一个独立节点上
-
在接受写入的节点发生故障时自动选举出一个新的替代节点
复制集的作用:
- 高可用
- 数据分发 将数据从一个区域复制到另一个区域,减少另一个区域的读延迟
- 读写分离 将不同类型的压力分别在不同的节点上执行
- 异地容灾 在数据中心故障的时候快速切换到异地