

Bloom过滤器适合与做海量数据的过滤
为什么和HashTable很相似
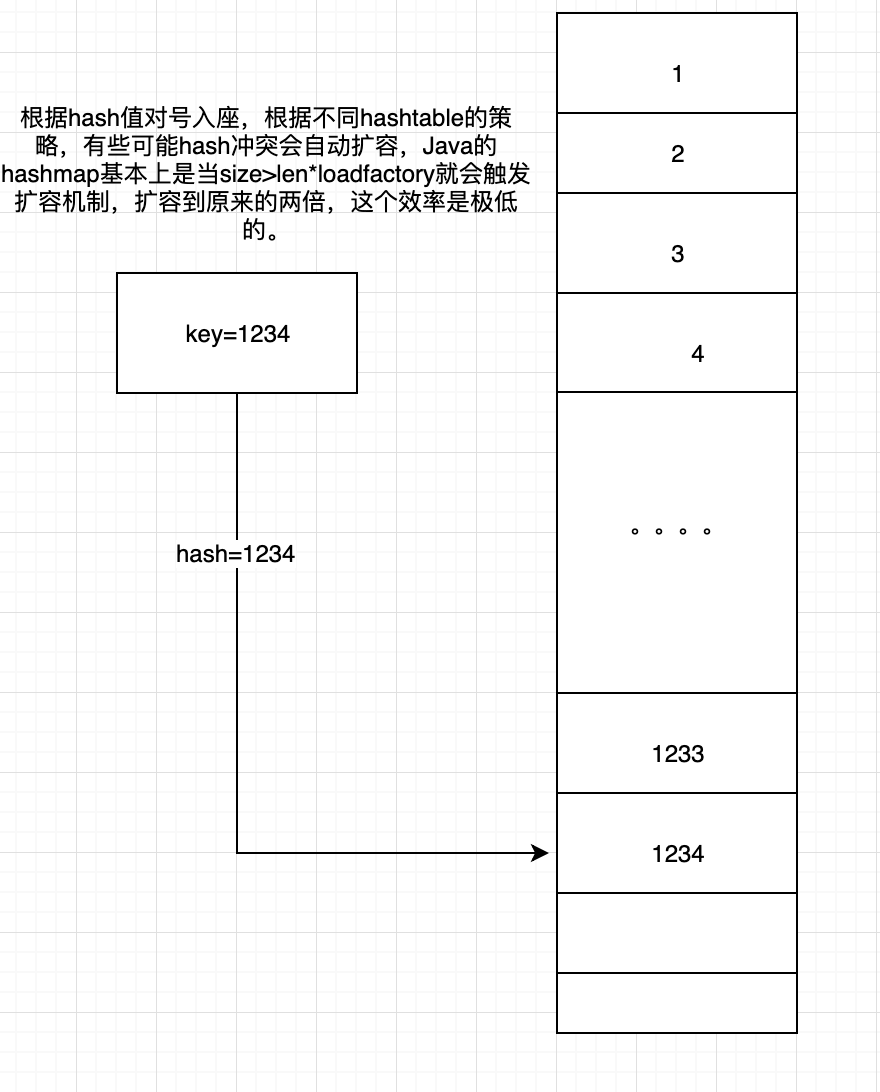
首先我们来思考一下hash表,hash表的最优的时间复杂度O(1),其实原理很简单,就是根据key,算一下hash值,然后对号入座,遇到冲突可能根据不同的设计有不同的策略罢了。
Bloom原理
其实原理很简单,网上也有很多图,大致如下。我就不画图了
假设现有也有一个空的hashtable,每个sheet内部值只有两个状态 : 0或者1,那么其实就是比特流,所以一个key最优只会占用1bit ,所以可以存储海量的key,在最小的空间内部。
大约32位的key,1<<32-1的key,大约是40多E个key,只需要500M左右的空间,

现在我们需要添加一个数据, obj1=123456, obj2=1234567 ,下面的fun1,fun2,fun3是不同的hash计算逻辑,根据不同的hash方法,然后修改对应格子的状态。
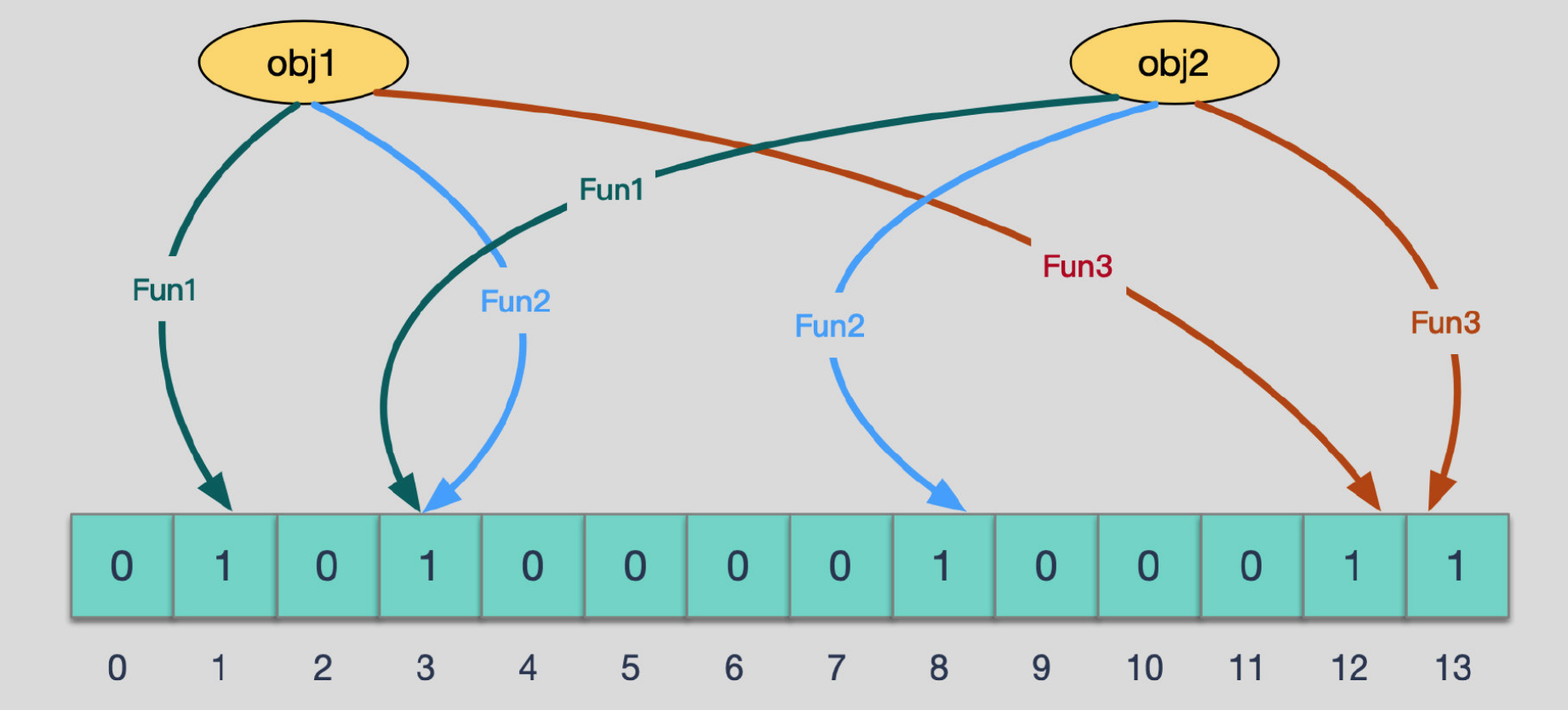
我们可以发现,如果hash函数只有一个的话,其实和HashMap的key存储很相似,基本上一致。
但是Bloom为了防止Hash冲突,通常会设置多个hash函数,来保障不冲突。
优点
1、海量存储、内存占用量极低
2、不存储数据本身,保密性好,不排除hash逆推(目前计算机算力几乎无法实现)
3、依靠hash算法,可以保障几乎不可能出现不可靠的问题。(比如key=123456,hash1=1 出现hash冲突,hash2=2 出现hash冲突,hash3=3 发现=0,此时key=123456不存在),所以它可以保障可靠性。
缺点
1、无法删除数据(当hash函数大于1个的时候)
2、数据量小,不如使用hashtable,
3、bloom的 结构是一开始就确定的大小,可以增加长度,但是不可以减少长度
难点
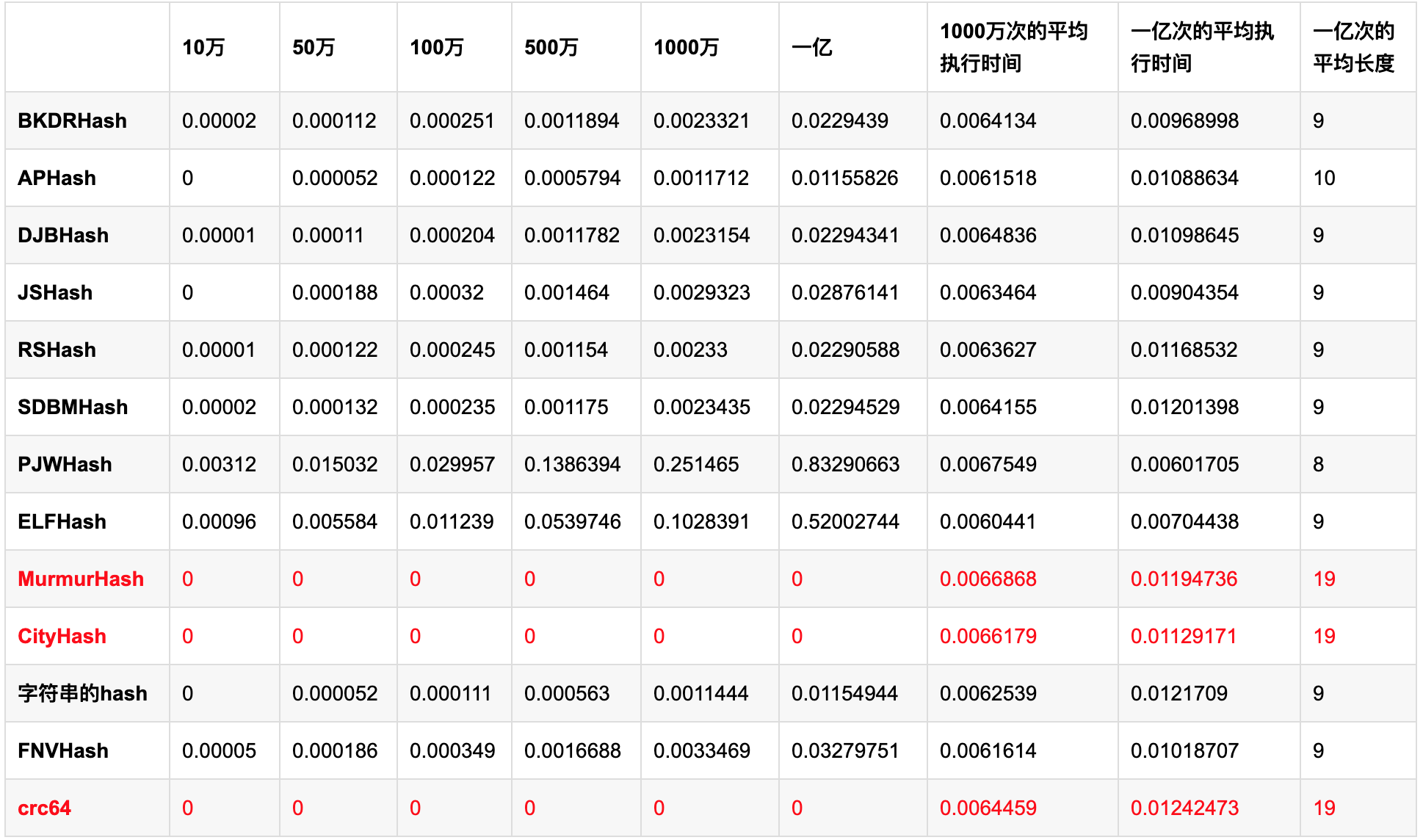
hash算法的实现,下面是几个hash算法的,碰撞率以及执行效率,其实当hash算法能够保证碰撞率为0,其实bloom过滤器的hash-func也就只用1个足矣。
Redis完美契合
redis 支持一个
GETBIT和SETBIT的操作,完美契合
127.0.0.1:6379> SETBIT bloom 4294967295 1
(integer) 0
(0.55s)// 初始化一个2<<32-1 ,所以很耗时,这个长度也是redis支持最大的长度
127.0.0.1:6379> GETBIT bloom 4294967295
(integer) 1 //查询很高效
127.0.0.1:6379> info
# Memory
used_memory:537961776
used_memory_human:513.04M //使用内存大致是513M,可以存储40E个key
used_memory_rss:503865344
used_memory_rss_human:480.52M
used_memory_peak:637923344
所以使用redis完美契合,正好支持二进制查询,还以自动扩容长度。
好像redis有插件支持bloom,对于hash函数过多,并不适合使用redis,必须使用lua脚本,减少请求次数,其次保证原子性操作。
