

你也许认为这是NoSQL (Not Only SQL)广告宣传的另一个博客。
是,这的确是。
但是如果这个时候你仍就为寻找一个可行的NoSQL解决方案而苦恼,读完这篇后你就知道该做什么了。
当我以前参与Perfect Market的内容处理平台时,我拼命地尝试寻找一个极端快速(从延时和处理时间上)和可扩展的NoSQL数据库方案,去支持简单地键/值查询。
在开始前我预定义了需求:
- 快速数据插入(Fast data insertion)。有些数据集可能包含上亿的行(KV键值对),虽然每行数据很小,但如果数据插入很慢,那将这个数据集传入数据库将需要花几天时间,这是不可接受的。
- 大数据集上的快速随机读取(Extermely fast random reads on large datesets)。
- 在所有数据集上的一致的读写速度。这个意思是说,读写速度不能因为数据如何保持和index如何组织就在某个数据量上拥有很好的值,读写速度应该在所有的数据量上均衡。
- 有效的数据存储。原始的数据大小和数据被导入数据库中的大小应该相差不大。
- 很好的扩展性。我们在EC2的内容处理节点可能产生大量的并发线程访问数据节点,这需要数据节点能很好的扩展。同时,不是所有的数据集是只读的,某些数据节点必须在合适的写负载下很好的扩展。
- 容易维护。我们的内容处理平台利用了本地和EC2资源。在不同的环境里,同时打包代码,设置数据,和运行不同类型的节点是不容易的。预期的方案必须很容易维护,以便满足高自动化的内容处理系统。
- 拥有网络接口。只用于库文件的方案是不充足的。
- 稳定。必须的。
我开始寻找时毫无偏见,因为我从未严格地使用过NoSQL产品。经过同事的推荐,并且阅读了一堆的博客后,验证的旅程开始于Tokyo Cabinet,然后是 Berkeley DB库, MemcacheDB, Project Voldemort, Redis, MongoDB。
其实还存在很多流行的可选项,比如Cassandra, HBase, CouchDB…还有很多你能列出来的,但我们没没有必要去尝试,因为我们选择的那些已经工作得很好。结果出来相当的不错,这个博客共享了我测试的一些细节。
为了解释选择了哪个以及为什么选择这个,我采纳了同事Jay Budzik(CTO)的建议,创建了一张表来比较所有方案在每一个需求上的情况。虽然这张表是一个事后的事情,但它展示了基本原理,同时也会对处于决策的人们带来帮助。
请注意这个表不是100%的客观和科学。它结合了测试结果和我的直觉推导。很有趣,我开始验证时没有偏见,但测试完所有的后,我也许有了一点偏心(特别是基于我的测试用例)。
另一个需要注意的是这里的磁盘访问是I/O密集性工作负载里最慢的一个操作。相对于内存访问, 这是毫秒与纳秒的关系。为了处理包含上亿行的数据集合,你最好给你的机器配置足够的内存。如果你的机器只有4G内存而你想处理50GB的数据且期望较好的 速度,那你要么摇晃你的机器,要么用个更好的,否则只能扔到下面所有的方案,因为它们都不会工作。
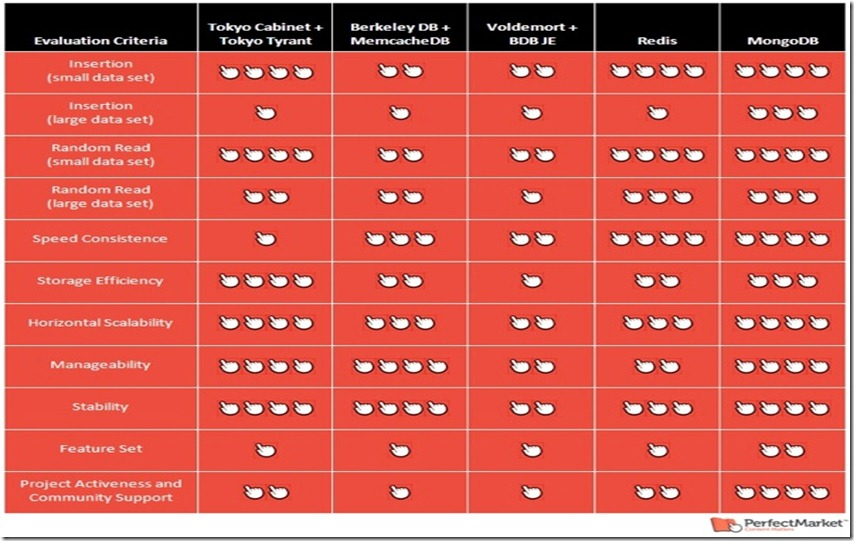
**Tokyo Cabinet (TC)**是一个非常好的方案也是我第一个验证的。我现在仍然很喜欢它,虽然这不是我最后选择的。它的质量惊人的高。哈希表数据库对于小数据集(低于2千万行)惊人的快,水平扩展能力也很好。TC的问题是当数据量增加时,读写的性能下降的特别快。
Berkeley DB(BDB)和MemcacheDB (BDB的远程接口)是一个较老的结合物。如果你熟悉BDB,并且不是非常依赖速度和功能集合,比如你愿意等几天去加载大数据集到数据库里并且你接受一般但不优秀的读速度,你仍可以使用它。对于我们,事实是它花了太长的时间来加载初始数据。
Project Voldemort是唯一一个基于Java和云计算的方案。在验证前我有很高的期望,但是结果却有点失望,原因是:
- BDB Java版本让我的数据膨胀得太厉害(大概是1比4,而TC只有1比1.3)。基本上存储效率非常低。对于大数据集,它就是灾难。
- 当数据变得很大的时候,插入速度降低得很快。
- 当大数据集被加载时偶尔由于无法预测的异常而崩溃。
当数据膨胀得太厉害并且偶尔系统崩溃时,数据加载还没有完成。只有四分之一的数据被传播,它读速度还可以但不出色。在这个时候我想我最好放弃它。否则,除了上面列的那些需要优化,JVM可能让我操更多的心让我的头发灰的更多,虽然我已经为Sun工作了五年。
Redis是一个极好的缓存解决方案,我们也采用了它。Redis将所有的哈希表存在内存里,背后有一个线程按 照预设的时间定时将哈希表中的快照存到磁盘上。如果系统重启,它可以从磁盘上加载快照到内存,就像启动时保温的缓存。它要花几分钟来恢复20GB的数据, 当然也依赖你的磁盘速度。这是一个非常好的主意,Redis有一个合适的实现。
但是在我们的用例里,它工作得并不好。后台的保存程序仍妨碍了我们,特别是当哈希表变得更大时。我担心它会负面地影响读速度。使用logging style persistence而不是保存整个快照,可以减缓这些数据转存的影响,但是数据大小将会膨胀,如果太频繁,将最终影响恢复时间。单线程模式听起来不是 可伸缩的,虽然在我的测试里它水平方向扩展的很好:支持几百个并发读。
另一个事情干扰我的是Redis的整个数据集必须适合物理内存。这点使得它不容易被管理,象在我们这样在不同的产品周期造成的多样化的环境里。Redis最近的版本可能减轻了这方面的问题。
MongoDB是至今我最喜欢的,在我所验证的所有解决方案中,它是胜出者,我们的产品也正在使用。
MongoDB提供了不同寻常的插入速度,可能原因是延迟写入和快速文件扩展(每个集合结构有多个文件)。只要你拥有足够的内存,上亿的数据行能在 几小时内插入,而不是几天。我应该在这提供确切的数据,但数据太具体(与我们的项目有关)不见得对别人有帮助。但相信我,MongoDB提供了非常快的大 数据量插入操作。
MongoDB使用内存映射文件,它一般花纳秒级的时间来解决微小的页面错误,让文件系统缓存的页面映射到MongoDB的内存空间。相比于其它方 案,MongoDB不会和页面缓存竞争,因为它使用和只读块相同的内存。在其它方案里,如果你分配给太多的内存给工具自身,那盒子里的页面缓存就变得很 少,并且一般来说想让工具的缓存完全地预热不是很容易,或者没有一个有效地方法(你绝对不想事先去从数据库里读取每一行)。
对于MongoDB,可以非常容易地做一些简单的技巧让所有的数据加载到页面缓存。一旦在这个状态,MongoDB就很像Redis,在随机读上有较好的性能。
在我另一个测试中,200并发客户在大数据集(上亿行数据)做持续的随机读取,MongoDB表现了总体上的400,000QPS。测试中,数据在 页面缓存里预热(事先加载)。在随后的测试中,MongoDB同样显示了在适度的写负载下拥有非常好的随机读取速度。在相对来说一个大的负载下,我们压缩 了数据然后将它存入MongoDB,这样就减少了数据大小所以更多的东西能放入内存。
MongoDB提供了一个方便的客户端工具(类似MySQL的),非常好用。它也提供了高级的查询功能,处理大型文档的功能,但是我们还没有用到这 些。MongoDB非常稳定,基本不需要维护,处理你可能要监控数据量增大时的内存使用情况。MongoDB对不同的语言有很好的客户端API支持,这使 得它很容易使用。我不用列举它所有的功能,但我想你会得到你想要的。
虽然MongoDB方案可以满足大多数NoSQL的需求,但它不是唯一的一个。如果你只需要处理小数据量,Tokyo Cabinet最合适。如果你需要处理海量数据(PB千兆兆)并拥有很多机器,而且延时不是个问题,你也不强求极好的响应时间,那么Cassandra和 HBase都可以胜任。
最后,如果你仍需要考虑事务处理,那就不要弄NoSQL, 直接用Oracle。
