

背景
伴随着互联网的快速发展,以及互联网在线服务的特性,快速获得数据反馈,及时做出决策对企业而言越来越重要。公司现有数据仓库依赖spark进行日志数据处理的旧架构已经日益不能满足线上越来越多的实时性需求。在此背景下,基于flink的新一代实时数据仓库无疑将在未来扮演中着重要的角色。故而,学习,掌握flink将会成为在将来的大数据浪潮中的立身之本。《笨鸟先飞》系列博文主要是记录了笔者自己在实际学习/工作中所汇总记录的flink知识点:开发要点,测试要点,一些实际代码开发操作,以及踩到的坑,自己的一些感悟。作为沉淀,以帮助大家更好的学习flink。
初识Flink
第一次听说flink大概是在一年前。那时候只知道flink是新兴的大数据计算框架。相对与apache spark来说,其实时性确实就是其优势。不过碍于当时的业务需求,并没有做更为深入的了解。现在转头来想,如果当时就去学习,我现在可能就已经学会来flink。在it行业,在飞速发展的技术目前,不进则退。所以如果有什么想学的话,就尽早去学,以免自己后悔。
那么 Apache Flink 是什么?
Apache Flink 是一个分布式大数据处理引擎,可对有限数据流和无限数据流进行有状态或无状态的计算,能够部署在各种集群环境,对各种规模大小的数据进行快速计算。
以上是官方对flink的功能的简要介绍。简洁,但不便理解。对于第一次接触大数据计算引擎的人来说。可能首要搞清楚的是:
什么是有界数据?什么是无界数据?
有界数据
在常见的数据处理中我们都会从Mysql,文本等获取数据进行计算分析。我们在处理此类数据时,特点就是取数周期内的数据是静止不动的,例如某天,某小时的数据集。也就是说,后续没有再进行追加,又或者说再处理的当时时刻不考虑追加写入操作。所以有界数据集又或者说是有时间边界。在某个时间内的结果进行计算。那么这种计算称之为批计算,批处理。典型的代表就是spark rdd。
无界数据
另外一种数据,在程序的运行过程中,日志是处于一直生产,输出状态的,因为不知道结束时间,只知道数据会一直追加,诸如此类的场景。我们认为这些数据是无界的。对于此类持续变更、追加的数据的计算方式称之为流计算。
以下图展示有界数据与无界数据的差异。
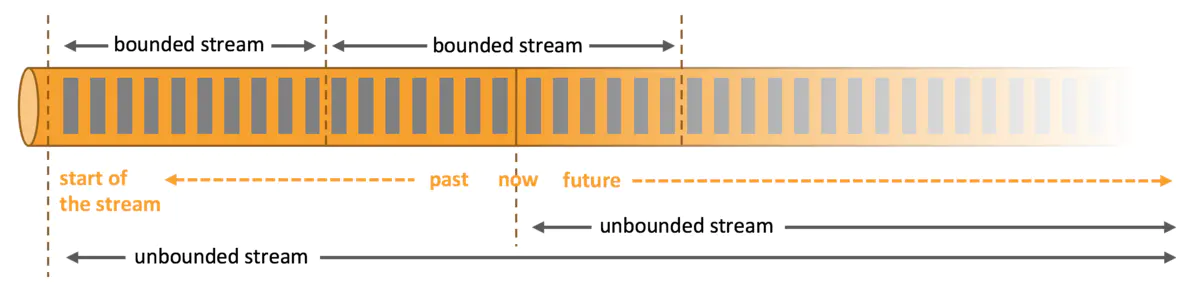
对于有界的大数据处理,目前业界内普遍使用Apache Spark进行处理。而无界数据集的处理,也可以使用spark来完成。但使用spark处理流式数据,目前主要存在如下几个痛点:
1、Spark Streaming 底层基于微批次处理的计算引擎,无法满足业务对数据秒级更新的需求。
2、批处理存在事件乱序问题,处理结果与实际预期会出现误差。
flink完美解决了以上存在的问题。所以现在业界内越来越多的企业开始使用flink作为其大数据实时分析的计算引擎。
