

背景:
HashMap 在项目中使用的比较多,在我司的项目中Found Usages 多达5800余处,刨去三方库直接使用的地方也大概1400多处。但是,大部分的使用是不合理的(当然代码能跑起来吗?能。有更好的方案吗?有,所以说是不合理的)。会带来一定性能的影响。因此,这篇文章的目的就是科普 "HashMap的正确使用姿势"。
举例项目中一些不太合理的用法:
1.直接new HashMap<>()
2. new HashMap<>(2),实际使用长度为2。
3. new HashMap<>(6),实际使用长度为6,这样你觉得合理么?
以上这几点你也带着疑惑的,可以继续阅读。如果以上这些用法,你都知道为什么不太合理,那你可以快速的滑到Demo验证那里了。
HashMap基本知识:
注:限于篇幅我们不在此篇文章进行详细的源码分析,有必要可以自行搜索了解(网上文章非常多)。
1.数据结构
HashMap的数据存储结构,在jdk1.7中,属于标准的 数组+链表; 在jdk1.8中,为数组 + 链表/红黑树。根据key计算出的hash值,与数组长度-1进行按位与运算计算下标,伪代码: (length - 1) & hash
2.数组大小
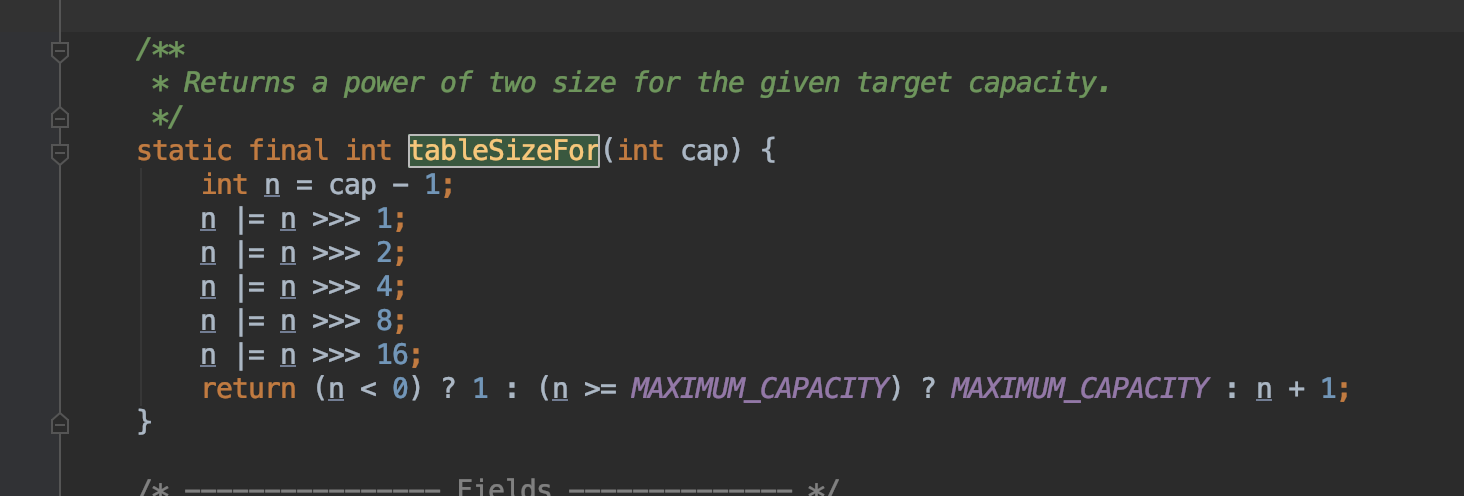
在HashMap中的,数组的大小被限制为2^n,tableSizeFor 返回大于输入参数且最近的2的整数次幂的数。比如初始化长度为6,则返回8。如下图:
3.负载因子
负载因子loadFactor,默认值:0.75。
负载因子是用来控制数组存放数据的疏密程度的,默认为0.75的目的是尽量减少哈希碰撞,提高效率,并且充分利用内存空间(如果不知道具体怎么提高效率的,建议系统学习一下Java中的数组和集合)。
4.扩容机制
HashMap采用的是预扩容机制:实际存的数据量达到 "负载因子*当前容量",就会提前扩容为原来的两倍(如果是单个加入时,扩容两倍;如果是批量加入时,可能为2^n倍)。
扩容过程:复制所有数据到新的数组 (正是这里会出现多线程导致死循环的问题)。
扩容是一个特别耗性能的操作,所以当程序员在使用HashMap的时候,估算map的大小,初始化的时候给一个大致的数值,避免map进行频繁的扩容。
推荐使用姿势:
当然是 new HashMap<>(size); 固定size啊。这个size的大小是多少呢?那么结合上面所说的知识点,我们了解到,当你能预估数据最大 大小为length时,初始化时大小应该指定的是 size 应为 2^n * 0.75 > length的最小值(不用记,继续往下看)。
如何简化的理解这个初始化容量的公式呢?
其实,当我们使用HashMap(int initialCapacity)来初始化容量的时候,jdk会默认帮我们计算一个相对合理的值当做初始容量。但是这个值并没有考虑到loadFactor负载因子。
也就是说,如果我们设置的默认值是7,经过Jdk处理之后,会被设置成8,但是,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容,这明显是我们不希望见到的。
如果我们通过expectedSize / 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过Jdk处理之后,会被设置成16,这就大大的减少了扩容的几率。
当HashMap内部维护的哈希表的容量达到75%时(默认情况下),会触发rehash,而rehash的过程是比较耗费时间的。所以初始化容量要设置成expectedSize/0.75 + 1的话,可以有效的减少冲突也可以减小误差。
所以,可以认为,当我们明确知道HashMap中元素的个数的时候,把默认容量设置成expectedSize / 0.75F + 1.0F 是一个在性能上相对好的选择,但是,同时也会牺牲些内存。
JDK8中putAll方法中 也是这么实现的,源码如下:
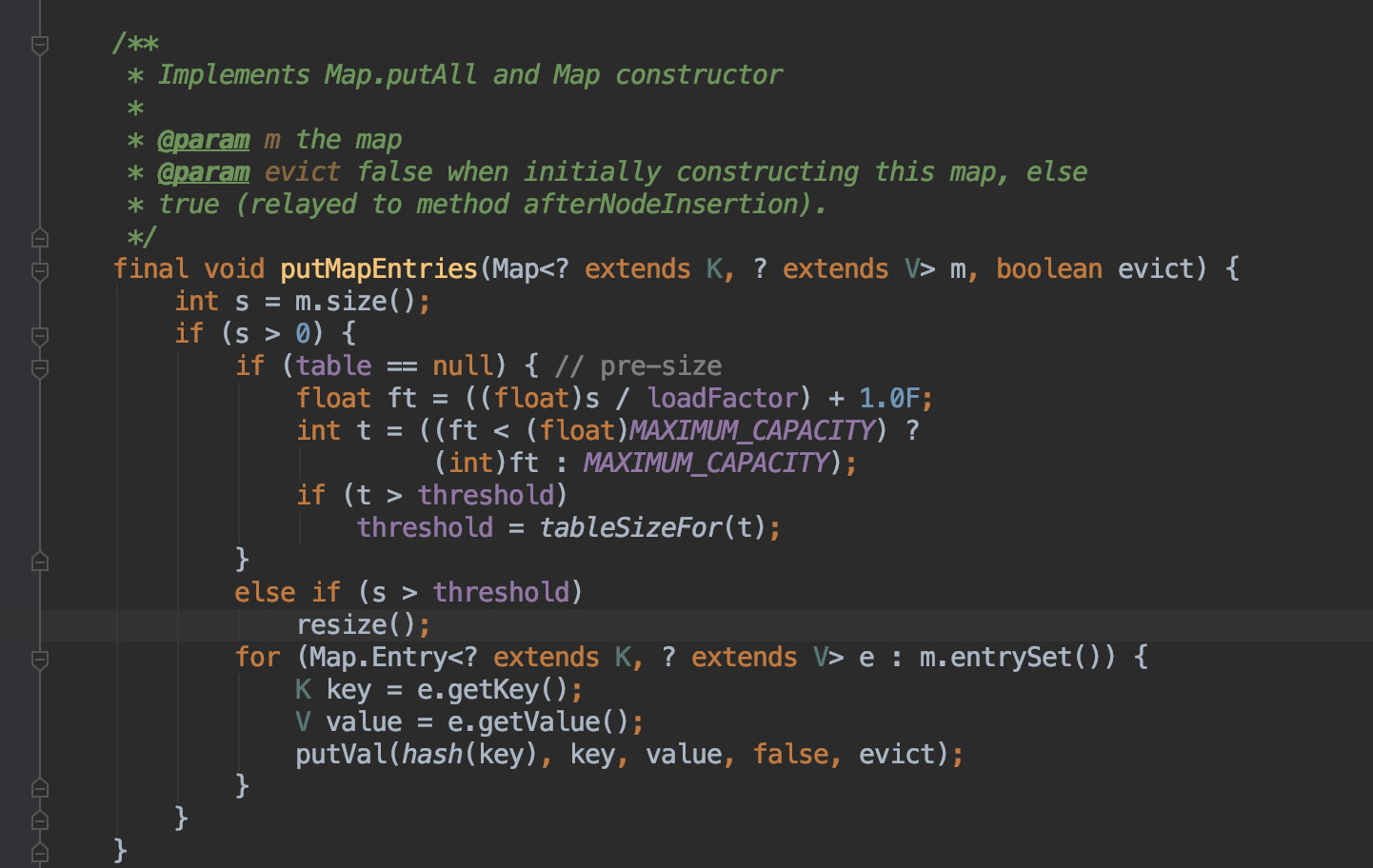
总结一下,在Java中,初始化HashMap 容量时,应该设置为expectedSize / 0.75F + 1.0F 。
咦,等会。你为什么非要强调在Java 中呢?是这样的,如果你使用Kotlin 进行Android开发。推荐你使用Kotlin mapOf () 函数,进行初始化HashMap。mapOf 内部会自动的根据size 去合理的初始化HashMap。源码如下:
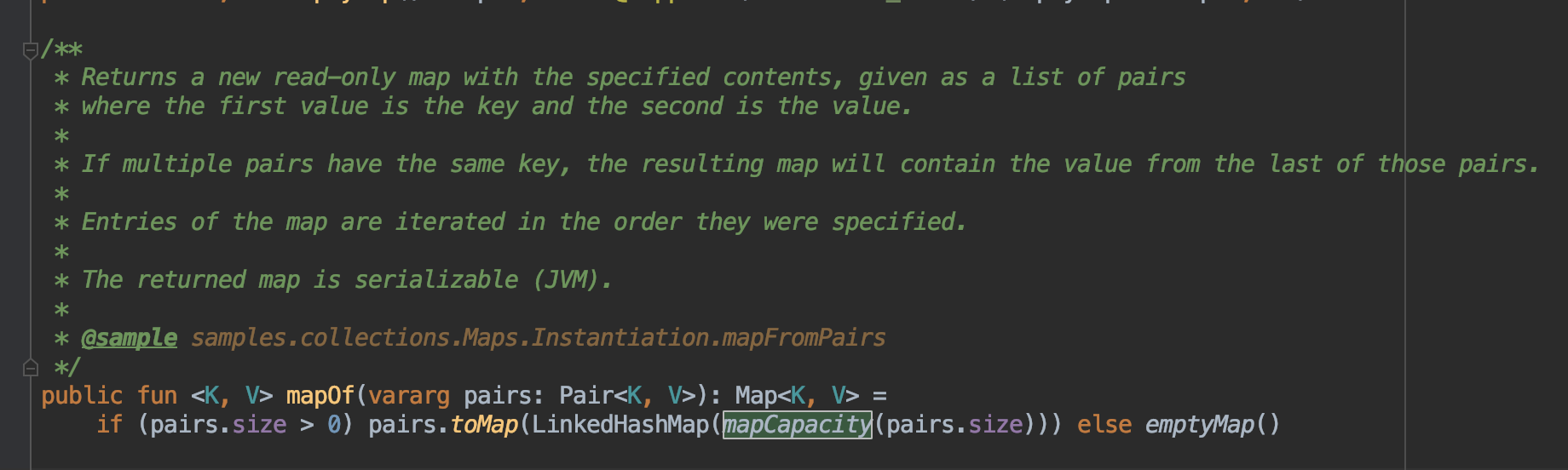
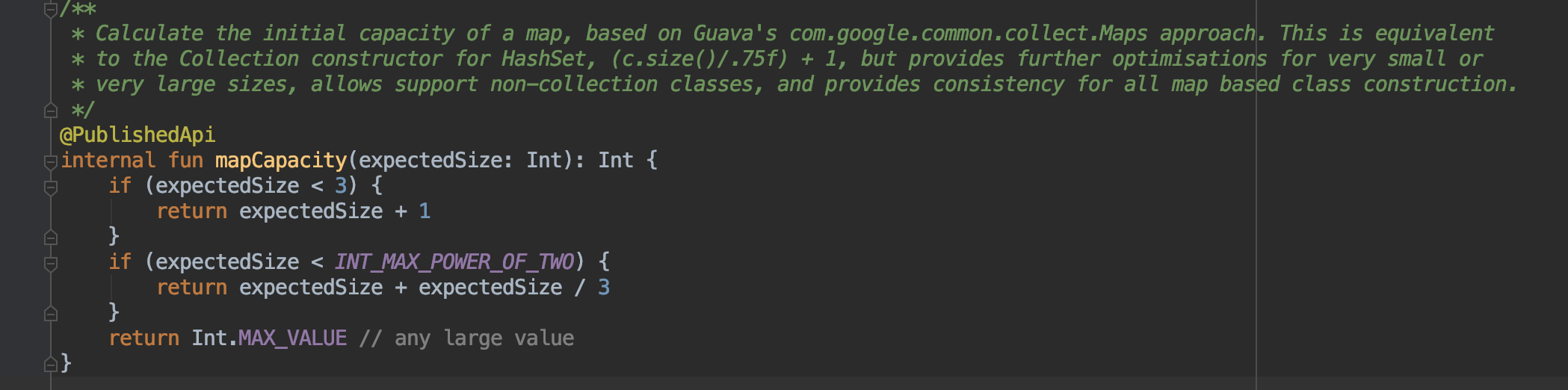
不得不说,kotlin真香!
因此,我们知道了,
例子1中 用法肯定不对的,因为:要么浪费存储空间要么空间不够需要反复扩容。
例子2中 因为有负载因子的存在,用法也不合理的,实际存的数据量达到 "负载因子*当前容量",会导致扩容。
例子3中 这种写法是没什么问题的,因为 6刚刚好等于8*0.75,但是这种写法并不推荐,因为不能确保,填的数字能够小于负载因子*实际容量。
精准指定初始化容量的好处是什么? 避免扩容过程中对性能的损耗,以及充分利用内存。
Demo验证:
说了这么多,谁知道你是不是吹牛?好,上Demo,源码链接
2个小Demo,验证hashMap扩容对性能的影响:
1.固定HashMap容量,避免扩容
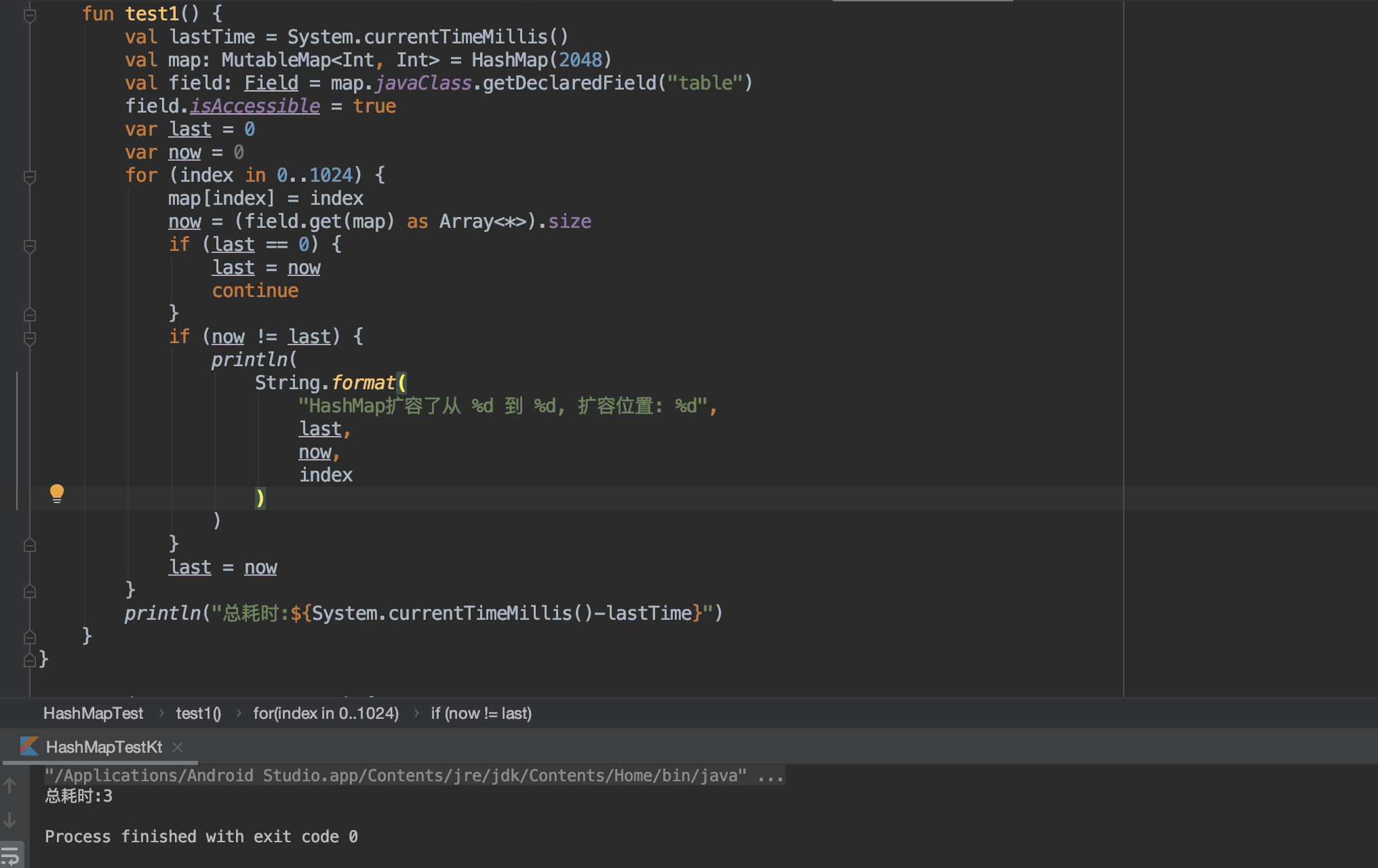
上图可以看出,并没有打印出扩容日志,所以HashMap没有扩容。总耗时为3.
2.不固定HashMap 的容量,让它扩容,查看耗时:
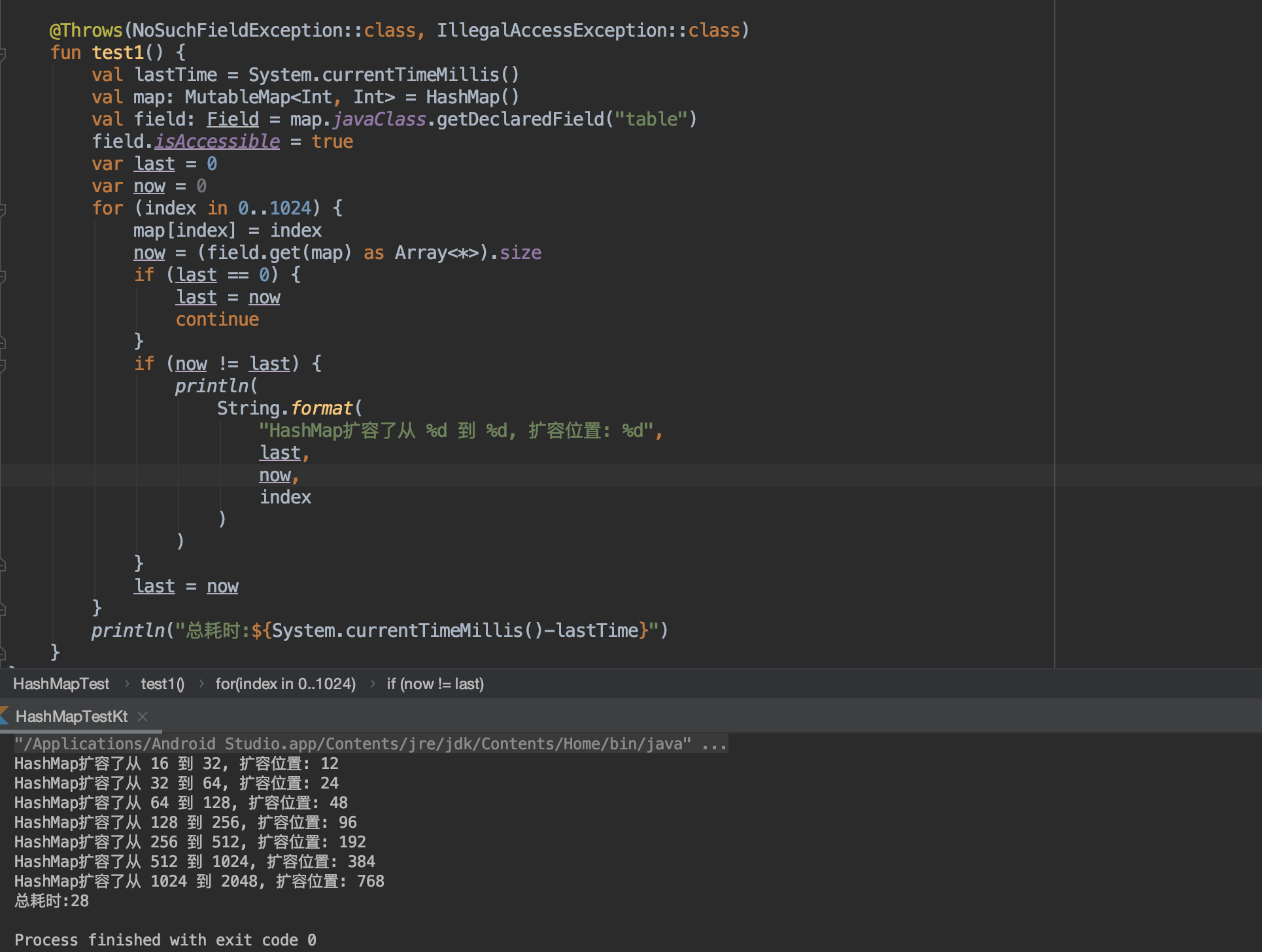
上图可以看出,打印出了扩容日志,总耗时为28.
是的,总共耗时增长约为7倍(注:数据只供举证,没有经过反复实验)。
故:正确而又准确的HashMap初始化方式,能够避免HashMap 扩容,提高系统性能,节省内存空间。
额外思考:
1.一个1000万HashMap,会占用多少空间内存?
答案: 链接
2.HashMap 的负载因子loadFactor 是个float 类型,那么可以大于1吗?
答案:《可以,但是不推荐,因为loadFactor大于1,必然会导致hash碰撞,与使用HashMap的初衷相悖》。
3.不太合理的用法举例3中的用法合理吗?如果合理,原因是什么?什么情景不会不合理?
答案:《设置为6是合理的,当容量设置为 超过负载因子*2^n 是为不合理,因为会触发扩容》。
4.Java 中的 expectedSize / 0.75F + 1.0F 计算初始化长度方法与 kotlin 中 mapCapacity 中的 expectedSize + expectedSize / 3 哪个更合理?
注:欢迎转载,请注明出处。
