

问题描述
在列表中使用key已经是老生常谈的问题了,官方 最佳实践 也大力推荐使用key。。。不对,官方原话是:
在组件上总是必须用 key 配合 v-for,以便维护内部组件及其子树的状态。
既然官方都说的这么中肯了,那么肯定是很重要了。但是,当初不明真相的我,总是觉得写和不写也没啥区别啊,反正都能渲染出来。写着好麻烦啊~🥱,算了,下次,下次一定写。。。
其实之所以看不出来区别是因为一切发生的太快了。。。直到有一天我打了一个断点才发现区别大的不止一点点,事情是这样的
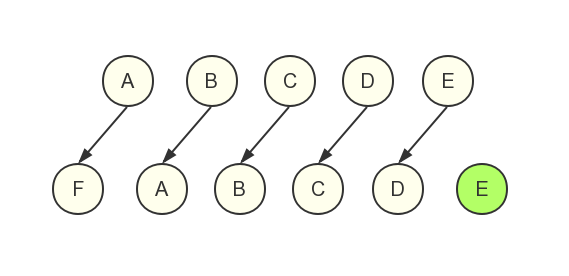
我写了一个下面这样的列表,开始有五个元素,分别是A,B,C,D,E。在组件mount过后两秒向列表头部插入一个元素F,然后对比一下使用key和不使用key的区别
<div id="app">
<ul>
<!-- <li v-for="item in list" :key="item">{{item}}</li>-->
<li v-for="item in list">{{item}}</li>
</ul>
<h2>不使用key,仔细看上面元素的变化</h2>
</div>
const app = new Vue({
data() {
return {
list: ['A', 'B', 'C', 'D', 'E']
}
},
el: '#app',
mounted() {
setTimeout(() => {
this.list.unshift('F')
}, 2000)
}
})
不使用key
使用key

区别
- 在不使用key的时候,一共进行了五次更新操作和一次新建插入(元素E)操作
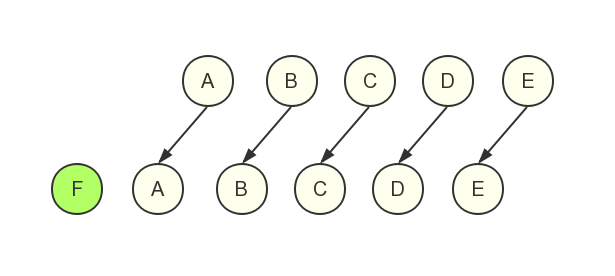
- 使用key时,只做了一次新建插入(元素F)操作
问题分析
聪明的你可能会问了,为什么呢?
我们知道,虚拟dom是一个树结构,当组件数据变化时会执行组件的patchVnode方法,然后按照深度优先,同层比较的原则进行diff。如果新老节点都有子节点,则调用updateChildren方法进行子节点的比较,虚拟dom diff的核心算法就在这个方法里面。
vue中的虚拟dom 补丁算法是在 snapdom 的基础上改造而来,最主要的优化就包括针对web场景,在web中,我们最多进行的操作是在队尾或者队首插入元素,在遍历查找新的元素对应的老元素之前,先进行新老首尾2x2=4次盲猜。
为了方便查看,我会在下面源码中插入相关注释
function updateChildren (parentElm, oldCh, newCh, insertedVnodeQueue, removeOnly) {
let oldStartIdx = 0
let newStartIdx = 0
let oldEndIdx = oldCh.length - 1
let oldStartVnode = oldCh[0]
let oldEndVnode = oldCh[oldEndIdx]
let newEndIdx = newCh.length - 1
let newStartVnode = newCh[0]
let newEndVnode = newCh[newEndIdx]
let oldKeyToIdx, idxInOld, vnodeToMove, refElm
const canMove = !removeOnly
if (process.env.NODE_ENV !== 'production') {
checkDuplicateKeys(newCh)
}
// 如果新老任何一组元素的游标重合,就结束循环
while (oldStartIdx <= oldEndIdx && newStartIdx <= newEndIdx) {
if (isUndef(oldStartVnode)) {
oldStartVnode = oldCh[++oldStartIdx] // Vnode has been moved left
} else if (isUndef(oldEndVnode)) {
oldEndVnode = oldCh[--oldEndIdx]
// 针对web中常见操作,在遍历查找新的元素对应的老元素之前,先进行新老首尾2x2=4次盲猜
// 对比新开始和老开始
} else if (sameVnode(oldStartVnode, newStartVnode)) {
patchVnode(oldStartVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldStartVnode = oldCh[++oldStartIdx]
newStartVnode = newCh[++newStartIdx]
// 对比新结束和老结束
} else if (sameVnode(oldEndVnode, newEndVnode)) {
patchVnode(oldEndVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
oldEndVnode = oldCh[--oldEndIdx]
newEndVnode = newCh[--newEndIdx]
// 对比新结束和老开始
} else if (sameVnode(oldStartVnode, newEndVnode)) { // Vnode moved right
patchVnode(oldStartVnode, newEndVnode, insertedVnodeQueue, newCh, newEndIdx)
canMove && nodeOps.insertBefore(parentElm, oldStartVnode.elm, nodeOps.nextSibling(oldEndVnode.elm))
oldStartVnode = oldCh[++oldStartIdx]
newEndVnode = newCh[--newEndIdx]
// 对比新开始和老结束
} else if (sameVnode(oldEndVnode, newStartVnode)) { // Vnode moved left
patchVnode(oldEndVnode, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
canMove && nodeOps.insertBefore(parentElm, oldEndVnode.elm, oldStartVnode.elm)
oldEndVnode = oldCh[--oldEndIdx]
newStartVnode = newCh[++newStartIdx]
} else {
// 都没有命中,创建一个老节点索引和key的映射表,循环查找
if (isUndef(oldKeyToIdx)) oldKeyToIdx = createKeyToOldIdx(oldCh, oldStartIdx, oldEndIdx)
idxInOld = isDef(newStartVnode.key)
? oldKeyToIdx[newStartVnode.key]
: findIdxInOld(newStartVnode, oldCh, oldStartIdx, oldEndIdx)
if (isUndef(idxInOld)) { // New element
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
} else {
vnodeToMove = oldCh[idxInOld]
if (sameVnode(vnodeToMove, newStartVnode)) {
patchVnode(vnodeToMove, newStartVnode, insertedVnodeQueue, newCh, newStartIdx)
oldCh[idxInOld] = undefined
canMove && nodeOps.insertBefore(parentElm, vnodeToMove.elm, oldStartVnode.elm)
} else {
createElm(newStartVnode, insertedVnodeQueue, parentElm, oldStartVnode.elm, false, newCh, newStartIdx)
}
}
newStartVnode = newCh[++newStartIdx]
}
}
// 当循环结束,如果新的列表里面还有没处理的元素,就全部创建新增
if (oldStartIdx > oldEndIdx) {
refElm = isUndef(newCh[newEndIdx + 1]) ? null : newCh[newEndIdx + 1].elm
addVnodes(parentElm, refElm, newCh, newStartIdx, newEndIdx, insertedVnodeQueue)
} else if (newStartIdx > newEndIdx) {
// 如果老的列表里还有没处理的元素,就全部删除
removeVnodes(oldCh, oldStartIdx, oldEndIdx)
}
}
讲到这里大家可能还是不明白为什么要用key呢,其实答案就在盲猜时执行的sameVnode方法,废话不多说,直接看代码!
// 判断两个vnode是否是相同vnode
function sameVnode (a, b) {
return (
a.key === b.key && (
(
a.tag === b.tag &&
a.isComment === b.isComment &&
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b)
) || (
isTrue(a.isAsyncPlaceholder) &&
a.asyncFactory === b.asyncFactory &&
isUndef(b.asyncFactory.error)
)
)
)
}
当我们在列表开头插入一个F元素时,如果不使用key,则key等于undefined,而undefined===undefined恒成立,并且tag都是li,都不是注释节点,所以会把新插入的F(newStartVnode)和老的A(oldStartVnode)认为是同一个节点执行更新,游标向后移动一位,并且后续4个元素都按照这种逻辑更新,最后老节点先结束了(游标先重合),新节点还剩一个元素E,就创建一个新的节点并插入,最终一共进行了五次更新操作和一次新建插入(元素E)操作。
如果我们使用了key,对比newStartVnode 和 oldStartVnode时发现key不同,不是同一个元素,就继续对比oldEndVnode newEndVnode发现他们key相同,都为E,并且文本内容和其他属性也没变,就直接复用然后游标向前移动一位,最后老节点先结束了(游标先重合),新节点还剩一个元素F,就创建一个新的节点并插入。最终只进行了一次新建插入(元素F)操作
引申
使用key除了提高性能以外,还有一些其他的使用场景,例如:
- 当你想为一个元素添加动画,比如上下移动,如果没有使用key,这个元素很有可能在
updateChildren时被替换了,那么元素的动画可能不会完整的展示 - 当你在一个input上获取焦点后,如果没有使用key,经过
updateChildren更新后,可能会失去焦点 - 其他因为dom顺序改变可能造成的bug

解决上述问题最直接最有效的办法就是为元素增加key
PS:下次一定要写key 😂
最后,这篇文章属于 从源码解惑 系列文章中的一篇,欢迎大家关注、留言、拍砖
