一个分词器tokenizer接收一个字符流,将之分割为独立的tokens词元。 对于中文,一般选择ik分词器。
0. 安装ik分词器
github.com/medcl/elast… 下载对应的版本zip,在数据卷plugins目录下mkdir ik,然后unzip,解压文件移动到ik目录下,然后重启es容器。 验证是否安装成功:docker exec -it 69 /bin/bash -- > ./bin/elasticsearch-plugin list,会显示安装成功的插件。
1. ik分词器基本知识
ik常用的两种分词器:ik_smart,ik_max_word
POST _analyze
{
"analyzer": "ik_smart",
"text": "戴尔显示器"
}
---- result:
{
"tokens" : [
{
"token" : "戴尔",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "显示器",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
}
]
}
POST _analyze
{
"analyzer": "ik_max_word",
"text": "戴尔显示器"
}
--- result:
{
"tokens" : [
{
"token" : "戴尔",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "显示器",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "显示",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "器",
"start_offset" : 4,
"end_offset" : 5,
"type" : "CN_CHAR",
"position" : 3
}
]
}
2. 自定义分词扩展词库
方式1:自己写一个项目,作为词库,让es去请求 方式2:词库放到nginx中,让es去请求
2.1 创建nginx容器
https://juejin.cn/post/6844904034172665870
2.2 创建分词库
/docker/nginx/html/es$ sudo vi fenci.txt
## 如果中文乱码,修改一下default.conf字符集。
2.3 es配置分词器地址
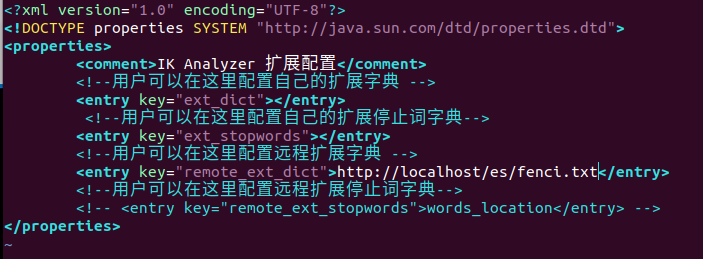
/docker/elasticsearch/volume/plugins/ik/config# vim IKAnalyzer.cfg.xml
## 然后重启