



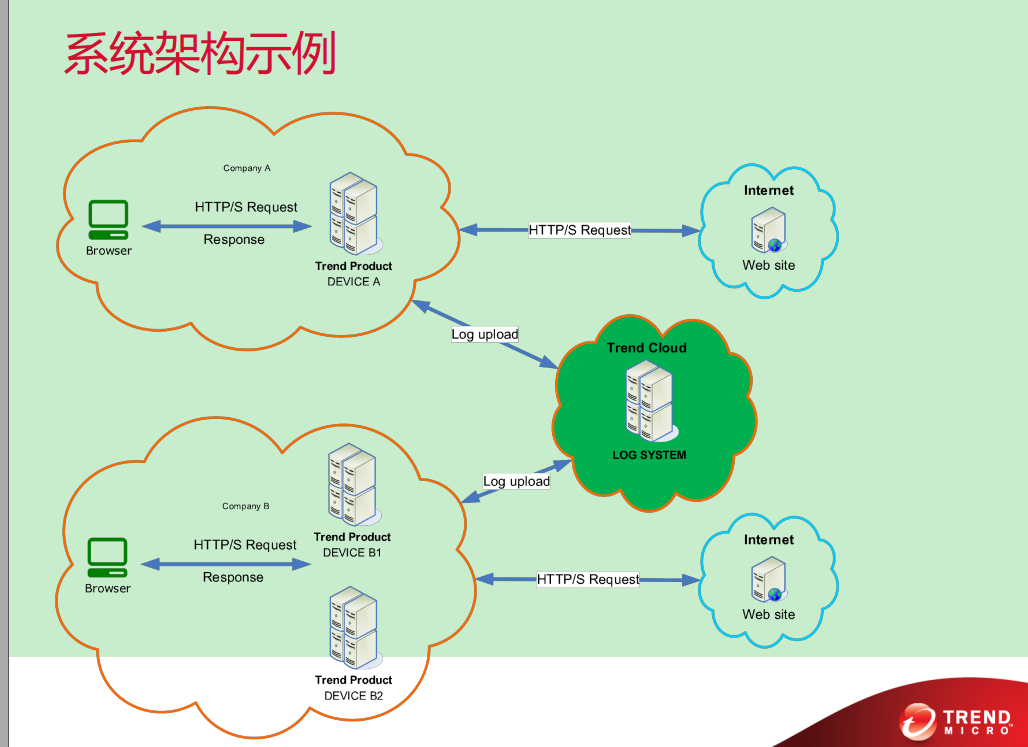
一、Kafka日志写入性能分析
每天总日志条数:3000250000=750000000(七亿五千万)条。 一天的有效流量时间不能算满24小时,夜晚一般流量比较少。一般可以算作10小时左右。 每秒日志量:750000000÷(360010)≈21000条/秒 Kafka单机每秒10万次写入无压力,所以写入消息不会存在性能瓶颈问题。
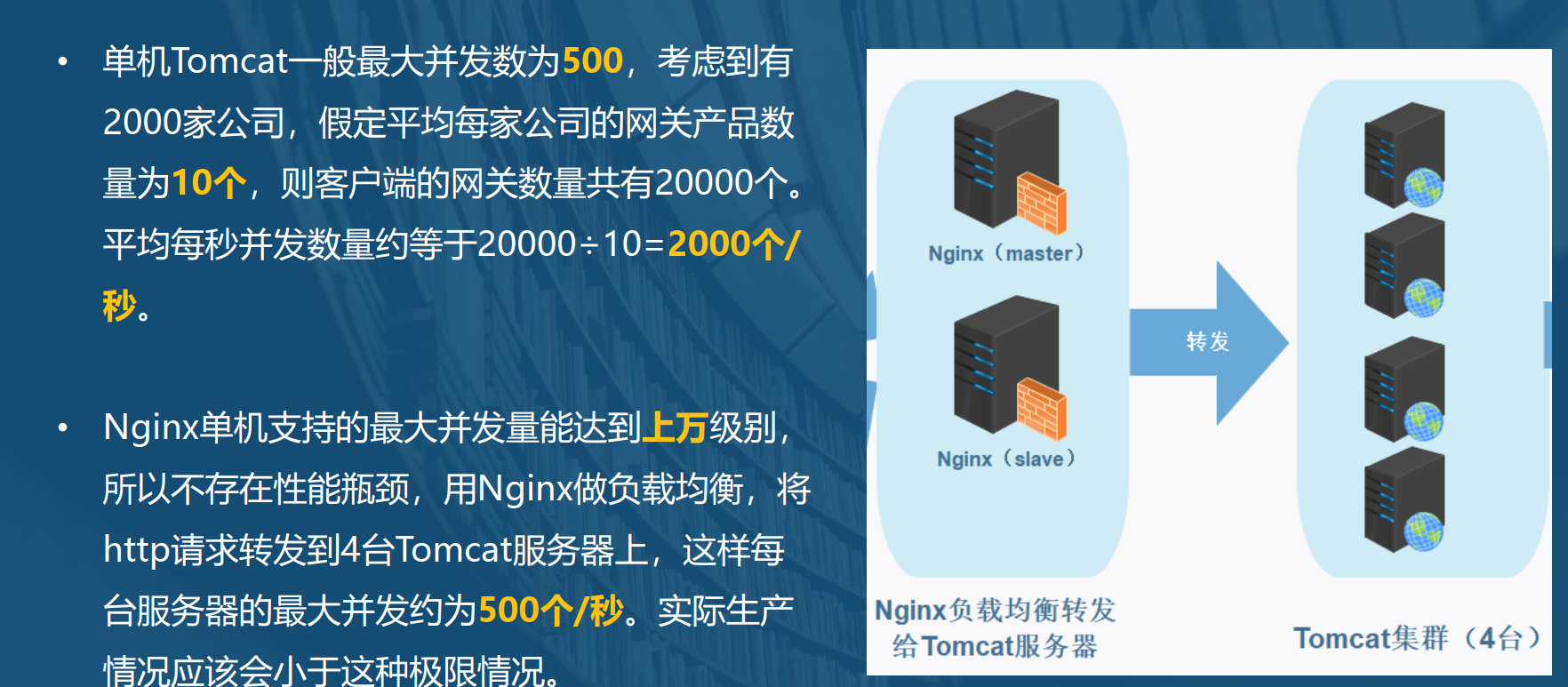
二、Tomcat性能分析
单机Tomcat一般最大并发数为500,考虑到有2000家公司,假定平均每家公司的网关产品数量为10,则客户端的网关数量共有20000个。平均每秒并发数量约等于20000÷10=2000个/秒。nginx单机支持的最大并发量能达到上万级别,所以不存在性能瓶颈,用nginx做负载均衡,将http请求转发到4台Tomcat服务器上,这样每台服务器的最大并发约为500个/秒。实际生产情况应该会小于这种极限情况。
三、ElasticSearch性能分析
单机ES的存储容量能达到0.5T~1T,根据业务需求,需要存储半年的日志信息。 半年需要存储的日志条数:7.510^8630=1.3510^11(条) 假设每条日志信息约为50字节,则半年存储需要的容量约为:6TB。 所以单机的ES无法满足业务需求,需要将ES扩展成集群。 ES集群需要最少10台服务器来保证查询效率。
四、活跃用户定义
可以将每个公司平均访问次数前30%的用户定义为活跃用户。这样我们只需要在log日志字段中新增一个访问次数字段,就能根据这个字段从大到小按公司分组排序查询出活跃用户。查询的时候只有是用户名和ip都存在的记录才算作有效记录。
五、系统的高可用分析
首先在nginx处做了一个主从复制,这样可以保证nginx的高可用。如果主nginx宕机了,从机会立马开始工作。 其次在Kafka消息队列也做了一个主从配置,也可以保证Kafka的高可用。 最后Kibana可视化查询日志界面也做了一个主从复制,保证Kibana的高可用。 另外如果条件允许,还可以考虑系统的容灾,异地多活,这样系统的可用性就更高。
我的设计:
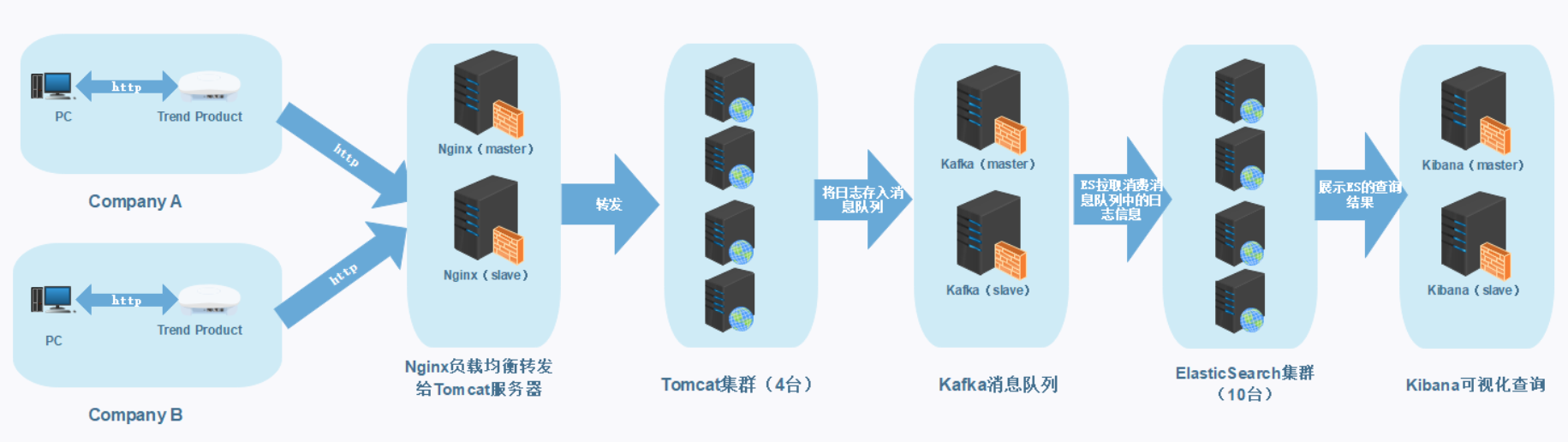





系统完善建议:
- 1.在log字段中可以直接添加每台机器的MAC信息,这样即使用户不认证也能获取到对应机器的流量信息。
- 2.将数据做冷热分离。最近一个月的数据放入ES集群中,往前的数据可以存储到云端服务器。
- 3.考虑系统的可扩展性
- 4.考虑网关的安全性,对恶意流量进行监视。

