

ECCV 2018
Chang Chen,Zhiwei Xiong,Xinmei Tian, Feng Wu
简介
文章使用了基于boosting的多轮迭代去雾算法,并在此基础上迭代联合训练,其网络权重并未共享。
Motivation
Boosting去噪背景知识
去噪问题的目标是从中恢复
,
用公式可以表达为:
其中表示服从高斯分布的噪声。而去噪可以表达为:
其中表示普通的去噪方法,
表示
的近似。由于算法不是完美的,因此
也不能完全等于
,它们之间的差距可以表达为:
其中表示未恢复的图像(信号),
表示
中剩余的噪声。换句话说,
减去剩余的噪声
加上未恢复的图像(信号)
就能得到完全恢复的图像。
有一种将boosting算法应用于去噪的简单想法是,从残差中迭代提取未恢复的图像(信号)再加回
:
其中是迭代提取符号,并将
设置为0。但注意到,残差
不仅包含一部分未恢复的图像(信号)
,还包含一部分噪声:
很自然的,能够出现另外一个想法,迭代去噪图像结果来消除残留的噪声
:
其中代表某降噪模型。但是由于它忽略了包含大多数高频信息的
,而会导致过度平滑。
为了进一步提高Boosting框架的性能,Romano和Elad提出了一种SOS算法。每个迭代步骤中的降噪目标是增强图像,而不是增强残差
或者
,但是为了保证SOS的可迭代性,它必须在每个步骤中减去相同的
:
其中是一种降噪模型。进一步说,可以将
分解为:
假设,
。根据Cauchy-Schwarz不等式,可以得到
。
其中,公式(7)中,为了维护SOS的可迭代性,减去了,但在深度学习中,可以在没有这种约束下学习:
Model
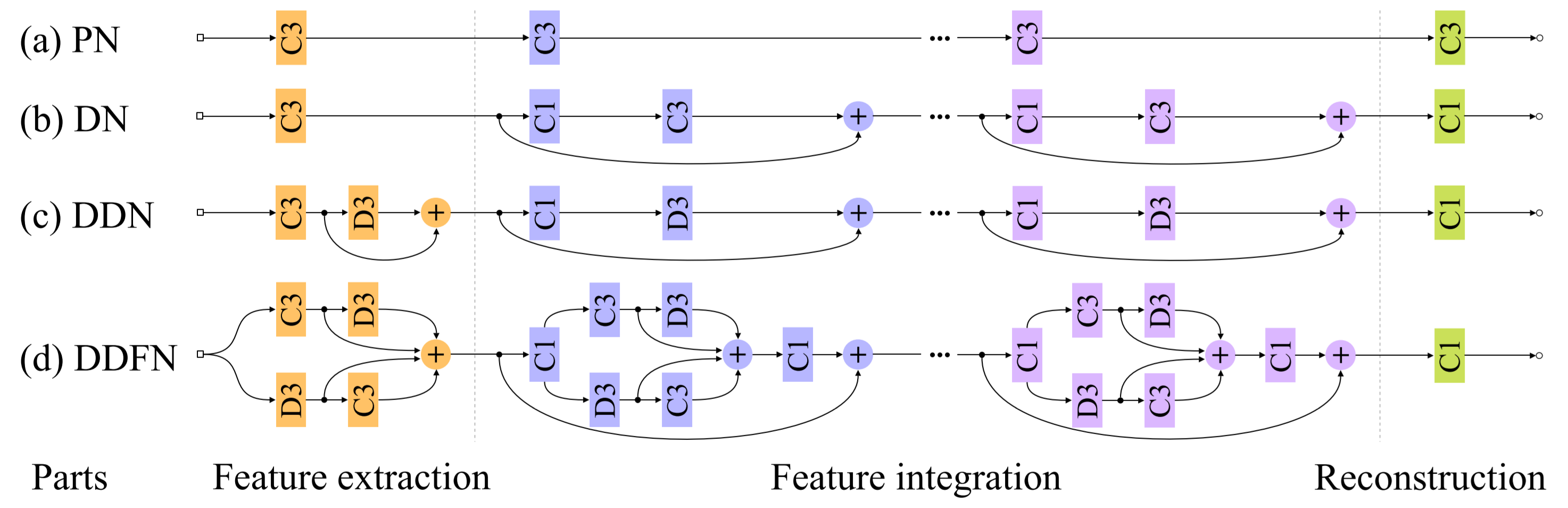
上图展示的网络结构为公式(9)中的一个去噪步骤,并非全部。
对比和测试
结果展示



