

"
楚王虽雄难免乌江自刎,
汉王虽弱却有万里江山。
天不得时,日月无光。
地不得时,草木不长。
水不得时,风浪不止。
人不得时利运不通。
有先贫而后富,有先富而后贫。
此乃天理循环,周而复始者也。
所以大家一定要坚持住了。
"

大数据的在项目中应用场景,要进行大数据相关的性能测试以及要做哪些性能测试,现在的企业中都应用了哪些大数据相关的技术,大数据的实时数据流式处理架构,能够针对纯后端应用进行性能测试,并且能够举一反三的对任意软件模块进行性能测试。如何站在数据角度拆分软件架构,如何使用jmeter进行大数据性能
8.1 大数据技能树及应用场景
大数据技能树
-
存储:
- hbase:是分布式、面向列族的开源数据库,HDFS为HBase提供可靠的底层数据存储服务,MapReduce为HBase提供高性能的计算能力,Zookeeper为HBase提供稳定服务和Failover机制,可以说,HBase是一个通过大量廉价的机器解决海量数据的高速存储和读取的分布式数据库解决方案。
- hive:白话一点再加不严格一点,hive可以认为是map-reduce的一个包装。hive的意义就是把好写的hive的sql转换为复杂难写的map-reduce程序
- hdfs:是一个运行在商业 PC 上的分布式文件系统,HDFS的主要目的是为了解决大规模数据存储和管理的问题
-
数据传输:
- flume:是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力。
- kafka:是一个分布式的,支持多分区、多副本,基于 Zookeeper 的分布式消息流平台,它同时也是一款开源的基于发布订阅模式的消息引擎系统
-
实时计算:
- storm:Storm是一个免费并开源的分布式实时计算系统。利用Storm可以很容易做到可靠地处理无限的数据流,像Hadoop批量处理大数据一样,Storm可以实时处理数据。Storm简单,可以使用任何编程语言。
- spark:spark是一个实现快速通用的集群计算平台。它是由加州大学伯克利分校AMP实验室 开发的通用内存并行计算框架,用来构建大型的、低延迟的数据分析应用程序。它扩展了广泛使用的MapReduce计算 模型。高效的支撑更多计算模式,包括交互式查询和流处理。spark的一个主要特点是能够在内存中进行计算,及时依赖磁盘进行复杂的运算,Spark依然比MapReduce更加高效。
-
语言: java、python、 scala
-
集群调度: zookeeper
大数据应用场景
- 运营支撑:数据仓库、BI
- 风控支撑:实时计算、数据实时分析
- 营销支撑:精准营销、实时推荐
8.2 大数据实时数据处理架构介绍
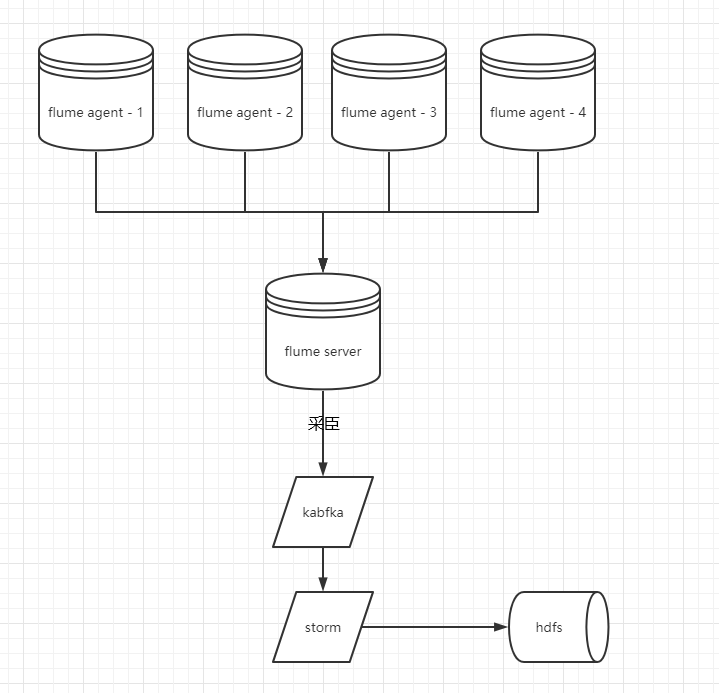
- 如何测试
- 日志收集约定好格式
- 写代码造日志数据,kafka是否能够接收
- kabfka生成数据--->storm,写入数据
- 了解架构,拆分处理
8.3 实时数据处理三大框架介绍
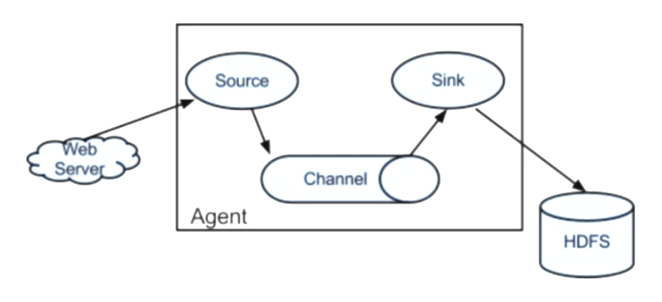
实时数据处理技术flume介绍
- Flume:高可用的,可靠的,分布式海量日志采集、聚合和传输的系统
- 实时数据处理技术flume架构
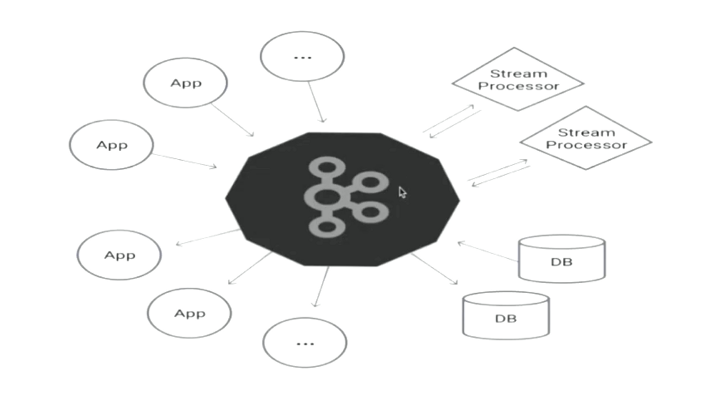
实时数据处理技术kafka介绍
-
kafka :是一种高吞吐量的分布式发布订阅消息系统,它可以处理消 费者规模的网站中的所有动作流数据
-
实时数据处理技术kafka框架
-
实时数据处理技术kafka术语
- Broker: Kafka集群包含一个或多 个服务器,这种服务器被称为 broker
- Topic: 每条发布到Kafka集群的消息都有一个类别, 这个类别被称 为Topic。
- Partition: 物理上的概念,每个Topic包含一个或多个Partition
- Producer: 负责发布消息到Kafka broker
- Consumer: 消息消费者, 向Kafka broker读取消息的客户端。
- Consumer Group: 每个Consumer属于一一个特定的Consumer Group
-
Kafka的基本操作
-
启动
- 启动zookeeper bin/zookeeper-server-start.sh start
- 启动kafka bin/kafka-server-start.sh config/server.properties &
-
topic操作
- 查看topic : ./kafka-topics.sh --list -- zookeeper localhost:2181
- 创建topic : bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 4 --topic topic1
-
topic操作
- artitions指定topic分区数
- eplication-factor指定topic每个分区的副本数
-
生产与消费
- 生产者: ./kafka-console-producer.sh --broker-list localhost:9092 --topic topic1
- 消费者: ./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic topic1
-
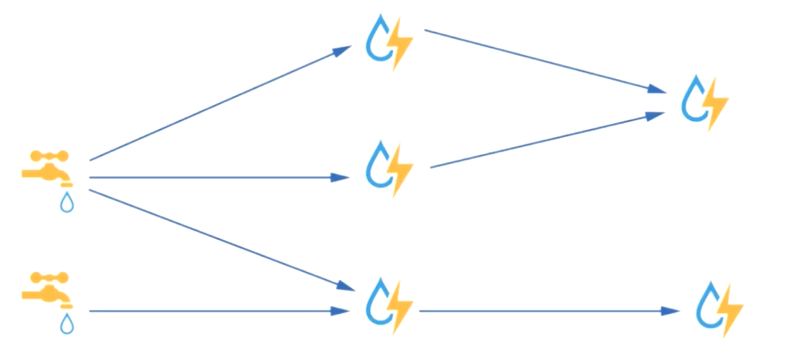
实时数据处理技术storm介绍
- Storm是一种分布式,实时的数据处理框架,延时时长为毫秒 级,而Spark Streaming为秒级,是目前最适用于流式数据处 理,最好的框架之一。
像水龙头一样,不能停顿
8.4 大数据测试环境搭建
- 下载kafka(本次下载版本2.12)
- 下载ZooKeeper(本次下载版本3.4.6) zookeeper.apache.org/releases.ht…
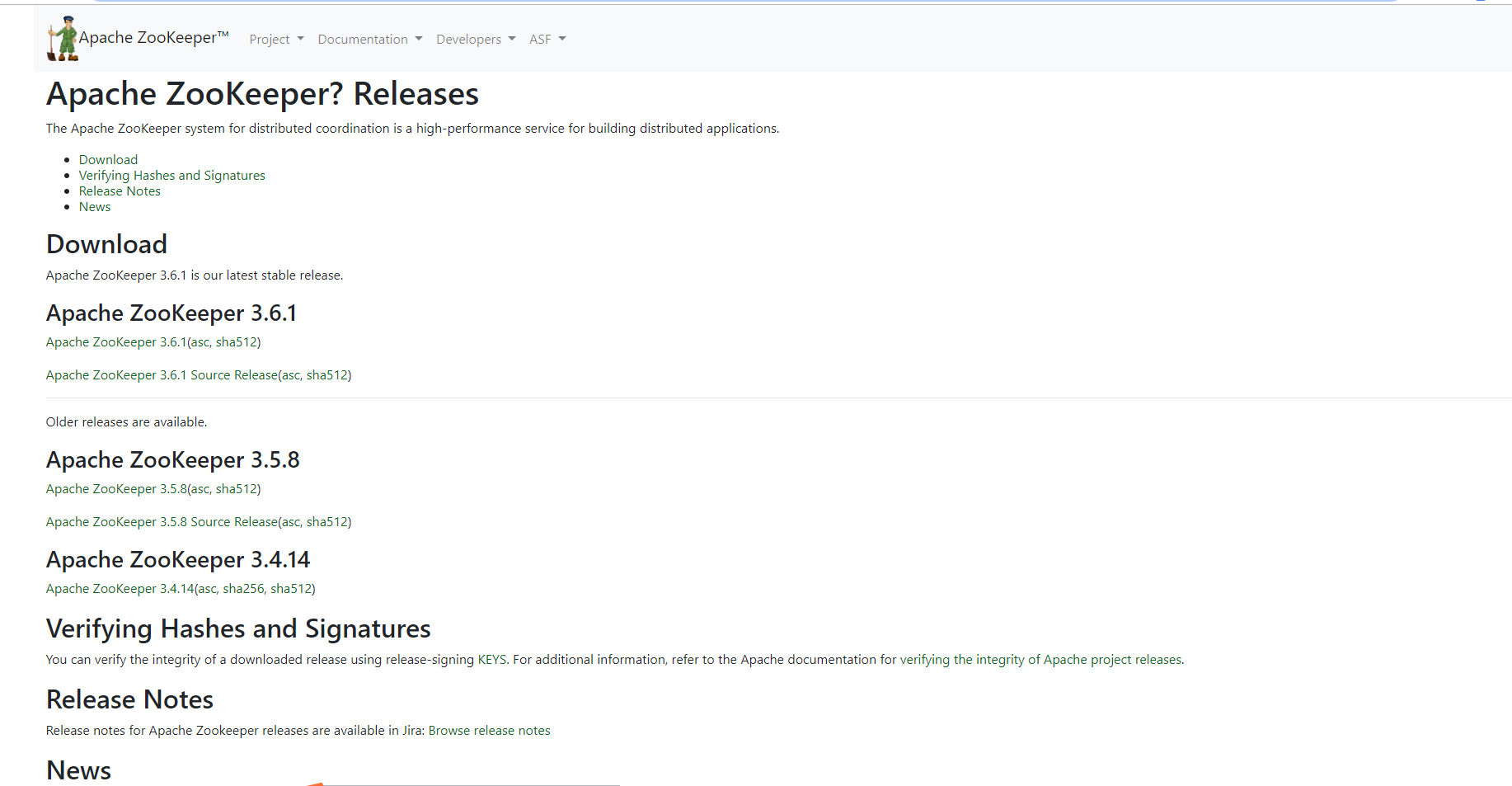
- 存放至Liunx 这里我存放到了home目录下
1.修改zookeeper配置命名:zookeeper-3.4.5/conf/
mv zookeeper.cfg zoo.cfg
2.启动zookeeper:
./启动zookeeper-3.4.5/bin/zkServer.sh start
3.启动kafka
# 修改配置
vim kafka_XXXXXX/config/server.properties
如果zookeeper和kafka没在一起需要修改
zookeeper.connect=localhost:2181
日志输出路径
log.dirs=/tmp/kafka-logs
集群配置
broker.id=0
advertised.host.name=localhost # 本地发送接收消息
启动
./bin/kafka-server-start.sh config/server.properties
创建生产者消费者
-
查看topic
cd /home/kafka_ 2.12-0.10.2.0/bin
./kafka-topics.sh --list --zookeeper localhost:2181
-
创建topic
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 2 --partitions 4 --topic topic1
利用上边查看命令看是否创建成功
-
创建消费者: ./kafka-console-consumer.sh --zookeeper localhost:2181 --from-beginning --topic topic1
-
创建生产者: ./kafka-console-producer.sh --broker-list localhost:9092 --topic topic1
发送消息
-
去消费者查看是否存在,存在即环境搭建完毕
8.5 大数据性能测试实战
写代码建议在idea或者工具中编写后复制到jmeter中,这样不容易出错
- 引包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>0.10.2.0</version>
</dependency>
- 配置信息核对

重启程序
1.zookeeper
2.kafka
3.消费者
- 创建类
package com.kafka;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
public class kafkaProduverMsg {
public static void main(String[] args) {
//配置文件
Properties properties = new Properties();
//指定kafka配置
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.7:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者
Producer producer = new KafkaProducer(properties);
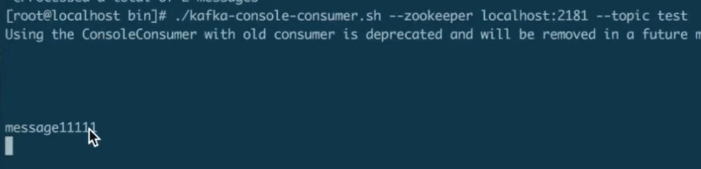
producer.send(new ProducerRecord("test","message11111"));
producer.close();
}
}
-
查看结果
-
向Jmeter中粘贴代码
- .m2\repository\org\apache\kafka\kafka-clients\0.10.2.0\kafka-clients-0.10.2.0.jar 复制到Jmeter目录 ext目录下
- 粘贴代码到Jmeter BeanShell Sampler,选择性粘贴 不需要main方法
配置信息 和发送消息 可以独立出来,参数化等
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.Producer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
//配置文件
Properties properties = new Properties();
//指定kafka配置
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"192.168.1.7:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//创建生产者
Producer producer = new KafkaProducer(properties);
producer.send(new ProducerRecord("test","message22222"));
producer.close();
好了各位,以上就是这篇文章的全部内容了,能看到这里人啊,都是人才。
如果这个文章写得还不错,觉得「王采臣」我有点东西的话 求点赞👍求关注❤️求分享👥 对耿男我来说真的非常有用!!!
白嫖不好,创作不易,各位的支持和认可,就是我创作的最大动力,我们下篇文章见!
王采臣 | 文 【原创】 如果本篇博客有任何错误,请批评指教,不胜感激 ! 微信公众号:
又到半夜了,好累晚安~

