

1. 路由
1.1 什么是路由:
路由就是URL到函数的映射
/users -> getAllUsers()
/users/count -> getUsersCount()
这是两条路由,当访问 /users 的时候,会执行 getAllUsers() 函数;当访问 /users/count 的时候,会执行 getUsersCount() 函数。
而 router 可以理解为一个容器,或者说一种机制,它管理了一组 route。简单来说,route 只是进行了URL和函数的映射,而在当接收到一个URL之后,去路由映射表中查找相应的函数,这个过程是由 router 来处理的。一句话概括就是 "The router routes you to a route"。
1.2 服务器端路由
对于服务器来说,当接收到客户端发来的HTTP请求,会根据请求的URL,找到相应的映射函数,然后执行该函数,并将函数的返回值发送给客户端。对于静态资源服务器,可以认为,所有URL的映射函数就是一个文件的读取操作。对于动态资源,映射函数可能是一个数据库的读取操作,也可能是进行一些数据处理等等。
例如:
app.get('/', (req, res) => {
res.sendFile('index')
})
app.get('/users', (req, res) => {
db.queryAllUsers()
.then(data => res.send(data))
})
- 当访问/的时候,会返回index页面
- 当访问/users的时候,会从数据库中取出所有用户数据并返回
不仅仅是URL
在 router 匹配 route 的过程中,不仅会根据URL来匹配,还会根据请求的方法来看是否匹配。例如上面的例子,如果通过 POST 方法来访问 /users,就会找不到正确的路由。
1.3 客户端路由
客户端(通常是浏览器),路由的映射函数通常是进行一些DOM的显示和隐藏操作。这样,当访问不同的路径的时候,会显示不同的页面组件。客户端路由最常见的有以下两种实现方案:
- 基于Hash
- 基于History API
Hash
URL中 # 及其后面的部分为 hash。例如:
const url = require('url')
var a = url.parse('http://example.com/#/foo/bar')
console.log(a.hash)
// => #/foo/bar
hash仅仅是客户端的一个状态,当向服务器发请求的时候,hash部分并不会发过去。
通过监听 window 对象的 hashChange 事件,可以实现简单的路由。例如:
window.onhashchange = function() {
var hash = window.location.hash
var path = hash.substring(1)
switch (path) {
case '/':
showHome()
break
case '/users':
showUsersList()
break
default:
show404NotFound()
}
}
History API
通过HTML5 History API可以在不刷新页面的情况下,直接改变当前URL
可以通过监听 window 对象的 popstate 事件,来实现简单的路由:
window.onpopstate = function() {
var path = window.location.pathname
switch (path) {
case '/':
showHome()
break
case '/users':
showUsersList()
break
default:
show404NotFound()
}
}
但是这种方法只能捕获前进或后退事件,无法捕获 pushState 和 replaceState
1.4 动态路由
上面提到的例子都是静态路由。但是有时候我们需要在路径中传入参数,例如获取某个用户的信息,我们不可能为每个用户创建一条路由,而是在通过捕获路径中的参数(例如用户id)来实现。
2. 高并发Web系统(单机到分布式集群)
在Web系统的访问量越来越高的过程中,系统承受的压力越来越大,需要再Web系统架构层面搭建多个层次的缓存机制。在不同的压力阶段,通过搭建不同的服务和架构来解决。
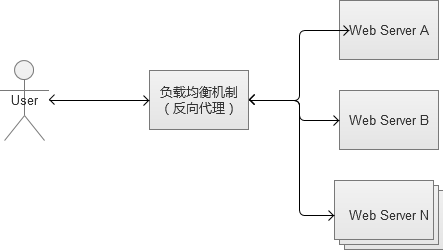
2.1 Web负载均衡
Web负载均衡(load balancing),简单地说就是给我们的服务器集群分配“工作任务”,采取恰当的分配方式,对于保护处于后端的Web服务器来说,非常重要。
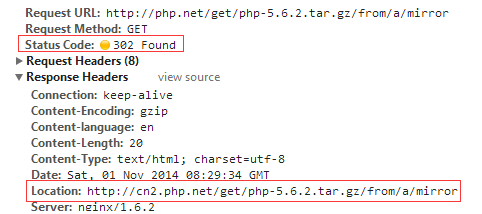
1.HTTP重定向
当用户发来请求的时候,Web服务器通过修改HTTP响应头中的Location标记来返回一个新的url,然后浏览器再继续请求这个新url,实际上就是页面重定向。通过重定向,来达到“负载均衡”的目标。例如,我们在下载PHP源码包的时候,点击下载链接时,为了解决不同国家和地域下载速度的问题,它会返回一个离我们近的下载地址。重定向的HTTP返回码是302,如下图:
2. 反向代理负载均衡
反向代理服务的核心工作主要是转发HTTP请求,扮演了浏览器端和后台web服务器中转的角色。因为它工作在HTTP层(应用层),常见的反向代理软件如Ngnix。
Ngnix是一种非常灵活的反向代理软件,可以自由定制化转发策略,分配服务器流量的权重等。反向代理中,常见的一个问题,就是web服务器存储的session数据,因为一般负载均衡的策略都是随机分配请求的。同一个登录用户的请求,无法保证一定分配到相同的web机器上,会导致无法找到session的问题。
解决的方案主要有两种:
- 配置反向代理的转发规则,让同一个用户的请求一定落在同一台机器上(通过分析cookie),复杂的转发规则将会消耗更过的CPU,也增加了代理服务器的负担。
- 将session这类的信息,专门用某个独立的服务来存储,例如redis/memcache,这个方案是比较推荐的。
反向代理服务,也是可以开启缓存的,如果开启了,会增加反向代理的负担,需要谨慎使用。这种负载均衡策略实现和部署非常简单,而且性能表现也比较好。但是,它有“单点故障”的问题,如果挂了,会带来很多的麻烦。而且,到了后期Web服务器继续增加,它本身可能成为系统的瓶颈。
3. IP负载均衡
IP负载均衡服务是工作在网络层(修改IP)和传输层(修改端口),比起工作在应用层性能要高出非常多。原理是,它是对IP层的数据包的IP地址和端口信息进行修改,达到负载均衡的目的。常见的负载均衡方式,是LVS(Linux Virtual Server,Linux虚拟服务),通过IPVS(IP Virtual Server,IP虚拟服务)来实现。
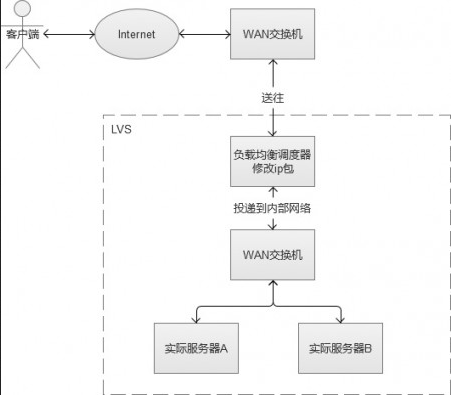
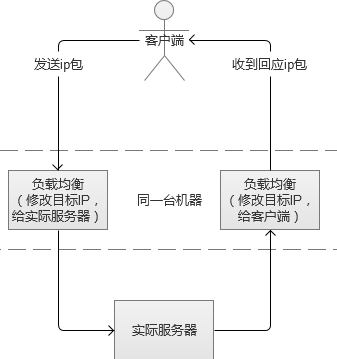
4. DNS负载均衡
DNS(Domain Name System)负责域名解析的服务,域名url实际上是服务器的别名,实际映射是一个IP地址,解析过程,就是DNS完成域名到IP的映射。而一个域名是可以配置成对应多个IP的。因此,DNS也就可以作为负载均衡服务。
