

HTML篇
1. 说说你对HTML5语义化的理解
语义化就是让文本内容来结构化,选择与语义相符合的标签,使代码语义化,这样不仅便于开发者进行阅读,同时也能维护和写出更优雅的代码,还能够让搜索引擎和浏览器等工具更好的解析。
比如段落用p标签,头部用header标签,主要内容用main标签,侧边栏用aside标签等等。
2. meta viewport 是做什么用的
将视口大小设置为可视区域的大小。
什么是视口
视口简单理解就是可视区域大小我们称之为视口
在PC端,视口大小就是浏览器窗口可视区域的大小
在移动端, 视口大小并不等于窗口大小, 移动端视口宽度被人为定义为了980
为什么移动端视口宽度是980而不是其他的值
因为过去网页的版心都是980的,为了能够让网页在移动端完美的展示, 所以将手机视口的大小定义为了980。
移动端自动将视口宽度设置为980带来的问题
虽然移动端自动将视口宽度设置为980之后让我们可以很完美的看到整个网页,但是由于移动端的物理尺寸(设备宽度)是远远小于视口宽度的,所以为了能够在较小的范围内看到视口中所有的内容, 那么就必须将内容缩小。
但是缩小后用户看到的是一个缩小版的整个页面,字体、图标和内容等等都非常小,想要点击或者查看都需要去放大页面进行操作,放大页面之后就会出现横向滚动条,这对用户体验来说是非常不好的。
如何保证在移动端不自动缩放网页的尺寸
通过meta设置视口大小
<meta name="viewport" content="width=device-width, initial-scale=1.0">
viewport 是指 web 页面上用户的可视区域。
meta标签的属性:
width=device-width 设置视口宽度等于设备的宽度
initial-scale=1.0 初始缩放比例, 1不缩放
maximum-scale:允许用户缩放到的最大比例
minimum-scale:允许用户缩放到的最小比例
user-scalable:用户是否可以手动缩放
3. 说一下<label>标签的用法
label标签不会向用户呈现任何特殊效果。不过,它为鼠标用户改进了可用性,方便鼠标点击使用,扩大可点击的范围,增强用户操作体验。
用的时候只需要设置表单元素的id和label标签有一个for属性的值相等即可,for属性和id相同就表示绑定了。当用户选择该标签时,浏览器就会自动将焦点转到和标签相关的表单控件上。
CSS篇
1. 说说盒模型
盒模型是css中重要的基础知识,也是必考的基础知识
CSS盒模型指那些可以设置宽度高度/内边距/边框/外边距的标签
这些属性我们可以用日常生活中的常见事物——盒子作一个比喻来理解,所以HTML标签又叫做盒模型。
- 内容的宽度和高度
就是通过width/height属性设置的宽度和高度 - 元素的宽度和高度
宽度 = 左边框 + 左内边距 + width + 右内边距 + 右边框
高度 同理可证 增加了padding/border之后元素的宽高也会发生变化
如果增加了padding/border之后还想保持元素的宽高, 那么就要减去内容的宽高或者设置box-size的属性值等于border-box - 元素空间的宽度和高度
宽度 = 左外边距 + 左边框 + 左内边距 + width + 右内边距 + 右边框 + 右外边距
高度 同理可证
box-sizing属性
CSS3中新增了一个box-sizing属性, 这个属性可以保证我们给盒子新增padding和border之后, 盒子元素的宽度和高度不变。
box-sizing取值:
content-box 元素的宽高 = 边框 + 内边距 + 内容宽高
border-box 元素的宽高 = width/height的宽高
增加padding和border之后要想保证盒子元素的宽高不变, 设置box-sizing属性值为border-box,系统就会自动减去一部分内容的宽度和高度
2. css水平、垂直居中的写法,请至少写出4种
这题考查的是css的基础知识是否全面,所以平时一定要注意多积累
水平居中
- 行内元素
只需要把行内元素包裹在一个属性display为block的父层元素中,并且把父层元素添加如下属性即可:
.parent {
text-align:center;
}
缺点:为了居中元素,使文本也居中了,因此可能需要重置文本位置。
优点:不需要固定居中元素的宽。
- 块级元素:
margin: 0 auto
缺点:需要固定居中元素的宽。 - 多个块级元素
将元素的display属性设置为inline-block,并且把父元素的text-align属性设置为center即可:
.parent {
text-align:center;
}
- 多个块级元素(使用flexbox布局实现)
使用flexbox布局,只需要把待处理的块级元素的父元素添加属性display:flex及justify-content:center即可:
.parent {
display:flex;
justify-content:center;
}
- 子绝父相 + 负 margin
设置父元素为相对定位,子元素为绝对定位,相对于父元素宽度50%的位置,这个时候还需要往左移动半个子元素宽度的距离,所以这里需要知道子元素的宽度,并设置margin-left属性的值为负的半个子元素宽度。
.parent {
position: relative;
}
// 这里假设子元素宽度为100px
.son {
position: absolute;
left: 50%;
margin-left: -50px;
}
- 子绝父相 + transform
CSS3 中新增的 transform,其 translate 属性是根据元素自身计算的。例如:设置 transform: translateX(-50%);,元素会向左偏移自身宽度的一半。根据这一特性,很容易实现元素的居中:
.parent {
position: relative;
}
.son {
position: absolute;
left: 50%;
transform: translateX(-50%);
}
垂直居中
- 单行的行内元素
以下代码中,将a元素的height和line-height设置的和父元素一样高度即可实现垂直居中
.parent {
height: 200px;
}
a {
height: 200px;
line-height:200px;
}
- 已知高度的块级元素
.item{
position: absolute;
top: 50%;
margin-top: -50px; /* margin-top值为自身高度的一半 */
}
- 未知高度的块级元素
.item{
position: absolute;
top: 50%;
transform: translateY(-50%); /* 使用css3的transform来实现 */
}
- 伸缩布局
.parent {
display:flex;
align-items: center;
}
水平垂直居中
- 已知高度和宽度(不常见)
IE7及之前版本不支持
.item{
position: absolute;
margin:auto;
left:0;
top:0;
right:0;
bottom:0;
}
- 已知高度和宽度
.item{
position: absolute;
top: 50%;
left: 50%;
margin-top: -75px; /* 设置margin-left / margin-top 为自身高度的一半 */
margin-left: -75px;
}
- 子绝父相 + transform
.parent {
position: relative;
}
.son {
position: absolute;
left: 50%;
top: 50%;
transform: translate(-50%, -50%);
}
- 伸缩布局
.parent {
display:flex;
justify-content:center;
align-items: center;
}
3. 画一条0.5px的直线
考查的是css3的transform
height: 1px;
transform: scale(0.5);
4. 画一个三角形
这属于简单的css考查,平时在用组件库的同时,也别忘了原生的css
div{
width: 0;
height: 0;
border: 50px solid transparent;
border-top: 50px solid blue;
}
利用伪元素画三角形
.info-tab {
position: relative;
}
.info-tab::after {
position: absolute;
top: 0;
content: '';
border: 4px solid transparent;
border-top-color: #2c8ac2;
}
5. BFC及其应用
BFC也是必考的基础知识点
BFC (块级格式化上下文),是一个独立的渲染区域,让处于 BFC 内部的元素与外部的元素相互隔离,使内外元素的定位不会相互影响,它属于定位方案的普通流。
触发条件:
- 根元素
- 浮动元素:float 除 none 以外的值(
left、right) - 绝对定位元素:position (absolute、fixed)
- display 为 inline-block、table-cells、flex
- overflow 除了 visible 以外的值 (hidden、auto、scroll)
约束规则:
- 属于同一个
BFC的两个相邻Box垂直排列 - 属于同一个
BFC的两个相邻Box的margin会发生重叠 BFC的区域不会与float的元素区域重叠- 计算
BFC的高度时,浮动子元素也参与计算 - 文字层不会被浮动层覆盖,环绕于周围
作用:
- 阻止元素被浮动元素覆盖 一个正常文档流的block元素可能被一个float元素覆盖,挤占正常文档流,因此可以设置一个元素的float、display、position或者overflow值等方式触发BFC,以阻止被浮动盒子覆盖。
- 可以包含浮动元素(清除浮动) 通过改变包含浮动子元素的父盒子的属性值,触发BFC,以此来包含子元素的浮动盒子。
- 阻止相邻元素的margin合并 属于同一个BFC的两个相邻块级子元素的上下margin会发生重叠,所以当两个相邻块级子元素分属于不同的BFC时可以阻止margin重叠。
6. 清除浮动的几种方式
- 给前面的父盒子添加高度
这种方式不常用 - 利用clear:both;属性
注意:使用clear:both之后margin属性会失效, 所以不常用 - 在两个有浮动子元素的盒子之间添加一个额外的块级元素(外墙法)
在外墙法中可以通过设置额外标签的高度来实现margin效果,但是由于需要添加大量无意义的标签, 所以不常用 - 在前面一个盒子的最后添加一个额外的块级元素(内墙法)
内墙法会自动撑起盒子的高度, 所以可以直接设置margin属性。
和外墙法一样需要添加很多无意义的空标签,有违结构与表现的分离,在后期维护中将是噩梦。 - 利用overflow:hidden
overflow:hidden的作用是清除溢出盒子边框外的内容。
给前面一个盒子添加overflow:hidden属性可以实现清除浮动。
由于overflow:hidden可以撑起盒子的高度, 所以可以直接设置margin属性。IE8以前不支持利用overflow:hidden来清除浮动, 所以需要加上一个*zoom:1;
优点可以不用添加额外的标签又可以撑起父元素的高度, 缺点和定位结合在一起使用时会有冲突。 - 给前面的盒子添加伪元素来清除浮动
本质上和内墙法一样, 都是在前面一个盒子的最后添加一个额外的块级元素 添加伪元素后可以撑起盒子的高度, 所以可以直接设置margin属性
.clearfix:after {
/*生成内容作为最后一个元素*/
content: "";
/*使生成的元素以块级元素显示,占满剩余空间*/
display: block;
/*避免生成内容破坏原有布局的高度*/
height: 0;
/*使生成的内容不可见,并允许可能被生成内容盖住的内容可以进行点击和交互*/
visibility: hidden;
/*重点是这一句*/
clear: both;
}
.clearfix {
/*用于兼容IE, 触发IE hasLayout*/
*zoom:1;
}
- 给前面的盒子添加双伪元素来清除浮动
添加伪元素后可以撑起盒子的高度, 所以可以直接设置margin属性
.clearfix:before,.clearfix:after {
content:"";
display:table;
/*重点是这一句*/
clear:both;
}
.clearfix {
zoom:1;
}
7. 1rem、1em、1vh、1px、1%各自代表的含义
px
px即像素,在前端开发中视口的水平方向和垂直方向是由很多小方格组成的, 一个小方格就是一个像素
例如div尺寸是100 x 100, 那么水平方向就占用100个小方格, 垂直方向就占用100个小方格。
特点:不会随着视口大小的变化而变化, 像素是一个固定的单位(绝对单位)。
%
百分比是前端开发中的一个动态单位, 永远都是以当前元素的父元素作为参考进行计算
例如父元素宽高都是200px, 设置子元素宽高是50%, 那么子元素宽高就是100px
特点:
子元素宽高是参考父元素宽度计算的
子元素padding/margin无论是水平还是垂直方向都是参考父元素宽度计算的
不能用百分比设置元素的border
结论: 百分比是一个动态的单位, 会随着父元素宽高的变化而变化(相对单位)
em
em是前端开发中的一个动态单位, 是一个相对于元素字体大小的单位
例如font-size: 12px; ,那么1em就等于12px
特点:
当前元素设置了字体大小, 那么就相对于当前元素的字体大小
当前元素没有设置字体大小, 那么就相当于第一个设置字体大小的祖先元素的字体大小
如果当前元素和所有祖先元素都没有设置大小, 那么就相当于浏览器默认的字体大小
结论: em是一个动态的单位, 会随着参考元素字体大小的变化而变化(相对单位)
rem
rem就是root em, 和em一样是前端开发中的一个动态单位, rem和em的区别在于, rem是一个相对于根元素字体大小的单位
例如 根元素(html) font-size: 12px; ,那么1em就等于12px
特点:
除了根元素以外, 其它祖先元素的字体大小不会影响rem尺寸
如果根元素设置了字体大小, 那么就相对于根元素的字体大小
如果根元素没有设置字体大小, 那么就相对于浏览器默认的字体大小
结论: rem是一个动态的单位, 会随着根元素字体大小的变化而变化(相对单位)
vw/vh
vw(Viewport Width)和vh(Viewport Height)是前端开发中的一个动态单位, 是一个相对于网页视口的单位
系统会将视口的宽度和高度分为100份, 1vw就占用视口宽度的百分之一, 1vh就占用视口高度的百分之一
vw和vh和百分比不同的是, 百分比永远都是以父元素作为参考,而vw和vh永远都是以视口作为参考
结论: vw/vh是一个动态的单位, 会随着视口大小的变化而变化(相对单位)
vmin和vmax vmin: vw和vh中较小的那个 vmax: vw和vh中较大的那个 使用场景: 保证移动开发中屏幕旋转之后尺寸不变
8. CSS 选择器的优先级是如何计算的
-
间接选中
间接选中就是指继承,如果是间接选中, 那么就是谁离目标标签比较近就听谁的。 -
直接选中
相同选择器
如果都是直接选中, 并且都是同类型的选择器, 那么就是谁写在后面就听谁的
不同选择器
如果都是直接选中, 并且不是相同类型的选择器, 那么就会按照选择器的优先级来层叠 id>类>标签>通配符>继承>浏览器默认 -
优先级权重
当多个选择器混合在一起使用时, 我们可以通过计算权重来判断谁的优先级最高
权重的计算规则:
首先先计算选择器中有多少个id, id多的选择器优先级最高
如果id的个数一样, 那么再看类名的个数, 类名个数多的优先级最高
如果类名的个数一样, 那么再看标签名称的个数, 标签名称个数多的优先级最高
如果id个数一样, 类名个数也一样, 标签名称个数也一样, 那么就不会继续往下计算了, 那么此时谁写在后面听谁的 -
!important
用于提升某个直接选中标签的选择器中的某个属性的优先级的, 可以将被指定的属性的优先级提升为最高
9. 重置(resetting)CSS 和 标准化(normalizing)CSS 的区别是什么?你会选择哪种方式,为什么?
- 重置(Resetting): 重置意味着除去所有的浏览器默认样式。对于页面所有的元素,像
margin、padding、font-size这些样式全部置成一样。你将必须重新定义各种元素的样式。 - 标准化(Normalizing): 标准化没有去掉所有的默认样式,而是保留了有用的一部分,同时还纠正了一些常见错误。
- 当需要实现非常个性化的网页设计时,我会选择重置的方式,因为我要写很多自定义的样式以满足设计需求,这时候就不再需要标准化的默认样式了。
10. 如何解决不同浏览器的样式兼容性问题
- 在确定问题原因和有问题的浏览器后,使用单独的样式表,仅供出现问题的浏览器加载。这种方法需要使用服务器端渲染。
- 使用已经处理好此类问题的库,比如 Bootstrap。
- 使用
autoprefixer自动生成 CSS 属性前缀。 - 使用 Reset CSS 或 Normalize.css。
11. 如何为功能受限的浏览器提供页面? 使用什么样的技术和流程?
- 优雅的降级:为现代浏览器构建应用,同时确保它在旧版浏览器中正常运行。
- 渐进式增强:构建基于用户体验的应用,但在浏览器支持时添加新增功能。
- 利用 caniuse.com 检查特性支持。
- 使用
autoprefixer自动生成 CSS 属性前缀。 - 使用 Modernizr进行特性检测。
12. Less /Sass /Scss 的区别
-
Scss其实是Sass的改进版本
Scss是Sass的缩排语法,对于写惯css前端的web开发者来说很不直观,也不能将css代码加入到Sass里面,因此sass语法进行了改良,Sass 3就变成了Scss(sassy css)。与原来的语法兼容,只是用{}取代了原来的缩进。 -
Less环境较Sass简单
Sass的安装需要安装Ruby环境,Less基于JavaScript,是需要引入Less.js来处理代码输出css到浏览器 -
变量符不一样,Less是@,而Scss是$,而且变量的作用域也不一样。
sass没有局部变量,满足就近原则。less中{}内定义的变量为局部变量。 -
输出设置,Less没有输出设置,Sass提供4中输出选项
输出样式的风格可以有四种选择,默认为nested
nested:嵌套缩进的css代码
expanded:展开的多行css代码
compact:简洁格式的css代码
compressed:压缩后的css代码 -
Sass支持条件语句,可以使用if{}else{},for{}循环等等。而Less不支持。
-
Less与Sass处理机制不一样
前者是通过客户端处理的,后者是通过服务端处理,相比较之下前者解析会比后者慢一点 -
Sass和Less的工具库不同
Sass有工具库Compass, 简单说,Sass和Compass的关系有点像Javascript和jQuery的关系,Compass是Sass的工具库。在 它的基础上,封装了一系列有用的模块和模板,补充强化了Sass的功能。Less有UI组件库Bootstrap, Bootstrap是web前端开发中一个比较有名的前端UI组件库,Bootstrap的样式文件部分源码就是采用Less语法编写,不过Bootstrap4也开始用sass写了。
13. 使用 CSS 预处理器的优缺点分别是什么
优点:
- 提高 CSS 可维护性。
- 易于编写嵌套选择器。
- 引入变量,增添主题功能。可以在不同的项目中共享主题文件。
- 通过混合(Mixins)生成重复的 CSS。
- 将代码分割成多个文件。不进行预处理的 CSS,虽然也可以分割成多个文件,但需要建立多个 HTTP 请求加载这些文件。
缺点:
- 需要预处理工具。
- 重新编译的时间可能会很慢。
14. 对于你使用过的 CSS 预处理,说说喜欢和不喜欢的地方?
喜欢:
- 易于编写嵌套选择器,和更好地复用代码。
- Less 用 JavaScript 实现,与 NodeJS 高度结合。
不喜欢:
- 我通过
node-sass使用 Sass,它用 C ++ 编写的 LibSass 绑定。在 Node 版本切换时,我必须经常重新编译。 - Less 中,变量名称以
@作为前缀,容易与 CSS 关键字混淆,如@media、@import和@font-face。
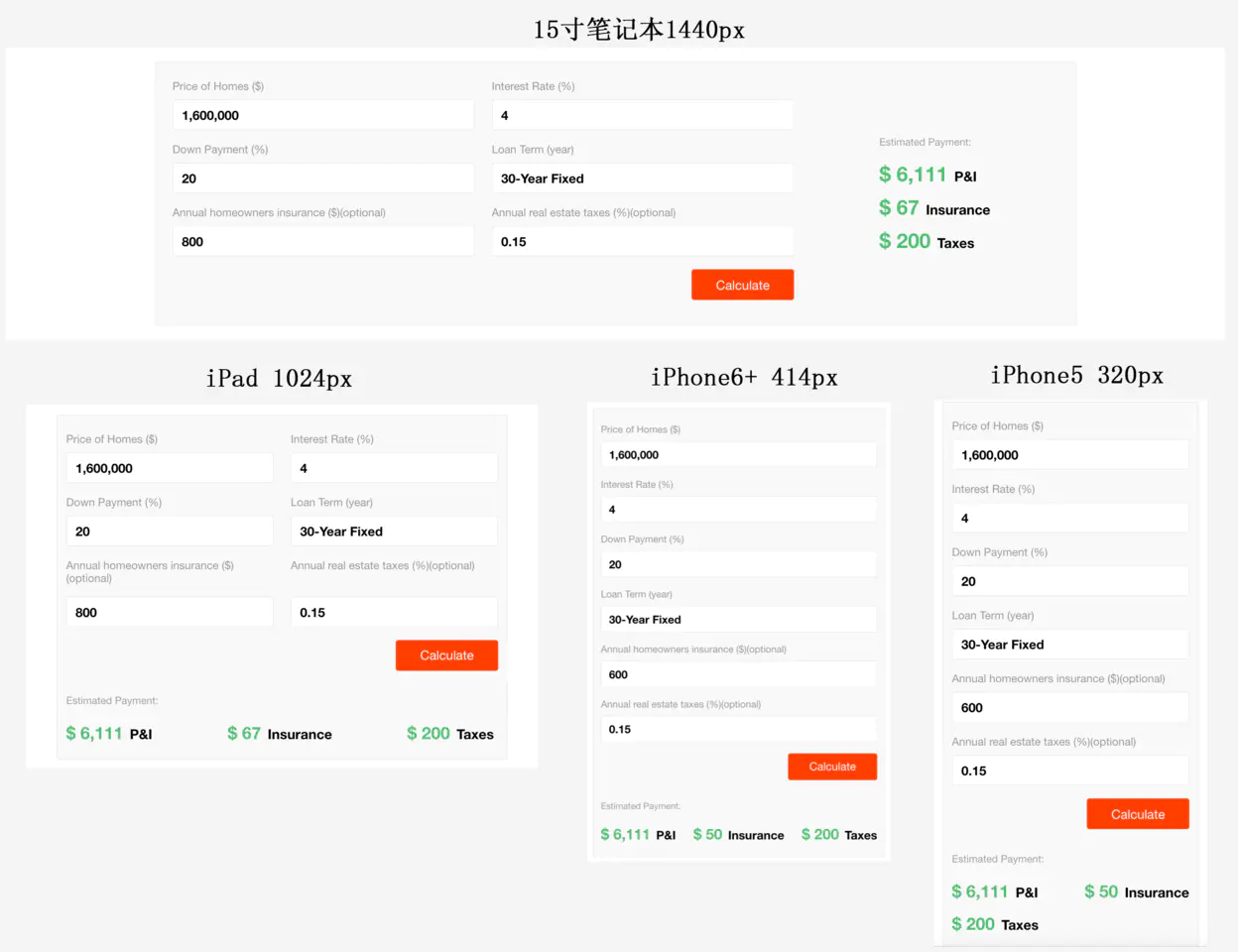
15. 什么是响应式开发?
响应式的页面在不同的屏幕有不同的布局,换句话说,使用相同的html在不同的分辨率有不同的排版。如下图所示:
响应式的优点
-
响应式设计可以向用户提供友好的Web界面,同样的布局,却可以在不同的设备上有不同排版,这就是响应式最大的优点,现在技术发展日新月异,每天都会有新款智能手机推出。如果你拥有响应式Web设计,用户可以与网站一直保持联系,而这也是基本的也是响应式实现的初衷。
-
响应式在开发维护和运营上,相对多个版本成本会降低很多。也无须花大量的时间在网站的维护上
-
方便改动,响应式设计是针对页面的,可以只对必要的页面进行改动,其他页面不受影响。
响应式的缺点
-
为了适配不同的设备,响应式设计需要大量专门为不同设备打造的css及js代码,这导致了文件增大,影响了页面加载速度。
-
在响应式设计中,图片、视频等资源一般是统一加载的,这就导致在低分辨率的机子上,实际加载了大于它的显示要求的图片或视频,导致不必要的流量浪费,影响加载速度;
-
局限性,响应式不适合一些大型的门户网或者电商网站,一般门户网或电商网站一个界面内容较多,对设计样式不好控制,代码过多会影响运行速度。
16. 响应式设计与自适应设计有何不同
响应式设计和自适应设计都以提高不同设备间的用户体验为目标,根据视窗大小、分辨率、使用环境和控制方式等参数进行优化调整。
响应式设计的适应性原则:网站应该凭借一份代码,在各种设备上都有良好的显示和使用效果。响应式网站通过使用媒体查询,自适应栅格和响应式图片,基于多种因素进行变化,创造出优良的用户体验。就像一个球通过膨胀和收缩,来适应不同大小的篮圈。
自适应设计更像是渐进式增强的现代解释。与响应式设计单一地去适配不同,自适应设计通过检测设备和其他特征,从早已定义好的一系列视窗大小和其他特性中,选出最恰当的功能和布局。与使用一个球去穿过各种的篮筐不同,自适应设计允许使用多个球,然后根据不同的篮筐大小,去选择最合适的一个。
17. 文本超出部分显示省略号
单行
overflow: hidden;
text-overflow: ellipsis;
white-space: nowrap;
多行
display: -webkit-box;
-webkit-box-orient: vertical;
-webkit-line-clamp: 3; // 最多显示几行
overflow: hidden;
18. CSS性能优化
加载
- 减小文件体积,—> 代码压缩。
- 减少加载阻塞,—> 减少使用@import (浏览器不能并行下载样式,使用import会导致页面增加额外的往返开销),可通过使用link标签(可以并行下载CSS文件)替代@import,需要注意的是一个页面中的CSS文件不宜过多,否则应简化和合并外部CSS文件以节省请求时间,从而提升页面加载速度。
选择器性能
CSS选择器性能损耗主要源于从DOM Tree —> Render Tree —> Painting 的过程,也即 浏览器匹配选择器和dom文档结构所消耗的时间,首先我们需要明确的是浏览器对于CSS选择器采用从右向左进行规则匹配
那么当嵌套使用选择器时,嵌套深度和最右侧的选择器的执行效率则很关键,下面可以结合实际应用来介绍一些Best Practice:
- 优先使用class选择器,可替代如多层标签选择器规则,增加浏览器匹配效率。
- 谨慎使用id选择器,id选择器在页面中是唯一的,不利于团队协作和代码维护。
- 利用选择器的继承性,避免过分限制选择器导致浏览器工作效率降低。
- 避免CSS正则表达式规则。
渲染性能
-
减少使用高开销的CSS属性(即绘制前需要浏览器进行大量计算的属性)如box-shadow, border-radius, transparency, transforms and css filters等。
-
减少重排(Reflow),重排意味着元素位置发生改变,对于交互性较强的web引用来说,重排是在所难免的,但仍然可以从以下几方面进行优化:
- 不要一条一条地修改 DOM 的样式,预先定义好 class,然后修改 DOM 的 className。
- DOM 离线后修改,如先把 DOM元素 给 display:none (有一次 Reflow),然后修改100次,最后再把它显示出来。
- 尽可能不要修改影响范围较大的 DOM元素。
- 为动画元素使用绝对定位 absolute /fixed。
- 不使用 table 布局,可能很小的一个小改动会造成整个 table 的重排。
-
减少重绘(Repaint),重绘意味着元素位置不变,浏览器仅仅根据新的样式重绘该元素(如border-color,background-color,visibility等)。
-
优化动画,启用GPU硬件加速。
-
GPU加速可以不仅应用于3D,而且也可以应用于2D,通常可以应用于Canvas2D,布局合成(Layout Compositing), CSS3转换(transitions),CSS3 3D变换(transforms),WebGL和视频(video)。
以上为常见CSS性能优化的一些方面,实际开发中应综合业务需要进行组合使用,毕竟功能与性能之间总是需要一些权衡的,所以一切事情都是相对的,应以辩证的角度对待。
JavaScript篇
1. 用js递归的方式写1到100求和?
function sum(x) {
return x < 2? 1 : x + sum(x - 1);
}
如何用JS递归实现求m~n之间连续个整数之和?
function sum(m, n) {
if(n == m) {
return m;
}else {
return n + sum(m, n - 1);
}
}
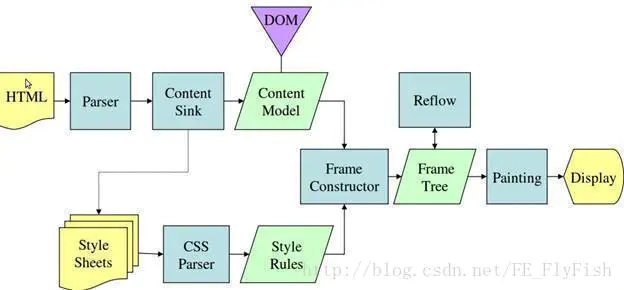
2. 页面渲染html的过程?
不需要死记硬背,理解整个过程即可
浏览器渲染页面的一般过程:
1.浏览器解析html源码,然后创建一个 DOM树。并行请求 css/image/js文件。在DOM树中,每一个HTML标签都有一个对应的节点,并且每一个文本也都会有一个对应的文本节点。DOM树的根节点就是 documentElement,对应的是html标签。
2.浏览器解析CSS代码,计算出最终的样式数据。构建CSSOM树。对CSS代码中非法的语法它会直接忽略掉。解析CSS的时候会按照如下顺序来定义优先级:浏览器默认设置 < 用户设置 < 外链样式 < 内联样式 < html中的style。
3.DOM Tree + CSSOM --> 渲染树(rendering tree)。渲染树和DOM树有点像,但是是有区别的。
DOM树完全和html标签一一对应,但是渲染树会忽略掉不需要渲染的元素,比如head、display:none的元素等。而且一大段文本中的每一个行在渲染树中都是独立的一个节点。渲染树中的每一个节点都存储有对应的css属性。
4.一旦渲染树创建好了,浏览器就可以根据渲染树直接把页面绘制到屏幕上。
以上四个步骤并不是一次性顺序完成的。如果DOM或者CSSOM被修改,以上过程会被重复执行。实际上,CSS和JavaScript往往会多次修改DOM或者CSSOM。
3. 说一下闭包?
闭包的实质是因为函数嵌套而形成的作用域链
闭包的定义即:函数 A 内部有一个函数 B,函数 B 可以访问到函数 A 中的变量,那么函数 B 就是闭包
用途:使用闭包主要是为了设计私有的方法和变量
优点:可以避免变量被全局变量污染
缺点:函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包
解决方法:在退出函数之前,将不使用的局部变量全部删除
闭包的经典题,输出什么?
for(var i = 0; i < 3; i++) {
setTimeout(function() {
console.log(i);
}, 1000);
}
// 3个3,首先,for 循环是同步代码,先执行三遍 for,i 变成了 3;
// 然后,再执行异步代码 setTimeout,这时候输出的 i,只能是 3 个 3 了
有什么办法输出 0 1 2:
第一种:
把var改成let,每个 let 和代码块结合起来形成块级作用域,
当 setTimeout() 打印时,会寻找最近的块级作用域中的 i,所以依次打印出 0 1 2
第二种:使用立即执行函数,创建一个独立的作用域
for(let i = 0; i < 3; i++) {
(function(i){
setTimeout(function() {
console.log(i);
}, 1000);
})(i)
}
闭包的具体使用场景:
- setTimeout
IE9 及其更早版本不支持的setTimeout的函数不支持传递参数,通过闭包可以实现传参效果。
function f1(a) {
function f2() {
console.log(a);
}
return f2;
}
var fun = f1(1);
setTimeout(fun,1000);//一秒之后打印出1
- 函数防抖
function debounce(fn, delay){
let timerId = null
return function(){
const context = this
if(timerId){window.clearTimeout(timerId)}
timerId = setTimeout(()=>{
fn.apply(context, arguments)
timerId = null
},delay)
}
}
const debounced = debounce(()=>console.log('hi'))
debounced()
debounced()
4. 请简述JavaScript的this的指向
第一准则是:this永远指向函数运行时所在的对象,而不是函数被创建时所在的对象。
- 普通的函数调用,函数被谁调用,this就是谁。
- 构造函数的话,如果不用new操作符而直接调用,那即this指向window。用new操作符生成对象实例后,this就指向了新生成的对象。
- 匿名函数或不处于任何对象中的函数指向window 。
- 如果是call,apply, bind等,指定的this是谁,就是谁。
- 如果该函数是箭头函数,将忽略上面的所有规则,this被设置为它被创建时的上下文。
5. 使用let、var和const创建变量有什么区别
用var声明的变量的作用域是它当前的执行上下文,它可以是嵌套的函数,也可以是声明在任何函数外的变量。let和const是块级作用域,意味着它们只能在最近的一组花括号(function、if-else 代码块或 for 循环中)中访问。
function foo() {
// 所有变量在函数中都可访问
var bar = 'bar';
let baz = 'baz';
const qux = 'qux';
console.log(bar); // bar
console.log(baz); // baz
console.log(qux); // qux
}
console.log(bar); // ReferenceError: bar is not defined
console.log(baz); // ReferenceError: baz is not defined
console.log(qux); // ReferenceError: qux is not defined
if (true) {
var bar = 'bar';
let baz = 'baz';
const qux = 'qux';
}
// 用 var 声明的变量在函数作用域上都可访问
console.log(bar); // bar
// let 和 const 定义的变量在它们被定义的语句块之外不可访问
console.log(baz); // ReferenceError: baz is not defined
console.log(qux); // ReferenceError: qux is not defined
var会使变量提升,这意味着变量可以在声明之前使用。let和const不会使变量提升,提前使用会报错。
console.log(foo); // undefined
var foo = 'foo';
console.log(baz); // ReferenceError: can't access lexical declaration 'baz' before initialization
let baz = 'baz';
console.log(bar); // ReferenceError: can't access lexical declaration 'bar' before initialization
const bar = 'bar';
用var重复声明不会报错,但let和const会。
var foo = 'foo';
var foo = 'bar';
console.log(foo); // "bar"
let baz = 'baz';
let baz = 'qux'; // Uncaught SyntaxError: Identifier 'baz' has already been declared
let和const的区别在于:let允许多次赋值,而const只允许一次。
// 这样不会报错。
let foo = 'foo';
foo = 'bar';
// 这样会报错。
const baz = 'baz';
baz = 'qux';
6. 说说bind,call,apply的区别
bind方法和其他两个方法的区别就是不会立即执行修改后的函数或方法
call方法和apply方法的区别就是call方法可以直接传参, 而apply需要通过数组传参
7. 箭头函数和普通函数有什么区别
- 函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象,用call apply bind也不能改变this指向
- 不可以当作构造函数,也就是说,不可以使用new命令,否则会抛出一个错误。
- 不可以使用arguments对象,该对象在函数体内不存在。如果要用,可以用 rest 参数代替。
- 不可以使用yield命令,因此箭头函数不能用作 Generator 函数。
- 箭头函数没有原型对象prototype
8. new 一个对象的过程中发生了什么
// 1. 创建空对象;
var obj = {};
// 2. 设置新对象的 constructor 属性为构造函数的名称,设置新对象的__proto__属性指向构造函数的 prototype 对象;
obj.__proto__ = ClassA.prototype;
// 3. 使用新对象调用函数,函数中的 this 被指向新实例对象:
ClassA.call(obj); //{}.构造函数();
// 4. 如果无返回值或者返回一个非对象值,则将新对象返回;如果返回值是一个新对象的话那么直接直接返回该对象。
9. 如何判断一个对象是否为数组
第一种方法:使用 instanceof 操作符。
第二种方法:使用 ECMAScript 5 新增的 Array.isArray()方法。
第三种方法:使用使用 Object.prototype 上的原生 toString()方法判断。
10. 对象浅拷贝和深拷贝有什么区别
深拷贝
修改新变量的值不会影响原有变量的值
默认情况下基本数据类型都是深拷贝
let num1 = 123;
let num2 = num1;
num2 = 666; // 修改新变量(num2)的值, 没有影响到原有变量(num1)的值
console.log(num1); // 123
console.log(num2); // 666
浅拷贝
修改新变量的值会影响原有变量的值
默认情况下引用类型都是浅拷贝
class Person{
name = "lnj";
age = 34;
}
// 这里会将Person()这个类的地址给p1
let p1 = new Person();
// 这里会将p1的值拷贝给p2, 也就p2也拿到了Person()这个类的地址, 所以p1和p2同时指向Person()
let p2 = p1;
p2.name = "zs"; // 修改新变量(p2)的值, 影响到了原有变量(p1)的值
console.log(p1.name); // zs
console.log(p2.name); // zs
11. 怎么实现对象深拷贝
通过自定义函数实现深拷贝
class Person{
name = "zs";
cat = {
age : 3
};
score = [1, 3, 5];
}
let p1 = new Person();
let p2 = new Object();
// 通过自定义函数实现深拷贝
function deCopy(target, source) {
// 1.通过遍历拿到source中所有的属性
for (let key in source){
// 2.取出当前遍历到的属性对应的取值
let sourceValue = source[key];
// 3.判断当前的取值是否是引用数据类型
if (sourceValue instanceof Object){ // 如果是引用数据类型, 那么要新建一个存储空间保存
// 4.通过sourceValue.constructor拿到这个对象的构造函数的类型, 然后新建这个对象或数组
let subTarget = new sourceValue.constructor;
target[key] = subTarget;
// 5.再次调用拷贝, 将遍历到的属性的取值拷贝给新建的对象或者数组
deCopy(subTarget, sourceValue);
}else { // 如果不是引用数据类型, 之间将属性拷贝即可
target[key] = sourceValue;
}
}
}
deCopy(p2, p1);
p2.cat.age = 666; // 修改新变量的值不会影响到原有变量, 这里是深拷贝
console.log(p1.cat.age); // 3
console.log(p2.cat.age); // 666
12. 数组去重
方法 1
扩展运算符和 Set 结构相结合,就可以去除数组的重复成员
// 去除数组的重复成员
[...new Set([1, 2, 2, 3, 4, 5, 5])];
// [1, 2, 3, 4, 5]
方法 2
Array.from()能把set结构转换为数组
function dedupe(array) {
return Array.from(new Set(array));
}
dedupe([1, 1, 2, 3]); // [1, 2, 3]
方法 3(ES5)
function unique(arry) {
const temp = [];
arry.forEach(e => {
if (temp.indexOf(e) == -1) {
temp.push(e);
}
});
return temp;
}
13. 反转数组
要求
输入: I am a student 输出: student a am I
输入是数组 输出也是数组 不允许用 split splice reverse
解法一
function reverseArry(arry) {
const str = arry.join(' ')
const result = []
let word = ''
for (let i = 0, len = str.length; i < len; i++) {
if (str[i] != ' ') {
word += str[i]
} else {
result.unshift(word)
word = ''
}
}
result.unshift(word)
return result
}
console.log(reverseArry(['I', 'am', 'a', 'student']))
// ["student", "a", "am", "I"]
解法二
function reverseArry(arry) {
const result = []
const distance = arry.length - 1
for (let i = distance; i >= 0; i--) {
result[distance - i] = arry[i]
}
return result
}
14. 说说原型和原型链
每个"构造函数"中都有一个默认的属性, 叫做 prototype, prototype属性保存着一个对象, 这个对象我们称之为"原型对象", prototype 指向它的原型对象
每个"原型对象"中都有一个默认的属性, 叫做constructor, constructor 指向当前原型对象对应的那个"构造函数"
通过构造函数创建出来的对象我们称之为"实例对象", 每个"实例对象"中都有一个默认的属性, 叫做__proto__, __proto__ 指向创建它的那个构造函数的"原型对象"

基本关系
1. 所有的构造函数都有一个prototype属性, 所有prototype属性都指向自己的原型对象
2. 所有的原型对象都有一个constructor属性, 所有constructor属性都指向自己的构造函数
3. 所有函数都是Function构造函数的实例对象
4. 所有函数都是对象, 包括Function构造函数
5. 所有对象都有__proto__属性
6. 普通对象的__proto__属性指向创建它的那个构造函数对应的"原型对象"
特殊关系
7. 所有对象的__proto__属性最终都会指向"Object原型对象"
8. "Object原型对象"的__proto__属性指向NULL
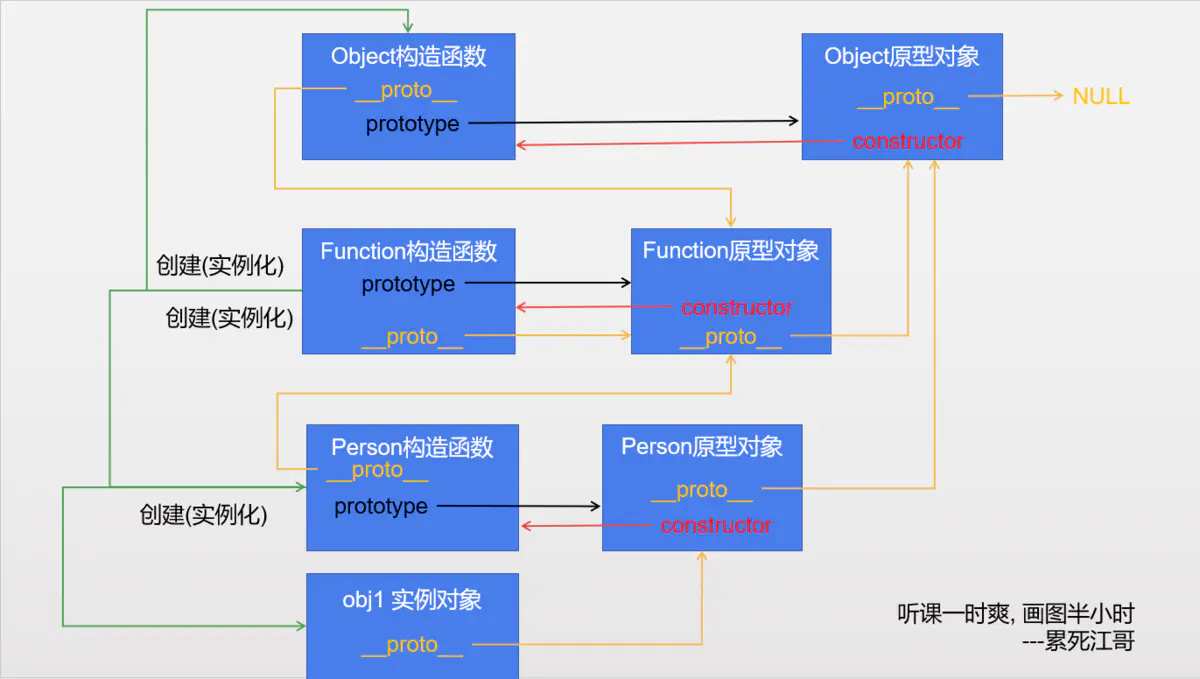
对象中__proto__组成的链条我们称之为原型链
对象在查找属性和方法的时候, 会先在当前对象查找, 如果有就用自己的
如果当前对象中找不到想要的, 会依次去上一级原型对象中查找
如果找到Object原型对象都没有找到, 就会报错

15. ES5和ES6继承
ES5继承
- 在子类中通过call / apply方法借助父类的构造函数
- 将子类的原型函数设置为父类的实例对象
function Person(myName, myAge) {
this.name = myName;
this.age = myAge;
}
Person.prototype.say = function () {
console.log(this.name, this.age);
}
function Student(myName, myAge, myScore) {
// 1.在子类中通过call/apply方法借助父类的构造函数
Person.call(this, myName, myAge);
this.score = myScore;
this.study = function () {
console.log("day day up");
}
}
// 2.将子类的原型对象设置为父类的实例对象
Student.prototype = new Person();
Student.prototype.constructor = Student;
let stu = new Student("zs", 18, 98);
stu.say(); // zs 18
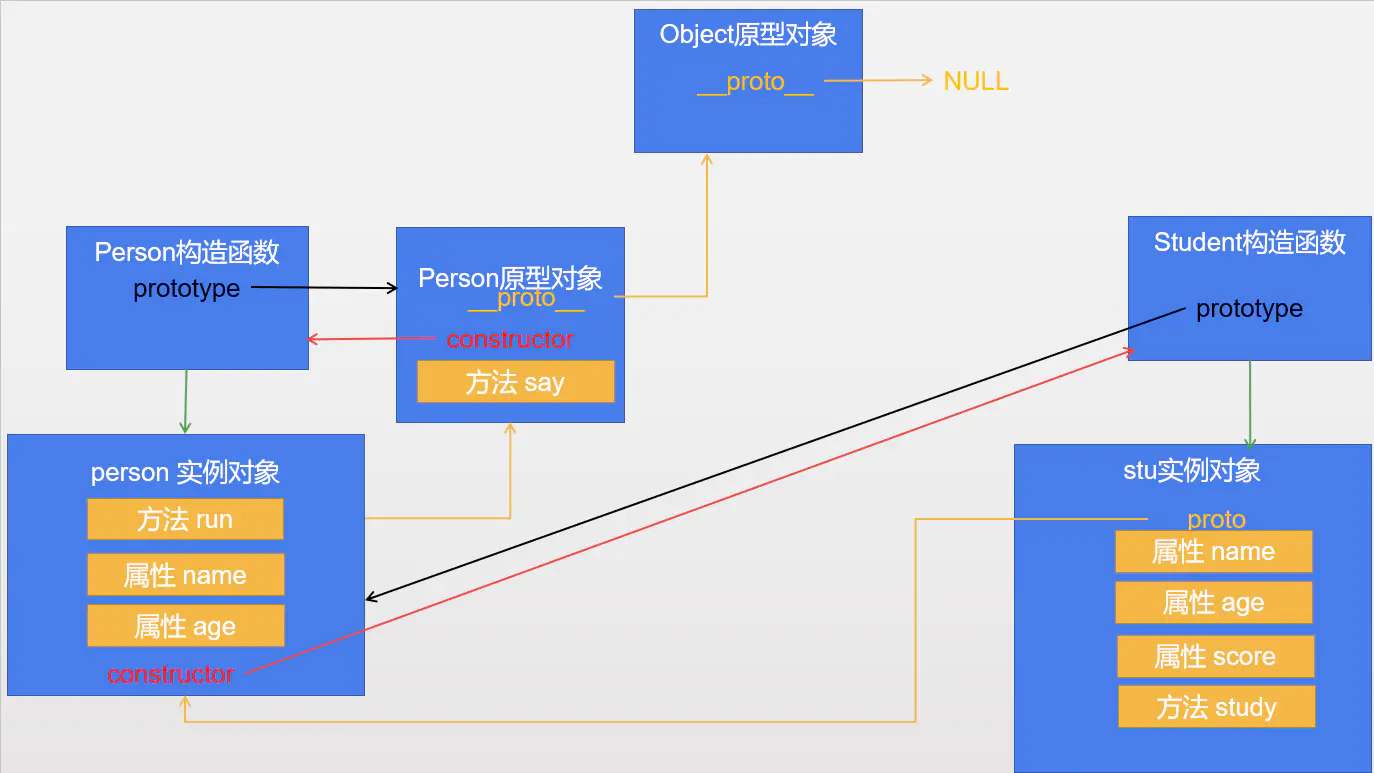
ES6继承
- 通过子类extends父类, 来告诉浏览器子类要继承父类
- 通过super()方法修改 this
class Person{
constructor(myName, myAge){
// this = stu;
this.name = myName; // stu.name = myName;
this.age = myAge; // stu.age = myAge;
}
say(){
console.log(this.name, this.age);
}
}
// 以下代码的含义: 告诉浏览器将来Student这个类需要继承Person这个类
class Student extends Person{
constructor(myName, myAge, myScore){
super(myName, myAge); // 这一行代码相当于在子类中通过call/apply方法借助父类的构造函数
this.score = myScore;
}
study(){
console.log("day day up");
}
}
let stu = new Student("zs", 18, 98);
stu.say(); // zs 18
16. 什么是事件代理/事件委托?
事件代理/事件委托是利用事件冒泡的特性,将本应该绑定在多个元素上的事件绑定在他们的祖先元素上,尤其在动态添加子元素的时候,可以非常方便的提高程序性能,减小内存空间。
17. 什么是事件冒泡?什么是事件捕获?
事件冒泡
事件会从最内层的元素开始发生,一直向上传播,直到document对象。
事件捕获
与事件冒泡相反,事件会从最外层开始发生,直到最具体的元素。
18. 如何设置事件到底是捕获还是冒泡?
通过 addEventListener 方法, 这个方法接收三个参数
第一个参数: 事件的名称
第二个参数: 回调函数
第三个参数: false 冒泡 / true 捕获
let oFDiv = document.querySelector(".father");
let oSDiv = document.querySelector(".son");
// 捕获
oFDiv.addEventListener("click", function () {
console.log("father"); // 先执行father
}, true);
oSDiv.addEventListener("click", function () {
console.log("son"); // 后执行son
}, true);
// 冒泡
oFDiv.addEventListener("click", function () {
console.log("father"); // 后执行father
}, false);
oSDiv.addEventListener("click", function () {
console.log("son"); // 先执行son
}, false);
onXxx的属性, 不接收任何参数, 所以默认就是冒泡
attachEvent 方法, 只能接收两个参数, 所以默认就是冒泡
如果想看到捕获只能通过 addEventListener 方法
let oFDiv = document.querySelector(".father");
let oSDiv = document.querySelector(".son");
// 冒泡
oFDiv.onclick = function () {
console.log("father"); // 后执行father
};
oSDiv.onclick = function () {
console.log("son"); // 先执行son
}
不是所有的事件都能冒泡,以下事件不冒泡:blur、focus、load、unload
19. 如何阻止事件冒泡
stopPropagation 方法只支持高级浏览器
cancelBubble 方法只支持低级浏览器
兼容性写法
// 1.拿到需要操作的元素
let oFDiv = document.getElementById("father");
let oSDiv = document.getElementById("son");
// 2.注册事件监听
oFDiv.onclick = function () {
console.log("father");
};
oSDiv.onclick = function (event) {
event = event || window.event;
// 兼容性写法
if (event.cancelBubble){
event.cancelBubble = true;
} else {
event.stopPropagation();
}
console.log("son");
};
20. 如何阻止默认事件?
return false; (推荐)
let oA = document.querySelector("a");
oA.onclick = function () {
alert("666");
// 阻止默认行为
// 企业开发推荐的写法
return false;
}
preventDefault 方法 只支持高级s版本的浏览器
returnValue (IE9以下)
let oA = document.querySelector("a");
oA.onclick = function (event) {
// 兼容性写法
// 在低版本的浏览器中通过window.event才能拿到这个对象
event = event || window.event;
alert("666");
// 阻止默认行为
// 兼容性写法
if(event.returnValue){
// IE9以下的浏览器使用的
event.returnValue = false;
}else{
event.preventDefault();
}
}
21. 事件循环机制eventloop 和 JS垃圾回收机制
事件循环机制:
1.在代码的执行过程中会先执行同步代码,然后宏任务(script,setTimeout...)进入宏任务队列,
微任务(Promise.then(),Promise)进入微任务队列
2.当宏任务执行完之后出队,检查微任务列表,继续执行微任务直到执行完毕
3.执行浏览器的UI渲染过程
4.检查是否有Web Worker任务,有则执行
5.继续下一轮的宏任务和微任务
垃圾回收机制:
方法一:标记清除(比较常见)
1.当变量进入执行环境时,就标记这个变量为“进入环境”。
//从逻辑上讲,永远不能释放进入环境的变量所占用的内存,因为只要执行流进入相应的环境,就可能会用到他们。
2.当变量离开环境时,则将其标记为“离开环境”。
3.垃圾收集器在运行的时候会给存储在内存中的所有变量都加上标记,它会去掉环境中的变量以及被环境中的变量引用的标记。
4.在此之后再被加上标记的变量将被视为准备删除的变量,原因是环境中的变量已经无法访问到这些变量了。
5.最后垃圾收集器完成内存清除工作,销毁那些带标记的值,并回收他们所占用的内存空间。
方法二:引用计数(不常见)
1.跟踪记录每个值被引用的次数。当声明了一个变量并将一个引用类型赋值给该变量时,则这个值的引用次数就是1。
2.相反,如果包含对这个值引用的变量又取得了另外一个值,则这个值的引用次数就减1。
3.当这个引用次数变成0时,则说明没有办法再访问这个值了,因而就可以将其所占的内存空间给收回来。
4.这样,垃圾收集器下次再运行时,它就会释放那些引用次数为0的值所占的内存。
22. JS怎么取消事件?
1.如果是用onclick方式绑定的事件可以用如这种方法取消:btn.onclick=null;//删除事件处理程序
2.如果使用addEventListener()方法添加事件,可以通过removeEventListener()移出事件,需要注意两点:
2.1 removeEventListener()的第三个参数必须和addEventListener()方法的第三个参数一致。
2.2 通过addEventListener()方法添加的匿名函数将无法移除。
btn.aaddEventListener('click',function(){alert(1);},false);
btn.removeEventListener('click',function(){alert(1);},false);//没有用!
aaddEventListener和removeEventListener看似传入了相同的参数, 但实际上removeEventListener的第二个参数与aaddEventListener的第二个参数是完全不同的函数,想要移出必须这样:
var fn=function(){
alert(1);
};
btn.aaddEventListener('click',fn,false);
btn.removeEventListener('click',fn,false);//有效
22. 图片的预加载和懒加载
预加载:提前加载图片,当用户需要查看时可直接从本地缓存中渲染
懒加载:用户滑到某个位置的时候才开始加载图片,主要目的是作为服务器前端的优化,减少请求数或延迟请求数
本质:两者的行为是相反的,一个是提前加载,一个是迟缓甚至不加载。
预加载则会增加服务器前端压力,懒加载对服务器有一定的缓解压力作用。
23. 函数的节流和防抖
函数节流
函数节流是优化高频率执行js代码的一种手段
可以减少高频调用函数的执行次数
作用:减少代码执行次数, 提升网页性能
应用场景:oninput / onmousemove / onscroll / onresize 等事件
let timerId = null;
let flag = true;
window.onresize = function () {
if (!flag){ // if(false) if(true) if(false)
return;
}
flag = false;
timerId && clearInterval(timerId);
timerId = setTimeout(function () {
flag = true;
resetSize();
console.log("尺寸变化");
}, 500);
}
函数防抖
函数防抖是优化高频率执行js代码的一种手段
可以让被调用的函数在一次连续的高频操作中只被调用一次
作用:减少代码执行次数, 提升网页性能
应用场景:oninput / onmousemove / onscroll / onresize 等事件
let oInput = document.querySelector("input");
let timerId = null;
oInput.oninput = function () {
timerId && clearInterval(timerId);
timerId = setTimeout(function () {
console.log("发生网络请求");
}, 1000);
}
函数节流和函数防抖区别
函数节流是减少连续的高频操作函数执行次数 (例如连续调用10次, 可能只执行3-4次)
函数防抖是让连续的高频操作时函数只执行一次(例如连续调用10次, 但是只会执行1次)
25. 全局函数eval()有什么作用?
eval()只有一个参数,如果传入的参数不是字符串,它直接返回这个参数。
如果参数是字符串,它会把字符串当成javascript代码进行编译。如果编译失败则抛出一个语法错误(syntaxError)异常。
如果编译成功,则开始执行这段代码,并返回字符串中的最后一个表达式或语句的值,如果最后一个表达式或语句没有值,则最终返回undefined。
如果字符串抛出一个异常,这个异常将把该调用传递给eval()。
26. 请简述JavaScript三大对象
JavaScript中提供三种自带的对象, 分别是"本地对象" / "内置对象" / "宿主对象"
宿主就是指JavaScript运行环境, js可以在浏览器中运行, 也可以在服务器上运行(node.js)
1.本地对象
与宿主无关, 无论是在浏览器还是在服务器都可以使用的对象
就是ECMAScript标准中定义的类(构造函数)
在使用过程中需要我们手动new创建一个新的对象才能使用
例如: Boolean 、Number 、Array 、Function 、Object 、Date 、 RegExp等
2. 内置对象
与宿主无关, 无论是在浏览器还是在服务器都可以使用的对象
ECMAScript已经帮我们创建好的对象
在使用过程中无需我们手动new创建就可以使用
例如: Global 、Math 、JSON
3. 宿主对象
要么只属于浏览器的, 要么只属于服务器的
对于嵌入到网页中的JS来说, 其宿主对象就是浏览器, 所以宿主对象就是浏览器提供的对象
包含: Window和Document等
所有的 DOM 和 BOM 对象都属于宿主对象
ES6篇
1. 请简述一下你对Symbol的理解
Symbol是ES6中新增的一种数据类型, 被划分到了基本数据类型中
基本数据类型: 字符串、数值、布尔、undefined、null、Symbol
引用数据类型: Object
Symbol的作用
用来表示一个独一无二的值
let xxx = Symbol();
为什么需要Symbol?
在企业开发中如果需要对一些第三方的插件、框架进行自定义的时候
可能会因为添加了同名的属性或者方法, 将框架中原有的属性或者方法覆盖掉
为了避免这种情况的发生, 框架的作者或者我们就可以使用Symbol作为属性或者方法的名称
如何区分Symbol?
在通过Symbol生成独一无二的值时可以设置一个标记
这个标记仅仅用于区分, 没有其它任何含义
let name = Symbol("name");
如果想使用变量作为对象属性的名称, 那么必须加上[]
let name = Symbol("name");
let say = Symbol("say");
let obj = {
// 注意点: 如果想使用变量作为对象属性的名称, 那么必须加上[]
[name]: "lnj",
[say]: function () {
console.log("say");
}
}
// obj.name = "it666";
obj[Symbol("name")] = "it666";
console.log(obj);
2. 什么是Iterator?
Iterator又叫做迭代器, 是一种接口
这里的接口和现实中接口一样, 是一种标准一种规范
例如: 电脑的USB接口有电脑USB接口的标准和规范, 正式因为有了标准和规范
所以A厂商生成的USB线可以插到B厂商电脑的USB接口上
它规定了不同数据类型统一访问的机制, 这里的访问机制主要指数据的遍历
在ES6中Iterator接口主要供for...of消费
默认情况下以下数据类型都实现的Iterator接口
Array/Map/Set/String/TypedArray/函数的 arguments 对象/NodeList 对象
1.只要一个数据已经实现了Iterator接口, 那么这个数据就有一个叫做[Symbol.iterator]的属性
2.[Symbol.iterator]的属性会返回一个函数
3.[Symbol.iterator]返回的函数执行之后会返回一个对象
4.[Symbol.iterator]函数返回的对象中又一个名称叫做next的方法
5.next方法每次执行都会返回一个对象{value: 1, done: false}
6.这个对象中存储了当前取出的数据和是否取完了的标记
class MyArray{
constructor(){
for(let i = 0; i < arguments.length; i++){
// this[0] = 1;
// this[1] = 3;
// this[2] = 5;
this[i] = arguments[i];
}
this.length = arguments.length;
}
[Symbol.iterator](){
let index = 0;
let that = this;
return {
next(){
if(index < that.length){
return {value: that[index++], done: false}
}else{
return {value: that[index], done: true}
}
}
}
}
}
3. 什么是Generator函数?
Generator 函数是 ES6 提供的一种异步编程解决方案
Generator 函数内部可以封装多个状态, 因此又可以理解为是一个状态机
如何定义Generator函数
只需要在普通函数的function后面加上*即可
Generator函数和普通函数区别
调用Generator函数后, 无论函数有没有返回值, 都会返回一个迭代器对象,
调用Generator函数后, 函数中封装的代码不会立即被执行
真正让Generator具有价值的是yield关键字
在Generator函数内部使用yield关键字定义状态
并且yield关键字可以让 Generator内部的逻辑能够切割成多个部分。
通过调用迭代器对象的next方法执行一个部分代码, 执行哪个部分就会返回哪个部分定义的状态
在调用next方法的时候可以传递一个参数, 这个参数会传递给上一个yield
function* gen() {
console.log("123");
let res = yield "aaa";
console.log(res);
console.log("567");
yield 1 + 1;
console.log("789");
yield true;
}
4. async函数和await操作符
async函数是ES8中新增的一个函数, 用于定义一个异步函数
async函数函数中的代码会自动从上至下的执行代码
await操作符只能在异步函数 async function 中使用
await表达式会暂停当前 async function 的执行,等待 Promise 处理完成。
若 Promise 正常处理(fulfilled),其回调的resolve函数参数作为 await 表达式的值,然后继续执行 async function。
function request() {
return new Promise(function (resolve, reject) {
setTimeout(function () {
resolve("拿到的数据");
}, 1000);
});
}
async function gen() {
let res1 = await request();
console.log(res1, 1);
let res2 = await request();
console.log(res2, 2);
let res3 = await request();
console.log(res3, 3);
}
gen();
5. 说一下自己常用的es6的功能?
此题是一道开放题,可以自由回答。但要注意像let这种简单的用法就别说了,说一些经常用到并有一定高度的新功能
像module、class、promise等,尽量讲的详细一点。
6. 说一下JS异步编程
JS是单线程的
所以JS中的代码都是串行的, 前面没有执行完毕后面不能执行
JavaScript的单线程,与它的用途有关。
作为浏览器脚本语言,JavaScript的主要用途是与用户互动,以及操作DOM。
这决定了它只能是单线程,否则会带来很复杂的同步问题。
例如: 如果JS是多线程的
现在有一个线程要修改元素中的内容, 一个线程要删除该元素, 这时浏览器应该以哪个线程为准?
同步代码和异步代码
除了"事件绑定的函数"和"回调函数"以外的都是同步代码
程序运行会从上至下依次执行所有的同步代码
在执行的过程中如果遇到异步代码会将异步代码放到事件循环中
当所有同步代码都执行完毕后, JS会不断检测 事件循环中的异步代码是否满足条件
一旦满足条件就执行满足条件的异步代码
什么是promise?
promise是ES6中新增的异步编程解决方案, 在代码中的表现是一个对象
开发中为了保存异步代码的执行顺序, 那么就会出现回调函数层层嵌套
如果回调函数嵌套的层数太多, 就会导致代码的阅读性, 可维护性大大降低
promise对象可以将异步操作以同步流程来表示, 避免了回调函数层层嵌套(回调地狱)
