

前言
Github地址:github.com/Caozefu/sma…
最近逛GitHub时发现一位大神基于tensorflow.js开发了一款用于人脸识别和检测的JavaScript API,于是尝试实现了一个自动加载特效的项目。
介绍
Tensorflow
Tensorflow最初是由一群Google的大佬开发出来用于机器学习和深度神经网络研究的。引用社区的一句话,它一个采用数据流图(data flow graphs),用于数值计算的开源软件库。节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor)。
具体的专业知识也不太懂,大佬可以移步官方文档
Tensorflow.js。

face-api
相比较tensorflow,face-api是一位大神基于tensorflow开发的方便像我这种凡人使用的API。

这个API就简单很多了,作者封装了用于人脸检测、人脸点位检测、人脸识别、人脸表情检测、性别检测等。拥有现成的训练完成的模型供我们直接使用,因此我们可以借助这个API来实现一些有趣的功能。
具体文档链接:
face-api
提示: 仓库大小约273M,GitHub下载慢的小伙伴可以从gitee导入再clone
1. 起步
1.1 引入face-api
针对浏览器环境或Nodejs运行环境,引入方式会有些不同。
// 浏览器环境
<script src="dist/face-api.min.js"></script>
// npm
npm i face-api.js
// Node环境
// 非必须引入,需要python环境,引入后会提高运行速度
import '@tensorflow/tfjs-node';
// 由于node环境没有canvas和image等dom元素,需要额外引入
import * as canvas from 'canvas';
import * as faceapi from 'face-api.js';
const { Canvas, Image, ImageData } = canvas
faceapi.env.monkeyPatch({ Canvas, Image, ImageData })
本文使用浏览器环境做简单
Demo
引入后会有一个全局对象faceapi,其中的faceapi.nets保存了全局神经网络实例对象。
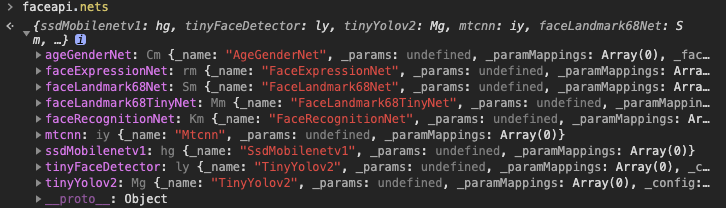
ageGenderNet: new AgeGenderNet() // 年龄识别
faceExpressionNet: new FaceExpressionNet(), // 表情识别
faceLandmark68Net: new FaceLandmark68Net(), // 面部点位识别(68点)
faceLandmark68TinyNet: new FaceLandmark68TinyNet(), // 面部快速点位识别
faceRecognitionNet: new FaceRecognitionNet(), // 面部识别
mtcnn: new Mtcnn(), // MTCNN
ssdMobilenetv1: new SsdMobilenetv1(), // mobolenets人脸检测
tinyFaceDetector: new TinyFaceDetector(), // 人脸快速检测
tinyYolov2: new TinyYolov2(), // Yolov2人脸检测
1.2 加载模型
在识别前需要先加载对应的训练模型,否则会报错。在源码仓库的weights目录下,有作者提供的模型,当然也可以加载自定义的其他模型。
调用对应实例的load方法,由于加载方式如下
async function loadModel() {
// await faceapi.nets.ssdMobilenetv1.load('./face-api.js/weights');
await faceapi.nets.tinyFaceDetector.load('./weights/tiny');
}
由于需要严格按照先加载模型的顺序,因此使用async await保证流程顺序。这里ssdMobilenetv1和tinyFaceDetector的区别在于,前者识别准确度和精度都要高一些,不过对应速度会慢很多,适合静态图片或准确度要求较高场景的检测;后者检测速度快,因此适合做实时监测。
1.3 人脸识别
加载完模型后,需要确定一个输入源,可以是image、canvas、video。
<img id="image" src="img.png" />
<video id="video" src="video.mp4" />
<canvas id="canvas" />
const input = document.getElementById('image')
// const input = document.getElementById('video')
// const input = document.getElementById('canvas')
// 或者直接传入id
// const input = 'image'
确定输入源后,就可以调用faceapi.detectAllFaces或faceapi.detectSingleFace获取所有面部数据或单个面部数据。
async function getFace() {
const detections = await faceapi.detectAllFaces(input);
// const detections = await faceapi.detectAllFaces(input, new faceapi.SsdMobilenetv1Options());
// const detections = await faceapi.detectAllFaces(input, new faceapi.TinyFaceDetectorOptions());
}
其中detectAllFaces的第二个参数不指定时默认为SsdMobilenetv1Options,如果想要使用TinyFaceDetectorOptions,在加载模型时,应该使用
faceapi.nets.tinyFaceDetector.load();
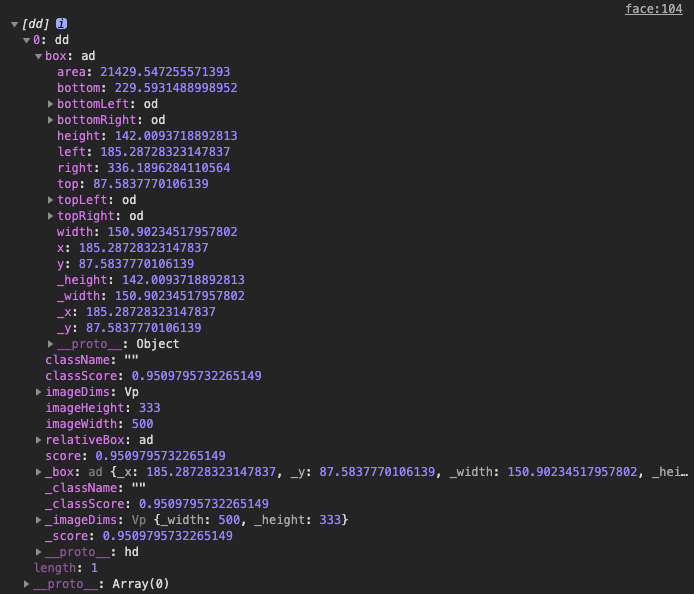
最终会返回一个检测到人脸的矩形区域数据,数据结构如下,其中box包含了矩形区域的各点位属性等。
1.4 点位识别
上面说到的detectAllFaces方法,会返回一个矩形区域数据,当我们想要更详细的五官和脸部轮廓数据时,只需要在此函数之后链式调用withFaceLandmarks。
async function getFace() {
const detections = await faceapi.detectAllFaces(input).withFaceLandmarks();
}
不过在此之前,需要在模型加载阶段,增加landmark模型引入
async function loadModel() {
await faceapi.nets.tinyFaceDetector.load('./weights/tiny');
await faceapi.loadFaceLandmarkModel('./weights/face_landmark')
// await faceapi.loadFaceLandmarkTinyModel();
}
这里同样分为loadFaceLandmarkModel和loadFaceLandmarkTinyModel,对应在withFaceLandmarks传入boolean值区分。
const useTinyModel = true;
detectAllFaces(input).withFaceLandmarks(useTinyModel);
最终返回的结果中,会附带一个landmarks,其中的positions中包含了68个点位。至此,我们就可以用这68个点位做点有意思的事。

2. 页面搭建
只需要搭建一个简陋的页面,简陋到只有video和canvas标签。

// 获取摄像头数据做一下兼容
function getUserMedia(constrains, success, error) {
if (navigator.mediaDevices && navigator.mediaDevices.getUserMedia) {
//最新标准API
navigator.mediaDevices.getUserMedia(constrains).then(success).catch(error);
} else if (navigator.webkitGetUserMedia) {
//webkit内核浏览器
navigator.webkitGetUserMedia(constrains).then(success).catch(error);
} else if (navigator.mozGetUserMedia) {
//Firefox浏览器
navagator.mozGetUserMedia(constrains).then(success).catch(error);
} else if (navigator.getUserMedia) {
//旧版API
navigator.getUserMedia(constrains).then(success).catch(error);
}
}
//成功的回调函数
function success(stream) {
//将视频流设置为video元素的源
video.srcObject = stream;
//播放视频
video.play();
}
//异常的回调函数
function error(error) {
console.log("访问用户媒体设备失败:", error.name, error.message);
}
getUserMedia({
video: {
width: 500,
height: 300,
facingMode: 'user'
}
}, success, error);
获取到摄像头数据并传入video后,将input设置为此video标签。
3. 实时检测点位
3.1 实时获取数据
由于faceapi本身没有实时获取的方法,因此我们只需要在获取到摄像头数据后实时获取数据即可。
video.onloadedmetadata = function () {
getFace();
}
video加载数据完成并开始播放后,调用getFace,同时改造一下此方法。
async function getFace() {
if (video.paused || video.ended) return;
const input = video;
const detections = await faceapi.detectAllFaces(input, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks(true);
if (detections && detections.length) {
// 匹配尺寸
faceapi.matchDimensions(canvas, input)
// 绘制外边框
faceapi.draw.drawDetections(canvas, faceapi.resizeResults(detections, input))
// 绘制点位
faceapi.draw.drawFaceLandmarks(canvas, faceapi.resizeResults(detections, input))
}
setTimeout(() => getFace())
}
由此形成循环实时获取数据并绘制。
4. 绘制图片
4.1 确定具体点位
由于我们检测到的点位还不知道具体代表什么位置,因此我们增加一个drawPoint用于绘制对应数字到对应点位,这时需要什么位置就使用对应数字的点位。
async function getFace() {
if (video.paused || video.ended) return;
const input = video;
const detections = await faceapi.detectAllFaces(input, new faceapi.TinyFaceDetectorOptions()).withFaceLandmarks(true);
if (detections && detections.length) {
// 匹配尺寸
faceapi.matchDimensions(canvas, input)
detections[0].landmarks.positions.forEach((item, index) => {
drawPoint(item, index);
})
}
setTimeout(() => getFace())
}
function drawPoint(point, index) {
// 绘制文字
cxt.fillStyle = "#FF0000";
cxt.font = "10px bold 黑体";
// 设置水平对齐方式
cxt.textAlign = "center";
// 设置垂直对齐方式
cxt.textBaseline = "middle";
cxt.fillText(index, point.x, point.y);
}
绘制的结果如下,我们可以看到17,26号点位代表眼睛的左右两侧,我们想要添加对应的效果,只需要计算宽度并加载图片到对应的位置。

4.2 添加图片
首先计算两点位的距离,勾股定理算一下。
const point1 = detections[0].landmarks.positions[17];
const point2 = detections[0].landmarks.positions[26];
const width = Math.sqrt((point2.x - point1.x) ** 2 + (point2.y - point1.y) ** 2) + 30;
canvas添加图片并绘制
function drawImg(point, index, width) {
// 坐标微调并绘制图片
cxt.drawImage(img, point.x - 5, point.y - 5, width, width);
}
最后整合一下代码,就完成了简单的人物佩戴眼睛的特效。
总结
虽然只是个简单的Demo,但是可以看到现在纯前端也能够实现复杂的机器学习,后续会对这个项目进行改进,探索增加更多有趣的功能。同时文章中如果有什么不专业写的不对的,欢迎大家及时指正。
