

谢谢墨灵的分享
简单选择器
首先,我们先来实现一个最简单的类选择器,可以判断'.a'是否选中
<div class='a'></div>
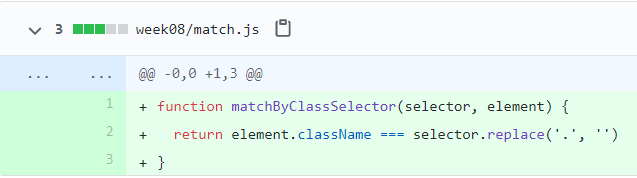
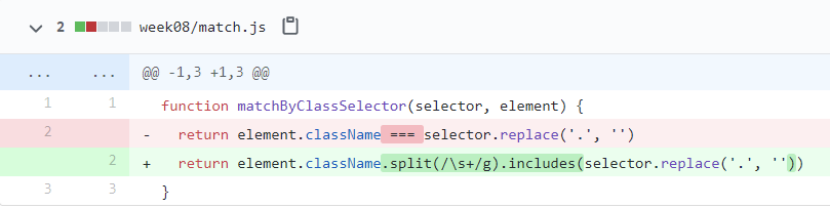
其实我们可以做得更好一点,只要稍微改造一下,就可以判断'.a'是否选中
<div class='a b'></div>
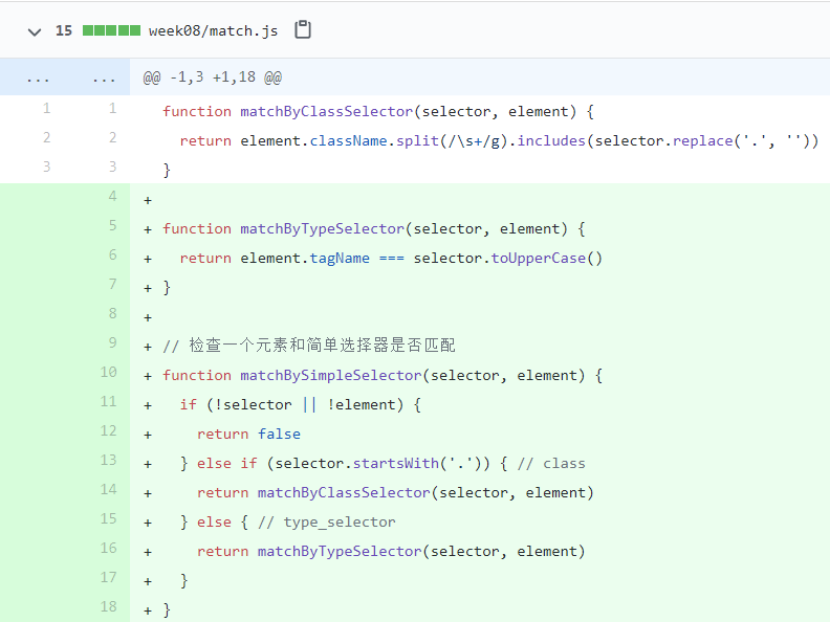
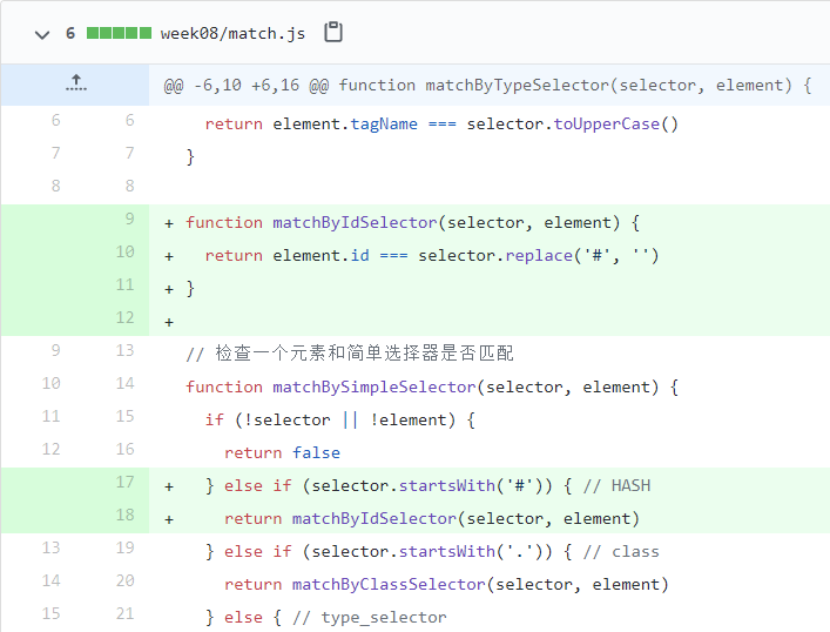

再深入一点的话,就可以支持属性値全等匹配

最后,可以用一组属性值匹配函数来实现各种规则的比较

复合选择器
现在就实现一个支持单个简单选择器的匹配器了,那'a#id.link[src^="https"]'这种复合的简单选择器应该怎么实现呢?
其实可以把它拆解成["a", "#id", ".link", "[src^="https"]"],然后一个一个规则和当前元素比对,全通过之后才会认为这个选择器是和当前元素匹配的
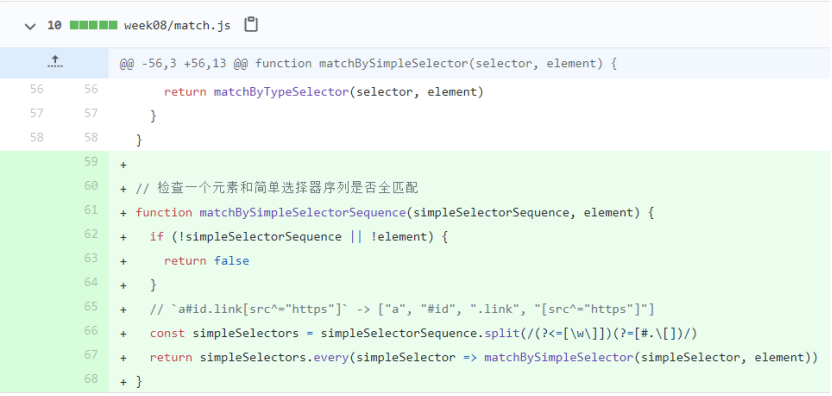
有了matchBySimpleSelectorSequence之后,实现:not伪类选择器的匹配也变成简单了,只要简单的取反就可以了
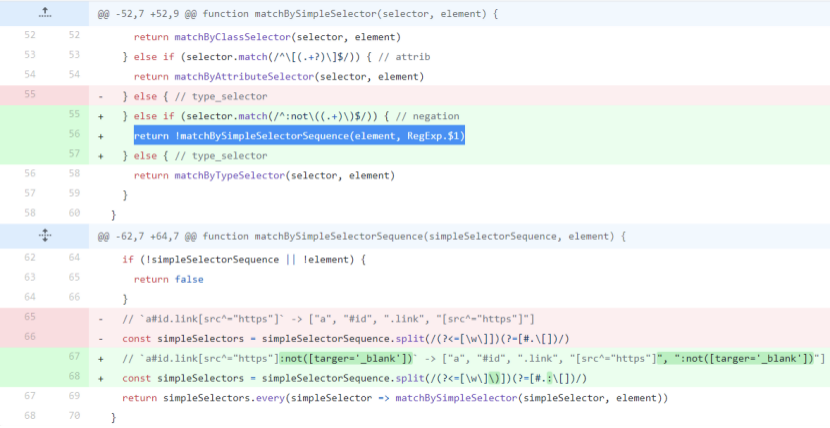
这个简单选择器到了现在就比较完善了,除了伪类伪元素的全实现,跟着是复杂选择器,各种关系
复杂选择器(关系选择器)
1. +>组合器的算法
所谓复杂选择器,就是带有组合器的选择器
组合器有四种,空格、>、~、+
先来看一个略为简单的复杂选择器,#a>#b+#c+#d,这个选择器其实可以分为四个部分,#a>,#b+,#c+,#d
首先是匹配 #d,然后看到 #c+ 的组合器是 + , 所以找到 #d 的前兄弟与 #c 匹配,然后再看到 #b+ 的组合器也是 +,所以找到 #c 的前兄弟与 #b 匹配,最后看到 #a> 的组合器是 >,所以找到 #b 的父亲与 #a 匹配,这就是复杂选择器的匹配过程
所以先把一个复杂选择器拆分成几个带组合器的部分,再从右到左逐步匹配(这个值得思考),直到所有部分都能匹配,那这元素才算和这套规则匹配
这就是支持+>组合器的算法

1. +>组合器的算法
+和>的算法都是相似的,只是+是向前一步找匹配的元素,>是向上一步找匹配的元素,它们的差别仅此而已
那~和空格的算法也是相似的,只是~是向前面一群兄弟元素找一个可匹配的元素,空格就是向上面一堆父元素找一个可以匹配的元素
在已有的函数再做一点点小扩展就可以实现了
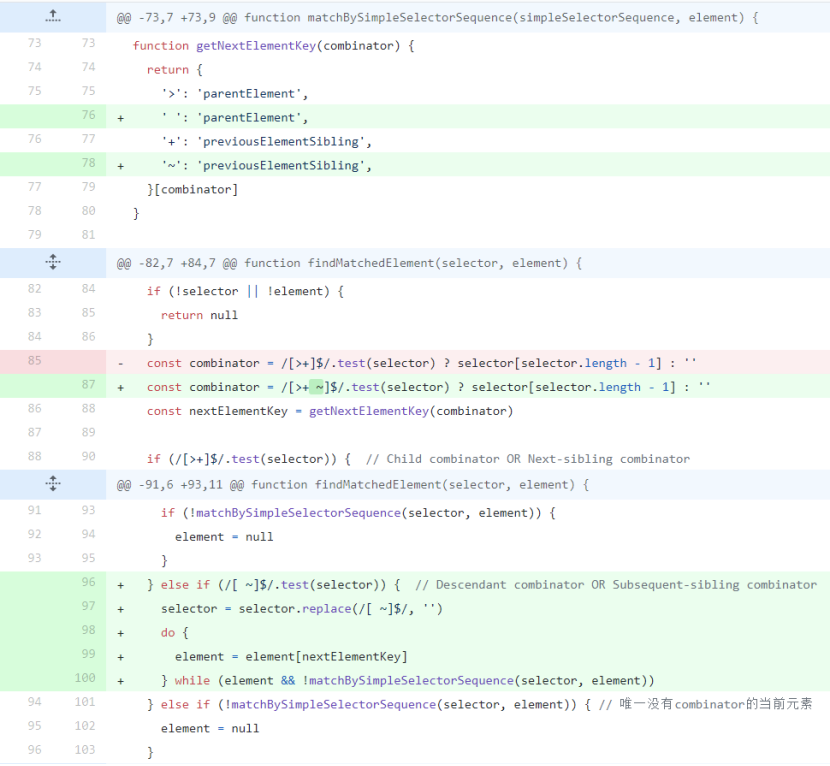
最后
这样一来,这个match函数就可以支持tag,id,class,attr,:not的任意组合的 简单选择器,也支持空格、~、>、+四种组合器的任意组合的 复杂选择器 了。
题外话:
这次把整个迭代过程也讲了一遍,其实任何功能都是从简单到复杂,其实也没那么复杂 拆分小问题 解决小问题 再串联小问题构成解决大问题方案 最后优化逻辑 结果输出任何需求都可以拆分到自己认为能解决的粒度 整合自己的知识体系 解决需求选择器概念不清晰 先去看标准理清楚概念,正则不熟悉看推荐博客学习正则 ,收集掌握好相关技能 实操 断点调试 整理逻辑 解决需求
