


人生起起伏伏,有风光无限日,也有落魄失魂时,人在低谷时,唯有“熬过去,才会赢”
前言
上一篇文章我们讲了从dsl写法,到如何利用spring data ElasticSearch来代码实现java操作ElasticSearch,这一期我们继续讲解,官方文档中的深入搜索之全文搜索,望大家有所收获。
1. 基于词项与基于全文:
I. 基于词项的查询
我们都知道,ElasticSearch在存储字符串时,会将字符串根据自带分词器进行分词,而所谓基于词项的查询即是不分词查询,必须在整个词语完全匹配的情况下才显示结果,也就是我们常说并且常用到的精确查询。像term和fuzzy,它们的底层查询不需要分析操作,它们只对单个词组进行操作,例如term查询,它只会在倒排索引中精确查询准确词项。
II. 基于全文的查询
所谓全文查询,通俗来说就是全字段或者多字段查询,例如query_string和match_query,拿query_string来说,它就是全字段匹配,当你对一个字符串进行查询,它会将字符串传递到合适的字段进行查询,最终结果是会将所有字段,匹配到该字符串的数据全部显示。
2. 匹配搜索
匹配查询-match 是ElasticSearch的核心查询,在我们使用ElasticSearch的时候,无论何时,match都应该是我们优先选择的查询方式,它是一个高级的全文查询,同时具有分词查询和精确查询的能力。
DSL:
GET /demo/demodo/_search
{
"query": {
"match": {
"name": "addb8e53"
}
}
}
SQL(不完全相等,SQL没有分词查询):
select * from demo where name = 'addb8e53'
Spring Data ElasticSearch:
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "addb8e53")
out(queryBuilder);
刚才我们说了,match查询是一个高级的全文查询,同时具有分词查询和精确查询的能力,上面这段查询方式,用的就是分词查询,name字段是字符串类型,value我写的是一段UUID,分词器根据 - 进行了分词,addb8e53是这个UUID中的其中一段,所以我可以使用这种方式查询到多个包含这个分段的结果,如果我需要精确查询,则只需要在name后面加上一个.keyword即可,由"name": "addb8e53"变成"name.keyword": "addb8e53",spring data查询同理。
3. 多词查询
刚刚这种查询只是对这个字段进行了一次匹配,现在我们给name提供两个字符串来同时匹配。 下面这种查询,就是查出符合addb8e53 or 4d3029a6分词的结果。例如现在有 "name": "addb8e53-b504-499f-990b-5d73a35171e5" 和 "name": "4d3029a6-46f5-4b3b-afa2-3372ec2effcb" ,这时候这两个就会同时被查询出来。
DSL:
GET /demo/demodo/_search
{
"query": {
"match": {
"name": "addb8e53 4d3029a6"
}
}
}
SQL(不完全相等,SQL没有分词查询):
select * from demo where name like '%addb8e53%' or name like '%4d3029a6%'
Spring Data ElasticSearch:
QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "addb8e53 4d3029a6");
out(queryBuilder);
除此之外,elasticsearch还提供了一种提高精度的查询,可以让查询结果,同时含有addb8e53和4d3029a6两个分词。elasticsearch给match提供了operator操作符,默认是or,这也就是我们为什么刚刚可以查出两个分词的结果,现在我们需要将or改成and,查出的结果就是必须同时存在两个分词的结果。
DSL:
GET /demo/demodo/_search
{
"query": {
"match": {
"name": "addb8e53 4d3029a6",
"operator": "and"
}
}
}
4. 组合查询
之前我们有说过一个bool过滤器,bool过滤器提供了多个过滤条件,组合过滤器其实和bool过滤器差不多,用法和写法基本也是一样的,但查询更精确一些,组合查询 查询也可以接受 must 、must_not 和 should 参数下的多个查询语句,但是组合查询会给每个查询的文档计算相关度评分,将所有符合的 must 和 should 查询结果的评分求和,最后除以 must 和 should语句的总数。组合查询还提供了精度控制——minimum_should_match,它可以填写百分比或者数字来控制我们需要查询的should语句的精度,比如,我们现在should语句中有三条过滤条件,但是我们现在填写了minimum_should_match: 2,那么这个时候,查询结果中,符合should过滤两个条件的,要比符合should过滤三个条件的评分要高。
5. 如何使用布尔匹配
我们上面有说过分词查询,但是其实分词查询和如下的bool匹配是相等的:
DSL:
GET /demo/demodo/_search
{
"query": {
"bool": {
"should": [
{
"term": {
"name": "addb8e53"
}
},
{
"term": {
"name": "4d3029a6"
}
}
]
}
}
}
注:match查询中也有minimum_should_match参数,如果有3个查询分词,minimum_should_match参数填写的是而,查询结果必须满足2个分词才会被显示
6. 查询语句提升权重
如下的DSL,就是提升权重的例子,我们控制should语句的权重,提供了boost参数,boost参数默认是1,数值越高权重越高,对应的评分越高
DSL:
{
"query": {
"bool": {
"should": [
{
"match": {
"name": {
"query": "addb8e53"
}
}
},
{
"match": {
"name": {
"query": "4d3029a6",
"boost": 4
}
}
}
]
}
}
}
添加权重前后比较如下图: 添加权重前:

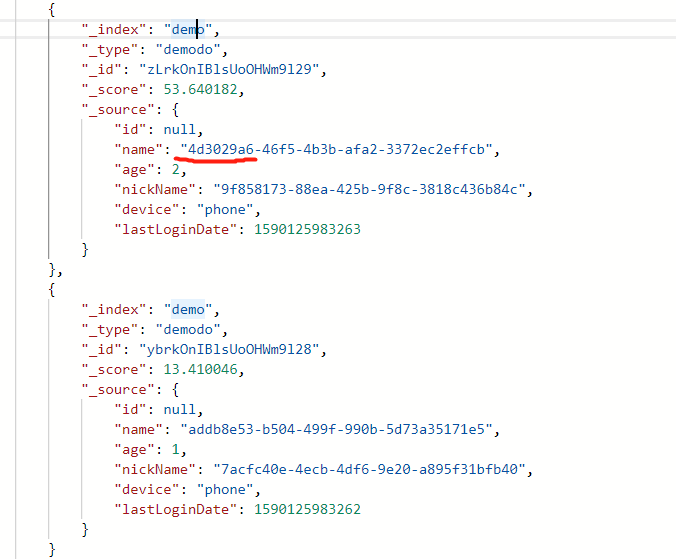
总结
很抱歉文章很久没有更新,这段时间疫情原因,公司一直都比较忙,最近压力也比较大,生活中也发生了一些事情,心情一直比较差,导致很久没有更新,在此和大家说声抱歉。还是一如既往的做最简单的文章,用最通俗的话语写清楚操作,希望大家喜欢。

