

消息发布和订阅-Pub/Sub
- 发布/订阅与key所在空间没有关系,它不会受任何级别的干扰,包括不同数据库编码。 发布在db 10,订阅可以在db 1。 如果你需要区分某些频道,可以通过在频道名称前面加上所在环境的名称(例如:测试环境,演示环境,线上环境等)
- Redis 的Pub/Sub实现支持模式匹配。客户端可以订阅全风格的模式以便接收所有来自能匹配到给定模式的频道的消息。
- 客户端可能多次接收一个消息,如果它订阅的多个模式匹配了同一个发布的消息,或者它订阅的模式和频道同时匹配到一个消息。
pipeline-管道
- 一次请求/响应服务器能实现处理新的请求即使旧的请求还未被响应。这样就可以将多个命令发送到服务器,而不用等待回复,最后在一个步骤中读取该答复。
- 使用管道发送命令时,服务器将被迫回复一个队列答复,占用很多内存。所以,如果你需要发送大量的命令,最好是把他们按照合理数量分批次的处理,例如10K的命令,读回复,然后再发送另一个10k的命令,等等。这样速度几乎是相同的,但是在回复这10k命令队列需要非常大量的内存用来组织返回数据内容。
事务
- 事务是一个单独的隔离操作:事务中的所有命令都会序列化、按顺序地执行。事务在执行的过程中,不会被其他客户端发送来的命令请求所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行
1. 事务开始
- MULTI 命令用于开启一个事务,它总是返回 OK 。 MULTI 执行之后, 客户端可以继续向服务器发送任意多条命令, 这些命令不会立即被执行, 而是被放到一个队列中, 当 EXEC命令被调用时, 所有队列中的命令才会被执行。
2. 执行事务
- EXEC 命令的回复是一个数组, 数组中的每个元素都是执行事务中的命令所产生的回复。 其中, 回复元素的先后顺序和命令发送的先后顺序一致。
- 当客户端处于事务状态时, 所有传入的命令都会返回一个内容为 QUEUED 的状态回复(status reply), 这些被入队的命令将在 EXEC 命令被调用时执行
- 如果客户端在使用 MULTI 开启了一个事务之后,却因为断线而没有成功执行 EXEC ,那么事务中的所有命令都不会被执行。
- 另一方面,如果客户端成功在开启事务之后执行 EXEC ,那么事务中的所有命令都会被执行。
- 当 EXEC 被调用时, 不管事务是否成功执行, 对所有键的监视都会被取消。
3. 取消事务:
- 当执行 DISCARD 命令时, 事务会被放弃, 事务队列会被清空, 并且客户端会从事务状态中退出:
4. 监控事务:
- WATCH 命令可以为 Redis 事务提供 check-and-set (CAS)行为。
- 被 WATCH 的键会被监视,并会发觉这些键是否被改动过了。 如果有至少一个被监视的键在 EXEC 执行之前被修改了, 那么整个事务都会被取消, EXEC 返回nil-reply来表示事务已经失败。
- 如果在 WATCH 执行之后, EXEC 执行之前, 有其他客户端修改了 mykey 的值, 那么当前客户端的事务就会失败。 程序需要做的, 就是不断重试这个操作, 直到没有发生碰撞为止。这种形式的锁被称作乐观锁, 它是一种非常强大的锁机制。 并且因为大多数情况下, 不同的客户端会访问不同的键, 碰撞的情况一般都很少, 所以通常并不需要进行重试。
为什么redis不支持回滚
- 优点1:Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中
- 优点2:因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
modules-布隆过滤器(RedisBloom)
- RedisBloom模块提供了四种数据类型
- 可伸缩的布隆过滤器
- 可伸缩的布谷鸟过滤器
- 一个最小计数草图
- 一个前K个数据
- 布隆过滤器和布谷鸟过滤器用于确定(以给定的确定性)集合中是否存在某项
1、redis安装布隆过滤器的module
https://github.com/RedisBloom/RedisBloom#redisbloom---bloom-filter-module-for-redis
$ redis-server --loadmodule /path/to/redisbloom.so
2、如何用小的空间存储大量的数据
- String类型中的bitmap
- 布隆过滤器本质是一个位数组,位数组就是数组的每个元素都只占用 1 bit 。每个元素只能是 0 或者 1。这样申请一个 10000 个元素的位数组只占用 10000 / 8 = 1250 B 的空间
- 布隆过滤器说某个元素在,可能会被误判,也可以能不在
- 布隆过滤器说某个元素不在,那么一定不在。
- error_rate:允许布隆过滤器的错误率,这个值越低过滤器的位数组的大小越大,占用空间也就越大
- initial_size:布隆过滤器可以储存的元素个数,当实际存储的元素个数超过这个值之后,过滤器的准确率会下降
- 时间复杂度: O(1)
- 最大存储的空间512M 2的32次方-1
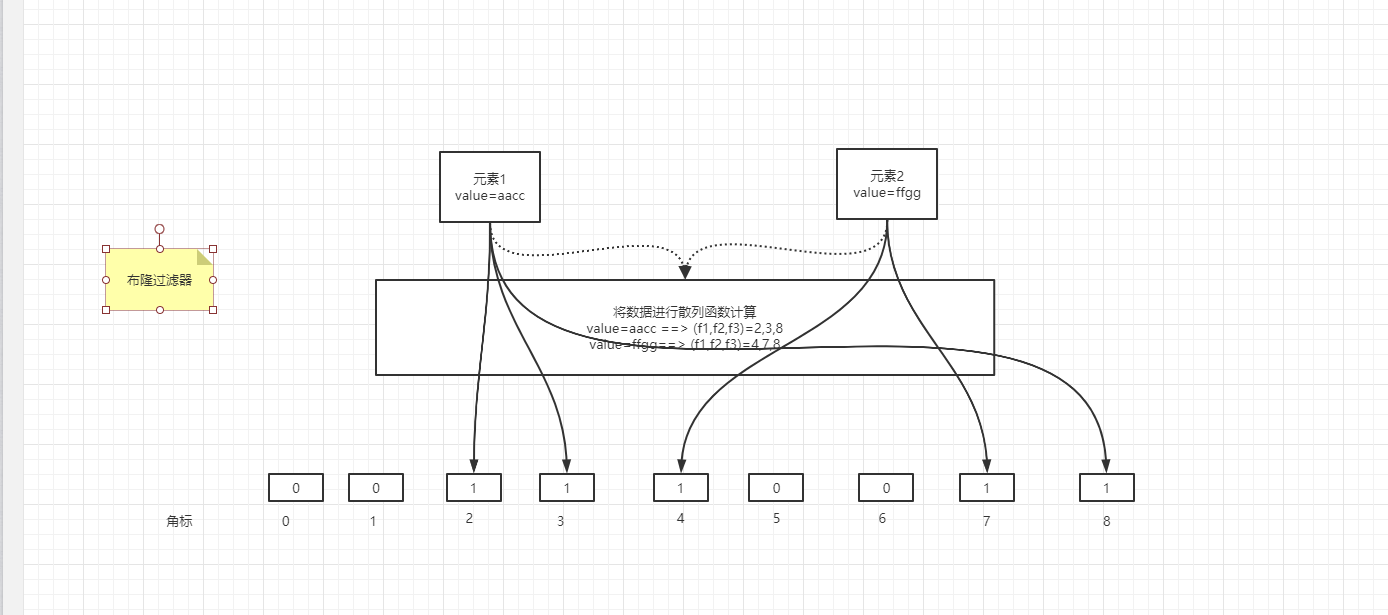
3、redis中使用方式
扩展 布谷鸟过滤
- 为了解决布隆过滤器不能删除元素的问题,布谷鸟过滤器横空出世
- 相比布谷鸟过滤器而言布隆过滤器有以下不足:查询性能弱、空间利用效率低、不支持反向操作(删除)以及不支持计数
- 查询性能弱是因为布隆过滤器需要使用多个 hash 函数探测位图中多个不同的位点,这些位点在内存上跨度很大,会导致 CPU 缓存行命中率低
- 空间效率低是因为在相同的误判率下,布谷鸟过滤器的空间利用率要明显高于布隆,空间上大概能节省 40% 多。不过布隆过滤器并没有要求位图的长度必须是 2 的指数,而布谷鸟过滤器必须有这个要求。从这一点出发,似乎布隆过滤器的空间伸缩性更强一些。
- 不支持反向删除操作这个问题着实是击中了布隆过滤器的软肋。在一个动态的系统里面元素总是不断的来也是不断的走。布隆过滤器就好比是印迹,来过来就会有痕迹,就算走了也无法清理干净。比如你的系统里本来只留下 1kw 个元素,但是整体上来过了上亿的流水元素,布隆过滤器很无奈,它会将这些流失的元素的印迹也会永远存放在那里。随着时间的流失,这个过滤器会越来越拥挤,直到有一天你发现它的误判率太高了,不得不进行重建。
- 布谷鸟过滤器源于布谷鸟哈希算法,
扩展 Counting Bloom Filter
- 对Bloon的改进
- 如果表达的元素集合经常发生删除等变动,那么Bloom Filter的弊端就出来了,因为它不支持删除操作...
- Counting Bloom Filter的出现解决了这个问题,它将标准Bloom Filter位数组的每一位扩展为一个小的计数器(Counter),在插入元素时给对应的k(k为哈希函数个数)个Counter的值分别加1,删除元素时给对应的k个Counter的值分别减1,Counting Bloom Filter通过多占用几倍的存储空间的代价,给Bloom Filter增加了删除操作。
缓存的清理
1、配置文件中可以设置,以下的回收策略
- noeviction:返回错误当内存限制达到并且客户端尝试执行会让更多内存被使用的命令(大部分的写入指令,但DEL和几个例外)
- allkeys-lru: 尝试回收最少使用的键(LRU),使得新添加的数据有空间存放。
- volatile-lru: 尝试回收最少使用的键(LRU),但仅限于在过期集合的键,使得新添加的数据有空间存放。
- allkeys-random: 回收随机的键使得新添加的数据有空间存放。
- volatile-random: 回收随机的键使得新添加的数据有空间存放,但仅限于在过期集合的键。
- volatile-ttl: 回收在过期集合的键,并且优先回收存活时间(TTL)较短的键,使得新添加的数据有空间存放。
- allkeys-lfu:最近最不经常使用算法,从所有的键中选择某段时间之内使用频次最少的键值对清除;
- volatile-lfu(least frequently used):最近最不经常使用算法,从设置了过期时间的键中选择某段时间之内使用频次最小的键值对清除掉;
- 总结:LRU:多久没用使用了 LFU:使用了多少次 TTL: 只删除接近的过期时间的
2、回收进程如何工作
- 一个客户端运行了新的命令,添加了新的数据。
- Redi检查内存使用情况,如果大于maxmemory的限制, 则根据设定好的策略进行回收。
- 一个新的命令被执行,等等。
3、近似LRU算法
- Redis的LRU算法并非完整的实现。这意味着Redis并没办法选择最佳候选来进行回收,也就是最久未被访问的键。相反它会尝试运行一个近似LRU的算法,通过对少量keys进行取样,然后回收其中一个最好的key(被访问时间较早的)
- 不过从Redis 3.0算法已经改进为回收键的候选池子。这改善了算法的性能,使得更加近似真是的LRU算法的行为。
- Redis LRU有个很重要的点,你通过调整每次回收时检查的采样数量,以实现调整算法的精度。这个参数可以通过以下的配置指令调整:maxmemory-samples 5
过期时间
- 查询不会修改过期时间
- 修改不设置过期时间,会持久化
- 也可以设置到哪个时间点过期
1、Redis如何淘汰过期的keys
-
Redis keys过期有两种方式:被动和主动方式
-
当一些客户端尝试访问它时,key会被发现并主动的过期。
-
定时随机测试设置keys的过期时间。所有这些过期的keys将会从密钥空间删除。
-
具体就是Redis每秒10次做的事情:
- 测试随机的20个keys进行相关过期检测。
- 删除所有已经过期的keys。
- 如果有多于25%的keys过期,重复步奏1.
-
这是一个平凡的概率算法,基本上的假设是,我们的样本是这个密钥控件,并且我们不断重复过期检测,直到过期的keys的百分百低于25%,这意味着,在任何给定的时刻,最多会清除1/4的过期keys。
-
稍微牺牲下内存,但是保住了redis的性能
