

上篇文章分享了如何在微服务的架构下使用 DDD 的限界上下文划分服务边界,而按照一般的设计流程,下一步应该是细化每个限界上下文中应该提供的服务接口,这同样也不是一个简单的工作,所幸的是 DDD 依然可以为我们提供不小的帮助,指导我们设计贴合业务需求的接口。本文会介绍如何围绕 DDD 的聚合来设计微服务的接口。
聚合
聚合是 DDD 中特有的概念,也是核心元素之一。聚合对外封装了一组彼此之间有紧密关系的领域对象,外部只能通过聚合根访问这些领域对象,可以帮助我们将由业务引起的一系列领域对象的状态变化封装在一起,不用担心代码散落在各处,引发后续的难以维护的问题。
每一个事务中只允许一个聚合状态发生变化,这保证了聚合范围内各个领域对象数据约束的一致性。关于更多有关聚合的概念和使用方法可以参考我之前的文章DDD 实践手册(4. Aggregate — 聚合),这里就不再赘述了。
既然聚合如此重要,那么我们如何从业务中找到聚合对象呢?如果抛开对业务熟悉程度,我们可以借助类似「事件风暴」这样的建模框架分析业务流程,挖掘出聚合对象。获得聚合对象之后就可以按照聚合对象上的命令(Command)设计服务接口了。如果想了解「事件风暴」的细节也可以参考我之前的文章 DDD 实践手册(番外篇: 事件风暴-概念) DDD 实践手册(番外篇: 事件风暴-实践)。
微服务中的聚合
聚合是一系列领域对象的集合,因此有可能发生的一种情况就是,某个聚合引用了另一个聚合,这在单体架构的系统中可能关系不大,但是在微服务这一分布式的系统架构中设计可能需要考虑一些额外的东西。
以下是一个微服务中聚合的示例:
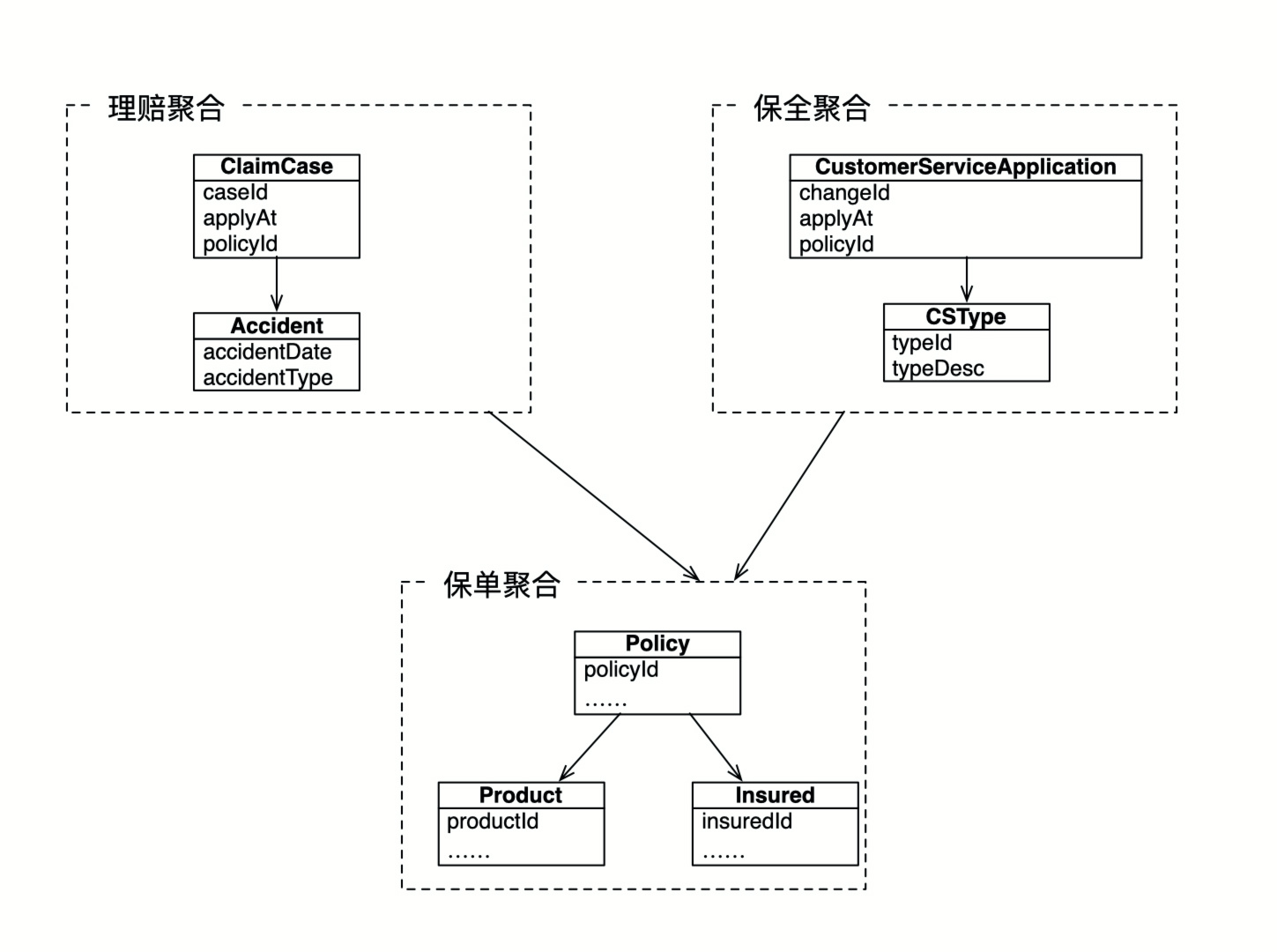
从上图可以看到 ClaimCase 理赔案件与 CustomerServiceApplication 客户服务申请分别是「理赔服务」与「保全服务」的核心聚合对象,作为聚合根,它们都引用了「保单管理服务」中的聚合「Policy」对象。实现的代码如下:
public class ClaimCase {
private Long policyId;
......
}
public class CustomerServiceApplication {
private Long policyId;
......
}
public class Policy {
private Long policyId;
}
与普通做法不同的地方在于 ClaimCase 与 CustomerServiceApplication 对象都没有直接引用 Policy 对象,而只是通过 Policy 的唯一标识policyId 进行了引用。这样做的优点在于不需要引用其他服务的数据结构。在进行微服务拆分之后,每个微服务都可以独立编译,打包,部署,而服务之间也应该保持松耦合的关系,如果一旦依赖了某个服务的数据结构,那么后期维护的工作会十分麻烦,且容易引起其他的依赖问题。所以在分布式微服务的架构下,聚合之间应该通过唯一键进行关联而不是某个具体的数据结构。
服务接口
在有了完整的聚合之后,就可以着手定义单个服务应该提供哪些接口了。如果是通过「事件风暴」找到服务内的聚合,那么聚合上会有对应的事件和命令,一般而言一个命令可以对应一个服务接口,但是在实现具体服务接口时需要注意以下两点:
使用适配器分离协议与实现
使用 DDD 实现业务逻辑时应该使用 POJO 即普通 Java 对象,而不依赖于某个特殊的框架,同时提供的服务接口也不应该依赖于某种远程通信协议。具体实现可以有多种不同的参考模型,例如「洋葱架构」,「整洁架构」或是「六边形架构」,下图是我个人比较偏爱的六边形架构的示意图:
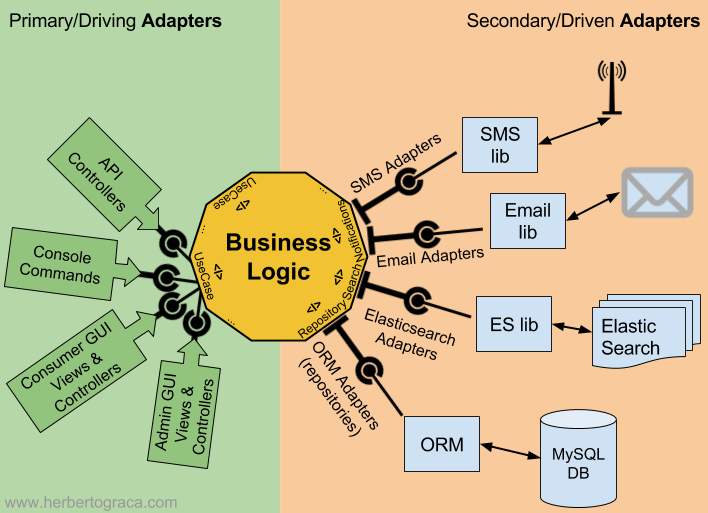
图上分为左右两边,左边是「入站适配器」,右边是「出站适配器」。中间核心的是通过 DDD 和 POJO 实现的业务逻辑。通过不同的适配器,可以向领域层屏蔽各种基于不同技术的底层实现。
在「入站适配器」中需要注入 DDD 中的 Application Service,由 Application Service 执行真正的业务逻辑。「入站适配器」的主要工作就是按照不同的协议将传入的参数转化为 Application Service 的方法参数,例如 RESTful 的适配器会自动将 JSON 格式的数据转化为 Java 对象,而 gRPC 的适配器会按照 protocol buffers 文件将二进制数据反序列化为 Java 对象。
而在「出站适配器」的使用中,它会被 Domain Service 所注入,由 Domain Service 调用它的方法,执行对应的逻辑,例如将领域对象进行持久化操作,或是发送领域事件等。
分布式事务与最终一致性
一个服务接口可能要更新多个聚合,但是为了遵循每个事务只更新一个聚合的限制,就需要将其他更新聚合的操作放在不同的事务中。而在微服务的架构中,更新多个聚合就会牵涉到多次的远程服务调用,这就不免牵涉到分布式事务。
在以远程通信为主要交互手段的微服务架构中,我们不应该追求 ACID 的事务特性,因为这会极大的降低系统的吞吐性和稳定性。对应的我们应该更多的依赖于 BASE(「B」asically 「A」vailable, 「S」oft state, 「E」ventual consistency) 的分布式事务。在具体使用上分布式事务是个较为复杂的领域,可以衍生出更多有意思的话题,例如各种分布式事务的实现模型,如何实现幂等接口,这些话题我会专门通过几篇文章来分享,分别使用本地事务日志,saga模型以及阿里的 Seata 框架来实现分布式事务。
DDD 中则可以通过领域事件的方式,将聚合状态更新完成的事件通过消息中间件发送出去,通知其他的服务,进而完成其他聚合对象的状态更新。具体的代码可以参考之前的文章: DDD 中的那些模式 — 领域事件
小结
通过「事件风暴」和 DDD 这样的建模工具能够很快的识别出业务流程中的聚合对象,在服务边界划分完成的情况下,基于聚合对象可以进一步发现各种服务接口。分离领域逻辑和具体的技术实现后,微服务的范围,功能就会很清晰的浮现出来。相对于单体架构的应用,DDD 的确可以为我们降低业务带来的复杂度,但同时也引入了固有的技术复杂度,例如分布式事务。下一篇文章中我会分享如何使用 saga 模型实现最终一致性,让微服务真正变的有价值。
欢迎关注我的微信号「且把金针度与人」,获取更多高质量文章

