

策略模式最常见的应用场景是,利用它来避免冗长的 if-else 或 switch 分支判断,以及提供框架的扩展点等。
1. 原理与实现
在 GoF 的《设计模式》一书中,它是这样定义的:Define a family of algorithms, encapsulate each one, and make them interchangeable. Strategy lets the algorithm vary independently from clients that use it。即定义一族算法类,将每个算法分别封装起来,让它们可以互相替换。策略模式用于解耦策略的定义、创建、使用这三部分。
实际上,一个完整的策略模式就是由这三个部分组成的。
- 策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。
- 策略的创建由工厂类来完成,封装策略创建的细节。
- 策略模式包含一组策略可选,使用算法的代码如何选择使用哪个策略,有两种确定方法:编译时静态确定和运行时动态确定。其中,“运行时动态确定”才是策略模式最典型的应用场景。
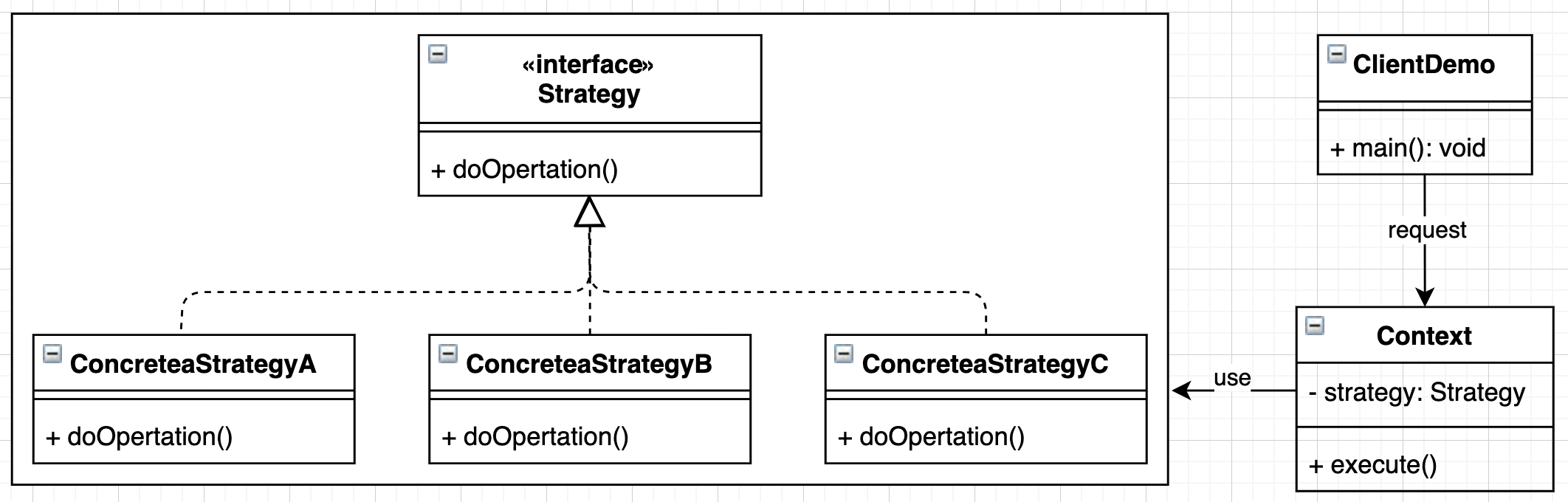
如上图,左侧方框内则是策略接口以及具体的接口类实现,右侧上下文类 Context 则是负责响应客户端代码 ClientDemo 的要求获取以及执行相应策略。由图中也可以看出策略模式是符合对扩展开发,对修改关闭的开闭原则。
1.1. 策略的定义
策略类的定义比较简单,包含一个策略接口和一组实现这个接口的策略类。因为所有的策略类都实现相同的接口,所以使用算法的代码基于接口而非实现编程,可以灵活地替换不同的策略。示例如下:
// 策略的定义
type Strategy interface {
doOperation()
}
// 策略 A
type ConcreteStrategyA struct{}
func newStrategyA() *ConcreteStrategyA {
return &ConcreteStrategyA{}
}
func (csA ConcreteStrategyA) doOperation() {
// do something...
}
// 策略 B
type ConcreteStrategyB struct{}
func newStrategyB() *ConcreteStrategyB {
return &ConcreteStrategyB{}
}
func (csB ConcreteStrategyB) doOperation() {
// do another something...
}
得益于 Go 语言的接口实现方便性,我们所有策略实现一个接口,这样使用策略的代码基于接口而非实现编程,可以灵活地替换不同的策略。
1.2. 策略的创建与使用
定义好一组策略以后,在使用它们时,则一般是根据策略相应的类型进行创建。为了能够对创建行为进行封装,则会使用工厂模式来屏蔽创建细节,一般把根据类型创建的代码逻辑抽离至工厂函数中。
// 策略的创建
type Context struct {
strategy Strategy
}
func (c Context) Execute() {
c.strategy.doOperation()
}
// 此处等同于一个工厂函数进行创建的作用
func NewContext(strategyType string) *Context {
c := new(Context)
switch strategyType {
case "csA":
c.strategy = newStrategyA()
case "csB":
c.strategy = newStrategyB()
default:
panic("unavailable strategy")
}
return c
}
而到这一步时,策略模式的使用就已经很方便了,只需要获得你需要策略的类型,然后交给工厂函数获得策略实例即可。
实际上在代码逻辑里事先就写死策略的类型这种获取策略的方式是一种“非动态时确定”,这种方式并不能发挥策略模式的优势,而是更加符合“基于接口而非实现编程原则”。策略模式最典型的使用场景是我们事先并不知道会使用哪个策略,而是在程序运行期间,根据配置、用户输入、计算结果等这些不确定因素,动态决定使用哪种策略。例如:
// 策略的使用
// 运行时动态确定,根据配置文件的配置决定使用哪种策略
func application() {
// ...
strategyType := "" // 运行时从配置文件或者数据库中读取策略类型
context := NewContext(strategyType)
context.strategy.doOperation()
// ...
}
2. 优化代码
上一节描述了策略模式是什么样,并且进行了简单的实现,然而在进行策略创建的工厂函数中,我们依然会发现使用了 switch-case 结构进行类型到策略的选择,当策略选择逐渐增多时,就会出现冗长的 switch-case 结构,显然这并不符合我们这篇文章的标题。
那么如何使用策略模式来优化冗长的 if-else 结构或者 switch-case 结构呢?本质上讲,就是借助“查表法”,根据 type 查表替代根据 type 分支判断。
借助一个例子,假设有这样一个需求,希望写一个小程序,实现对一个文件进行排序的功能,文件中只包含整型数并且相邻的数字通过逗号来区隔。很明显,这道题目分四种情况:
- 文件非常小,直接快速排序算法;
- 文件大小大于内存,则使用外部排序;
- 文件更大一些,则可以利用CPU多核,多线程处理文件排序;
- 文件非常大以至于单个主机处理不了,则是使用 MapReduce 框架,利用多机的处理能力,提高排序的效率。
显然这个情况是根据文件的大小不同来选择不同的排序策略,我们就可以使用策略模式进行实现,依然是分别从策略的定义、创建以及使用三个模块展示以加深策略模式的理解。
package strategy
// 排序策略定义
type SortAlg interface {
sortFile(path string)
}
type QuickSort struct{}
func (qs QuickSort) sortFile(path string) {
// ...
}
type ExternalSort struct{}
func (es ExternalSort) sortFile(path string) {
// ...
}
type ConcurrentExternalSort struct{}
func (ces ConcurrentExternalSort) sortFile(path string) {
// ...
}
type MapReduceSort struct{}
func (mps MapReduceSort) sortFile(path string) {
// ...
}
策略的创建依然是一个主要接口以及多个实现该接口的策略类,然后使用策略的代码即可基于该接口而不用基于实现编程。然后是建立包含策略引用的上下文 Context 类,该类用以策略的创建,类比于工厂函数的作用。
// 策略创建
type SortContext struct {
filePath string
sortAlg SortAlg
}
func (sc SortContext) Execute() {
sc.sortAlg.sortFile(sc.filePath)
}
func NewSortContext(filePath string) *SortContext {
GB := 1000 * 1000 * 1000
fileSize := getFileSize(filePath)
sc := new(SortContext)
sc.filePath = filePath
if fileSize < 6*GB {
sc.sortAlg = QuickSort{}
} else if fileSize < 10*GB {
sc.sortAlg = ExternalSort{}
} else if fileSize < 100*GB {
sc.sortAlg = ConcurrentExternalSort{}
} else {
sc.sortAlg = MapReduceSort{}
}
return sc
}
func getFileSize(filename string) int {
var result int64
filepath.Walk(filename, func(path string, f os.FileInfo, err error) error {
result = f.Size()
return nil
})
return int(result)
}
然后获得路径使用相应排序策略即可
// 策略的使用
func apply() {
// ...
filePath := "" // 获得文件路径
context := NewSortContext(filePath)
context.sortAlg.sortFile(filePath)
// ...
}
在上述的实现过程我们发现策略创建的 Context 类中 NewSortContext() 函数是连着使用了4个 if-else 结构,我们可以借助查找表来优化这一部分代码。
// 策略创建 B
func NewSortContext(filePath string) *SortContext {
GB := 1000 * 1000 * 1000
fileSize := getFileSize(filePath)
sc := new(SortContext)
sc.filePath = filePath
algs := []AlgRange{}
algs = append(algs, AlgRange{0, 6 * GB, QuickSort{}})
algs = append(algs, AlgRange{6 * GB, 10 * GB, ExternalSort{}})
algs = append(algs, AlgRange{10 * GB, 100 * GB, ConcurrentExternalSort{}})
algs = append(algs, AlgRange{100 * GB, INT_MAX, MapReduceSort{}})
for _, algRange := range algs {
if algRange.inRange(fileSize) {
sc.sortAlg = algRange.getSortAlg()
}
break
}
return sc
}
type AlgRange struct {
start int
end int
alg SortAlg
}
func (ar AlgRange) getSortAlg() SortAlg {
return ar.alg
}
func (ar AlgRange) inRange(size int) bool {
return size >= ar.start && size <= ar.end
}
当前代码相对来说就要更为符合开闭原则了,我们将策略都放入了一个“查找表”中,使用这种方法,在更为复杂的工程中,我们增加策略所需要修改的代码逻辑更少,需要变更代码位置也更集中,将代码改动最小化、集中化,减少出错的可能性。这个示例中我们是放入了 slice 结构里,更多的还可以放入库表或者配置文件中,这样增加更多策略时就能完全不需要修改代码逻辑。
3.小结
实际上,策略模式主要的作用还是解耦策略的定义、创建和使用,控制代码的复杂度,让每个部分都不至于过于复杂、代码量过多。对于复杂代码来说,策略模式还能让其满足开闭原则,添加新策略的时候,最小化、集中化代码改动,减少引入 bug 的风险。
但是并不是任何时候都一定要用策略模式,遵循 KISS 原则,怎么简单怎么来,就是最好的设计,在该项目并不具有扩展价值时,快速实现也是重点目标之一,非得套用策略模式,搞出 n 多类,反倒是一种过度设计。
