

Benchmark测试
我们定义一个Object的结构体,通过改变数组a的长度,来看一下基准测试
package pooltest
import (
"sync"
"testing"
)
type Object struct {
a [1]int
}
var pool = sync.Pool{
New: func() interface{} { return new(Object) },
}
func BenchmarkNoPool(b *testing.B) {
var p *Object
for i := 0; i < b.N; i++ {
p = &Object{}
p.a[0]++
}
}
func BenchmarkPool(b *testing.B) {
var p *Object
for i := 0; i < b.N; i++ {
p = pool.Get().(*Object)
p.a[0]++
pool.Put(p)
}
}
BenchmarkNoPool-8 66389622 16.4 ns/op 8 B/op 1 allocs/op
BenchmarkPool-8 60043473 19.6 ns/op 0 B/op 0 allocs/op
内存上,Pool是做到了0B/op,但是时间上,会稍高一些
增加a的长度,增加为32
BenchmarkNoPool-8 20242838 55.8 ns/op 256 B/op 1 allocs/op
BenchmarkPool-8 59660236 20.0 ns/op 0 B/op 0 allocs/o
在时间上,使用Pool已经比不使用快了一倍左右
继续增加a的长度到1024
BenchmarkNoPool-8 1034014 1139 ns/op 8192 B/op 1 allocs/op
BenchmarkPool-8 61462597 20.2 ns/op 0 B/op 0 allocs/op
时间上,已经差了50倍,并且,随着数据长度发生变化,每次操作的时间都很稳定,基本在20ns附近
Pool结构体
type Pool struct {
noCopy noCopy
local unsafe.Pointer // local fixed-size per-P pool, actual type is [P]poolLocal
localSize uintptr // size of the local array
victim unsafe.Pointer // local from previous cycle
victimSize uintptr // size of victims array
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
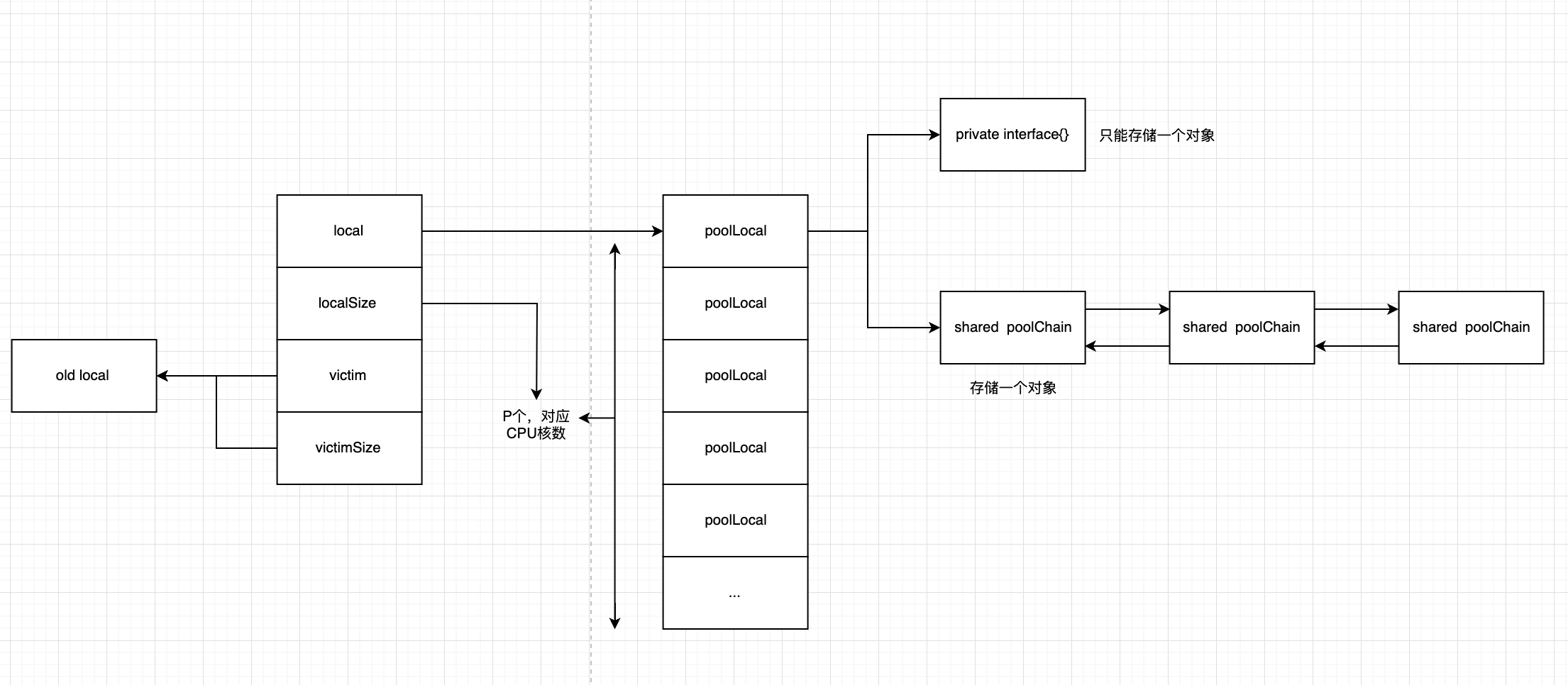
根据结构体,可以看到,缓存主要存储在private和shared中
对于一个Pool的对象来说,它可能会被任意一个P拥有(假设P的数据是N),因此会有N个poolLocal,每个P都拥有一个poolLocal,不同的P通过local指针访问自己poolLocal
victim则用于存储old local,用于gc回收,poolCleanup介绍该字段的使用
Get
Get的基本策略
- 从Pprivate中读取
- 读取不到,就从shared中读取
- 还读取不到,就尝试从其他P的poolLocal中"偷取"
- 上述都获取不到,通过New接口,创建一个新的
func (p *Pool) Get() interface{} {
...
l, pid := p.pin()
x := l.private
if x == nil {
// Try to pop the head of the local shard. We prefer
// the head over the tail for temporal locality of
// reuse.
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
...
if x == nil && p.New != nil {
x = p.New()
}
...
}
- 首先通过
p.pin()获取当前goroutine绑定的P,以及P对应的poolLocal
// pin pins the current goroutine to P, disables preemption and
// returns poolLocal pool for the P and the P's id.
// Caller must call runtime_procUnpin() when done with the pool.
func (p *Pool) pin() (*poolLocal, int) {
pid := runtime_procPin()
// In pinSlow we store to local and then to localSize, here we load in opposite order.
// Since we've disabled preemption, GC cannot happen in between.
// Thus here we must observe local at least as large localSize.
// We can observe a newer/larger local, it is fine (we must observe its zero-initialized-ness).
s := atomic.LoadUintptr(&p.localSize) // load-acquire
l := p.local // load-consume
if uintptr(pid) < s {
return indexLocal(l, pid), pid
}
return p.pinSlow()
}
当出现以下两种,会执行p.pinSlow()
- localSize未初始化的时候
- P的数量发生变化
p.pinSlow()会进行检查是否需要创建新的local
func (p *Pool) pinSlow() (*poolLocal, int) {
...
if p.local == nil {
allPools = append(allPools, p)
}
size := runtime.GOMAXPROCS(0)
local := make([]poolLocal, size)
atomic.StorePointer(&p.local, unsafe.Pointer(&local[0])) // store-release
atomic.StoreUintptr(&p.localSize, uintptr(size)) // store-release
return &local[pid], pid
}
可以看到pinSlow函数,如果当前P的个数是N,则会创建一个poolLocal的切片,切片的长度是N,并且返回当前P对应的poolLocal
- 继续Get函数,获取到P对应的poolLocal后,会检查private是否有对象可以复用,有就直接返回,如果没有,就尝试查找shared
shared是一个无锁队列,具体实现在poolqueue.go文件中
poolqueue.go中无锁队列的思想:implement lock free
- shared中获取不到的话,就会进入
getSlow进行查找
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize) // load-acquire
locals := p.local // load-consume
// Try to steal one element from other procs.
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
...
// Try the victim cache. We do this after attempting to steal
// from all primary caches because we want objects in the
// victim cache to age out if at all possible.
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
...
}
getSlow会首先尝试从其他poolLocal的shared中偷取
偷取不到的话,会尝试从victim中偷取
- 全部获取失败,会尝试调用
p.New创建一个新的对象
Put
Put的实现,相对来说就比较简单
- 先放到private上
- 失败的话,放入shared中
// Put adds x to the pool.
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
if race.Enabled {
if fastrand()%4 == 0 {
// Randomly drop x on floor.
return
}
race.ReleaseMerge(poolRaceAddr(x))
race.Disable()
}
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
if race.Enabled {
race.Enable()
}
}
poolCleanup
pool中的对象,也会被GC回收,基于源码,
在第一次GC中,移动local到victim中,此时,由于仍然有victim引用,所以没有被清扫
在第二次GC中,victim中被重新覆盖,victim的旧值失去了引用,将会在本次GC中被清扫
所以pool最多会在两次GC后被清扫
func poolCleanup() {
// This function is called with the world stopped, at the beginning of a garbage collection.
// It must not allocate and probably should not call any runtime functions.
// Because the world is stopped, no pool user can be in a
// pinned section (in effect, this has all Ps pinned).
// Drop victim caches from all pools.
for _, p := range oldPools {
p.victim = nil
p.victimSize = 0
}
// Move primary cache to victim cache.
for _, p := range allPools {
p.victim = p.local
p.victimSize = p.localSize
p.local = nil
p.localSize = 0
}
// The pools with non-empty primary caches now have non-empty
// victim caches and no pools have primary caches.
oldPools, allPools = allPools, nil
}
func gcStart(trigger gcTrigger) {
...
// stop the world, before gc
// clearpools before we start the GC. If we wait they memory will not be
// reclaimed until the next GC cycle.
clearpools()
...
}
func clearpools() {
// clear sync.Pools
if poolcleanup != nil {
poolcleanup()
}
...
}
使用GC做Benchmark,在每一次Put之后强制触发GC
package main
import (
"runtime"
"testing"
)
type Object struct {
a [1024]int
}
var pool = sync.Pool{
New: func() interface{} { return new(Object) },
}
func BenchmarkNoPool(b *testing.B) {
var p *Object
for i := 0; i < b.N; i++ {
p = &Object{}
p.a[0]++
runtime.GC()
}
}
func BenchmarkPool(b *testing.B) {
var p *Object
for i := 0; i < b.N; i++ {
p = pool.Get().(*Object)
p.a[0]++
pool.Put(p)
runtime.GC()
}
}
BenchmarkNoPool-8 7579 154017 ns/op 8199 B/op 1 allocs/op
BenchmarkPool-8 8557 140615 ns/op 7252 B/op 2 allocs/op
内存消耗上,差异变得很小
如果减小数组的长度,pool的内存消耗要高于不使用pool
