

范式可以粗略的理解为一张数据表的表结构所符合的某种设计标准的级别。就像装修材料,最环保的是E0级,接下来是E1级,E2级....,数据库的范式也分为1NF, 2NF, 3NF, BCNF, 4NF, 5NF. 一般我们设计数据库表的时候,最多考虑到BNCF, 符合高一级范式的设计,必定符合低一级别的范式。
第一范式(1NF)
先来解释一下1NF,1NF最好理解。
解释
1NF的定义:符合1NF的关系中的每个属性都不可再分
下表就不符合1NF的定义,进货和销售属性还可以更进一步的拆分
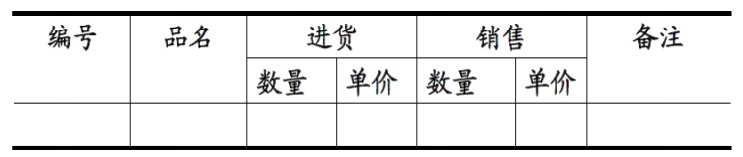
表1
应该设计成下表

表2
缺陷
仅仅满足第一范式的设计规范,仍然会存在数据冗余过大,插入异常,修改异常的问题。
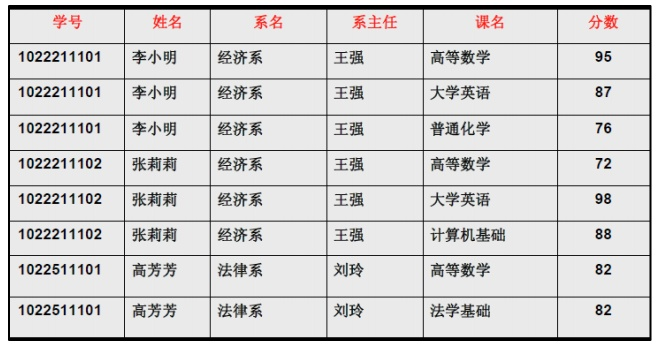
表3
数据冗余
每一名学生的学号、姓名、系名、系主任这些数据重复多次。每个系与对应的系主任的数据也重复多次——数据冗余过大。
插入异常
假如学校新建了一个系,但是暂时还没有招收任何学生(比如3月份就新建了,但要等到8月份才招生),那么是无法将系名与系主任的数据单独地添加到数据表中去的。
删除异常
假如将某个系中所有学生相关的记录都删除,那么所有系与系主任的数据也就随之消失了(一个系所有学生都没有了,并不表示这个系就没有了)
修改异常
假如李小明转系到法律系,那么为了保证数据库中数据的一致性,需要修改三条记录中系与系主任的数据。
正是因为第一范式存在着这么多的问题,所以才会需要提高设计标准。
第二范式(2NF)
第二范式简单点的解释,在1NF的基础,要求其他字段都完全依赖于主键。
注意是完全依赖,而不是部分依赖。
完整点的解释是,2NF在1NF的基础之上,消除了非主属性对于码的部分函数依赖,这句话涉及到了四个概念,函数依赖,码,非主属性,部分函数依赖。 下面来进行解释。
函数依赖
若在一张表中,在属性(属性组)X确定的情况下,必能确定属性Y的值,那么就说Y函数依赖于X,写作 X->Y .
比如:
- 学号 -> 姓名
- (学号,课名)→ 分数
由函数依赖,又可以引申出以下三个概念,部分函数依赖,完成函数依赖,传递函数依赖
部分函数依赖
假如 Y 函数依赖于 X,但是X 的存在一个真子集(假如属性组 X 包含超过一个属性的话),使得X' → Y同样成立的话。那么就称为部分函数依赖,我们写作
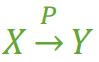
(学号,课名)P→ 姓名
完成函数依赖
若 X → Y,且对于 X 的任何一个真子集(假如属性组 X 包含超过一个属性的话),X ' → Y 不成立,那么我们称 Y 对于 X 完全函数依赖,写作
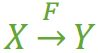
(学号,课名) F→ 分数
传递函数依赖
假如 Z 函数依赖于 Y,且 Y 函数依赖于 X ,那么我们就称 Z 传递函数依赖于 X ,记作 X T→ Z。
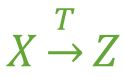
上表中,系 -> 系主任, 学号 -> 系, 所在存在 学号 T→ 系主任。
码
设 K 为某表中的一个属性或属性组,若除 K 之外的所有属性都完全函数依赖于 K, 那么,我们就称K为候选码,也简称为码,一张表中可以有多个码。
例如,**(学号,课名)**这个属性组就是码,表3中仅有这一个码。
非主属性
包含在任何一个码中的属性都是主属性。
例如,表3中,主属性就要两个学号与课名。
符合2NF的表设计
现在我们对表3来进行,符合2NF的拆分。
- 找出表中的所有码 -----------> (学号和课名)
- 根据码,得到主属性 -----------> 学号 课名
- 查看是否存在,非主属性对码的传递依赖
可以,画出下图。
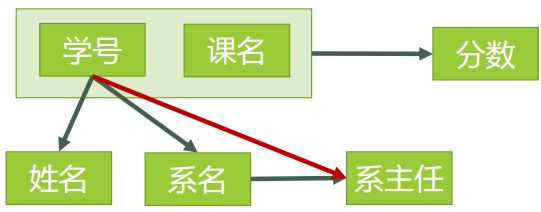
图1
为了符合2NF,需要消除,姓名,系名,系主任 对于主键**(学号,课名)**,存在的传递函数依赖。所以,需要做图2的拆分。
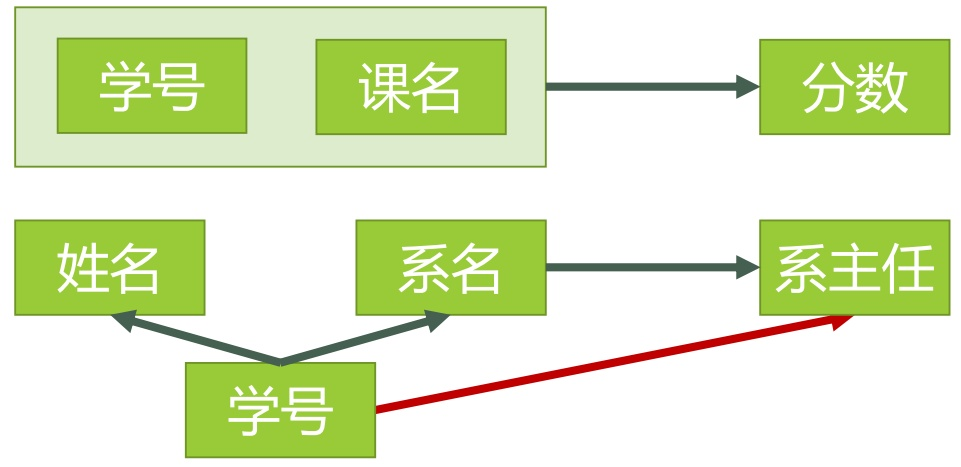
图2
拆解完以后的数据:
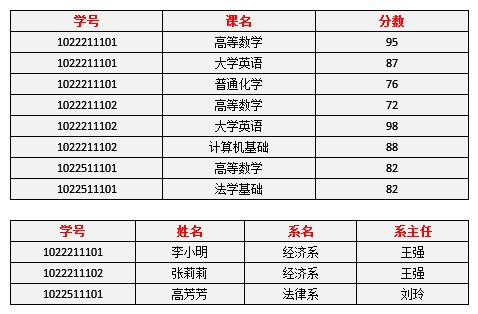
修正和缺陷
现在来看看,2NF相比较于1NF修正了哪些缺陷,但又继续存在哪些不足。
数据冗余(fixed)
学生的姓名、系名与系主任,不再像之前一样重复那么多次了。——有改进
修改异常(fixed)
李小明转系到法律系,只需要修改一次李小明对应的系的值即可。——有改进
删除异常(exists)
删除系中所有学生的记录,该系的信息仍然丢失。
插入异常(exists)
插入一个尚无学生的新系的信息, 因为学生表的码是空的,主键不能为空,所以无法插入一个新系的信息。
所以说,仅仅符合2NF, 还是会存在很多问题,问题的关键在于非主属性系主任存在对于码学号的传递依赖。所以才有更加严格的第三范式。
第三范式(3NF)
解释
通俗点来讲,第三范式的解释是,在2NF的基础之上,3NF消除了非主属性对于码的传递函数依赖.
在图2的设计中,存在 学号 F→ 系名, 同时 存在着 系名 F→ 系主任, 也就是存在 学号T→ 系主任。
所以,为消除系主任 传递依赖于 学号,现在修改表设计入图3.
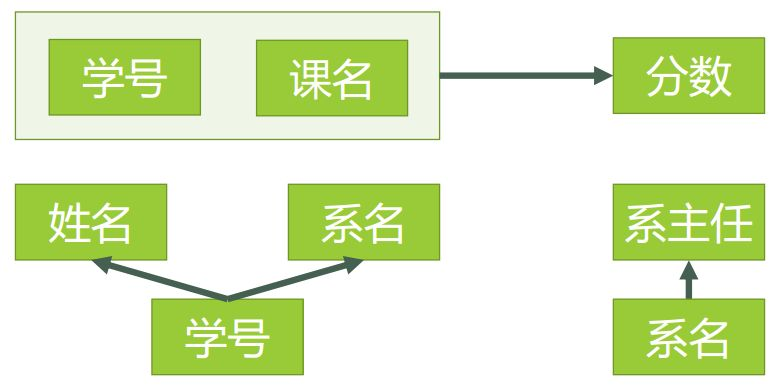
新的数据,如下图
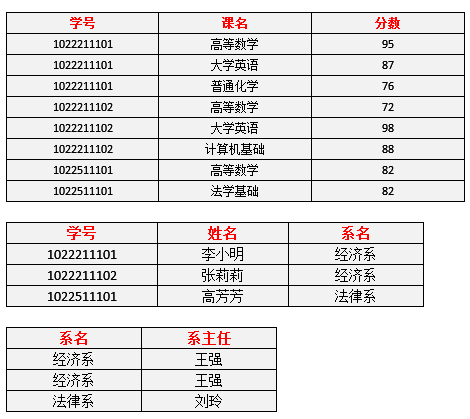
修正
现在来看看,3NF修正了2NF的哪些缺陷。
删除异常(fixed)
删除某个系中所有的学生记录,该系的信息不会丢失
插入异常(fixed)
插入一个尚无学生的新系的信息。因为系表与学生表目前是独立的两张表,所以不影响。
数据冗余(optimization)
相比较于2NF表结构的数据,系名和系主任的信息存储更加优化了。
总结
可以看到呀,符合3NF设计的表结构,基本(注意不是完全)上解决了数据冗余过大,插入异常,修改异常,删除异常,但是越符合范式的规范越高,表结构会被拆分得越加的散碎,往往会带来性能上的问题。所以一般的表设计为了性能和扩展的需求,经常只做到了2NF.
现在来说说为什么上一段是基本,而不是完全,因为还存在着一种情况:主属性对于码的部分函数依赖与传递函数依赖,这就是BCNF的要求。更加详细的信息可以参照:参考文章的内容。
本文参考自知乎用户刘慰如何理解关系型数据库的常见设计范式?的回答
