

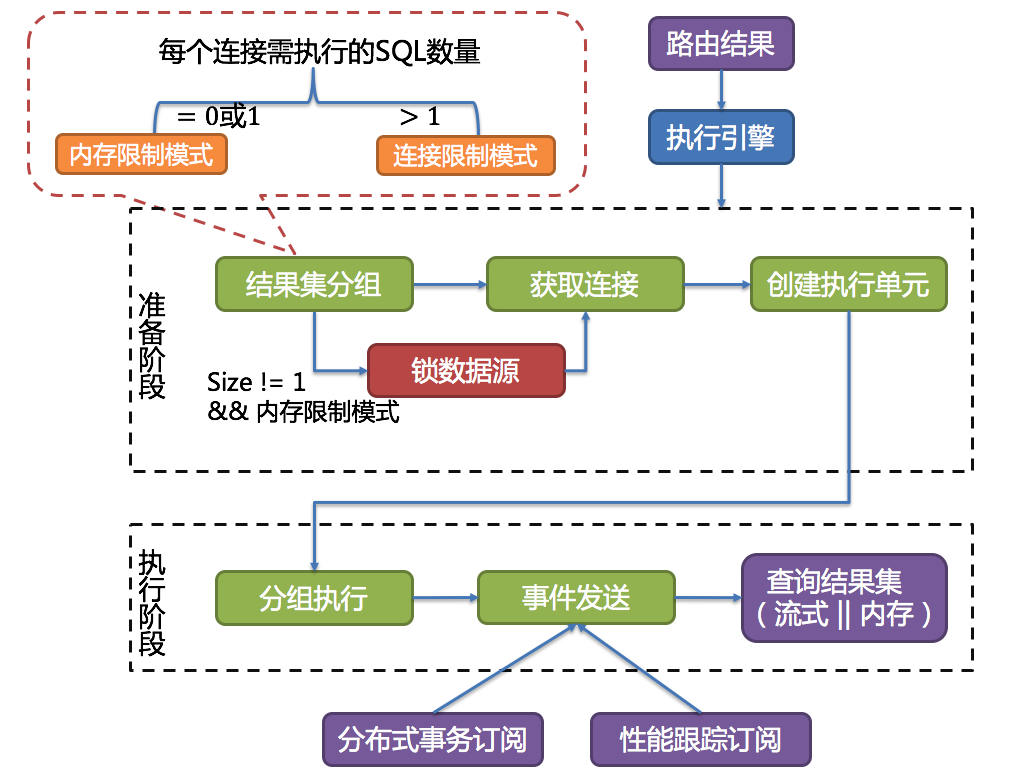
分组执行将准备执行阶段生成的执行单元分组下发至底层并发执行引擎,并针对执行过程中的每个关键步骤发送事件。 如:执行开始事件、执行成功事件以及执行失败事件。执行引擎仅关注事件的发送,它并不关心事件的订阅者。 SS的其他模块,如:分布式事务、调用链路追踪等,会订阅感兴趣的事件,并进行相应的处理。
- 通过SQLExecuteCallbackFactory获取执行回调,里面很简单就是创建了一个SQLExecuteCallback用来真正的执行sql
public boolean execute() throws SQLException {
boolean isExceptionThrown = ExecutorExceptionHandler.isExceptionThrown();
SQLExecuteCallback<Boolean> executeCallback = SQLExecuteCallbackFactory.getPreparedSQLExecuteCallback(getDatabaseType(), isExceptionThrown);
List<Boolean> result = executeCallback(executeCallback);
if (null == result || result.isEmpty() || null == result.get(0)) {
return false;
}
return result.get(0);
}
- 进入ExecutorEngine#execute(),执行引擎开始执行,serial为false,代表是并行执行,猜测一下什么时候会是true,我想应该是参数=1 的时候,可以验证一下,我们看下parallelExecute方法
public <I, O> List<O> execute(final Collection<InputGroup<I>> inputGroups,
final GroupedCallback<I, O> firstCallback, final GroupedCallback<I, O> callback, final boolean serial) throws SQLException {
if (inputGroups.isEmpty()) {
return Collections.emptyList();
}
return serial ? serialExecute(inputGroups, firstCallback, callback) : parallelExecute(inputGroups, firstCallback, callback);
}
- inputGroups是准备阶段的结果,这段代码里,第一个同步执行,剩下的都异步执行
private <I, O> List<O> parallelExecute(final Collection<InputGroup<I>> inputGroups, final GroupedCallback<I, O> firstCallback, final GroupedCallback<I, O> callback) throws SQLException {
Iterator<InputGroup<I>> inputGroupsIterator = inputGroups.iterator();
InputGroup<I> firstInputs = inputGroupsIterator.next();
Collection<ListenableFuture<Collection<O>>> restResultFutures = asyncExecute(Lists.newArrayList(inputGroupsIterator), callback);
return getGroupResults(syncExecute(firstInputs, null == firstCallback ? callback : firstCallback), restResultFutures);
}
4.看下异步执行的代码,通过调用线程池的submit方法,执行callback的execute方法,还记得SS有一个配置参数就是设置执行线程数大小,就是在这里的线程池,返回ListenableFuture集合,再去执行我们的第一个同步任务
private <I, O> ListenableFuture<Collection<O>> asyncExecute(final InputGroup<I> inputGroup, final GroupedCallback<I, O> callback) {
final Map<String, Object> dataMap = ExecutorDataMap.getValue();
return executorService.getExecutorService().submit(() -> callback.execute(inputGroup.getInputs(), false, dataMap));
}
5.我们看下具体的sql执行,SQLExecuteCallback#execute0,这段代码里面也看到了SPISQLExecutionHook,这里可以扩展,executeSQL里面就是调用之前创建的callback里面的execute
private T execute0(final StatementExecuteUnit statementExecuteUnit, final boolean isTrunkThread, final Map<String, Object> dataMap) throws SQLException {
...
SQLExecutionHook sqlExecutionHook = new SPISQLExecutionHook();
try {
ExecutionUnit executionUnit = statementExecuteUnit.getExecutionUnit();
sqlExecutionHook.start(executionUnit.getDataSourceName(), executionUnit.getSqlUnit().getSql(), executionUnit.getSqlUnit().getParameters(), dataSourceMetaData, isTrunkThread, dataMap);
T result = executeSQL(executionUnit.getSqlUnit().getSql(), statementExecuteUnit.getStatement(), statementExecuteUnit.getConnectionMode());
...
6.执行完成之后 在getGroupResults进行结果汇总,restFutures是刚刚异步执行返回的future,遍历拿到异步执行结果返回,这个结果只是返回了执行是否成功的结果,并没有sql执行结果
private <O> List<O> getGroupResults(final Collection<O> firstResults, final Collection<ListenableFuture<Collection<O>>> restFutures) throws SQLException {
List<O> result = new LinkedList<>(firstResults);
for (ListenableFuture<Collection<O>> each : restFutures) {
try {
result.addAll(each.get());
} catch (final InterruptedException | ExecutionException ex) {
return throwException(ex);
}
}
return result;
}
7.这里是org.apache.ibatis.executor.statement.PreparedStatementHandler#query方法,我们之前所有看的代码都是在ps.execute()方法中,接下来我们看下handleResultSets方法
@Override
public <E> List<E> query(Statement statement, ResultHandler resultHandler) throws SQLException {
PreparedStatement ps = (PreparedStatement) statement;
ps.execute();
return resultSetHandler.<E> handleResultSets(ps);
}
8.继续回到SS中,进入ShardingPreparedStatement#getResultSets,each.getResultSet()拿到了ResultSet,这个对象其实还是一个代理对象HikariProxyResultSet,然后开始做归并
private List<ResultSet> getResultSets() throws SQLException {
List<ResultSet> result = new ArrayList<>(preparedStatementExecutor.getStatements().size());
for (Statement each : preparedStatementExecutor.getStatements()) {
result.add(each.getResultSet());
}
return result;
}
```
9.ShardingPreparedStatement#mergeQuery方法中,我们看到MergeEngine,从这里开始就是属于结果集的归并
```java
private MergedResult mergeQuery(final List<QueryResult> queryResults) throws SQLException {
ShardingRuntimeContext runtimeContext = connection.getRuntimeContext();
MergeEngine mergeEngine = new MergeEngine(runtimeContext.getRule().toRules(), runtimeContext.getProperties(), runtimeContext.getDatabaseType(), runtimeContext.getMetaData().getSchema());
return mergeEngine.merge(queryResults, executionContext.getSqlStatementContext());
}
