

前言
第一篇文章我们用一个小时从安装prophet 到完成预测,并且我们将结果对比了naive的季节信号分解(这个可以看作是简版的prohet,纯原创),发现效果略逊色于naive的方法。
后来我们用lightgbm 再次预测同样的数据集,发现结果远远胜过prophet。
我们也对比了我们的预测结果与kaggle上公开的方法与测试结果,发现我们的lightgbm的结果更好,可能是因为我们做了一定参数调优。
我们的prophet 结果和kaggle大神的预测结果一样“好” (相比于lghtgbm都很差)。
但是facebook 大厂旗下prophet的super power 真的弱爆了吗?
一条code挽救prophet
对于深度学习来说,没有标准化会直接让你的模型跑飞。
对于树模型来说,异常值有的时候让你的feature 变得莫名奇妙的重要。
对于prohet 来说,似乎没有什么特殊的注意事项,也没有要清理数据的必要。
但是问题往往就隐藏在其中。

读取数据
代码依然保持不变。
import pandas as pd
from fbprophet import Prophet, make_holidays
from sklearn.metrics import mean_absolute_error
from fbprophet.plot import add_changepoints_to_plot
file = 'data/PJME_hourly.csv'
raw_df = pd.read_csv(file)
print(raw_df.head(5))
将string 时间转成pandas Timestamp 格式,并且预览head 和tail。
dt_format = '%Y-%m-%d %H:%M:%S'
raw_df['Datetime'] = pd.to_datetime(raw_df['Datetime'], format=dt_format)
raw_df.rename({'PJME_MW': 'y', 'Datetime': 'ds'}, axis=1, inplace=True)
print(raw_df.tail(5))
print(raw_df.describe())
可以看到时间从2002年到2018年,而且顺序似乎也对。
ds y
8734 2002-01-01 01:00:00 30393.0
8735 2002-01-01 02:00:00 29265.0
8736 2002-01-01 03:00:00 28357.0
8737 2002-01-01 04:00:00 27899.0
8738 2002-01-01 05:00:00 28057.0
ds y
140250 2018-08-02 20:00:00 44057.0
140251 2018-08-02 21:00:00 43256.0
140252 2018-08-02 22:00:00 41552.0
140253 2018-08-02 23:00:00 38500.0
140254 2018-08-03 00:00:00 35486.0
为了保险起见,我们对时间轴进行排序。
raw_df = raw_df.sort_values(by=['ds']) # sort by time
print(raw_df.tail(5))
print(raw_df.describe())
根据时间点划分测试集与训练集
split_dt = pd.Timestamp('2015-01-01 00:00:00')
train_df = raw_df[raw_df['ds'] < split_dt]
test_df = raw_df[raw_df['ds'] >= split_dt]
prophet 建模
这里我们依然采用默认的参数。
model = Prophet()
model= model.fit(train_df)
y_hat = model.predict(test_df)
y_test = model.predict(test_df)
fig = model.plot(y_test)
a = add_changepoints_to_plot(fig.gca(), model, y_test)
print(mean_absolute_error(test_df['y'].values, y_test['yhat']))
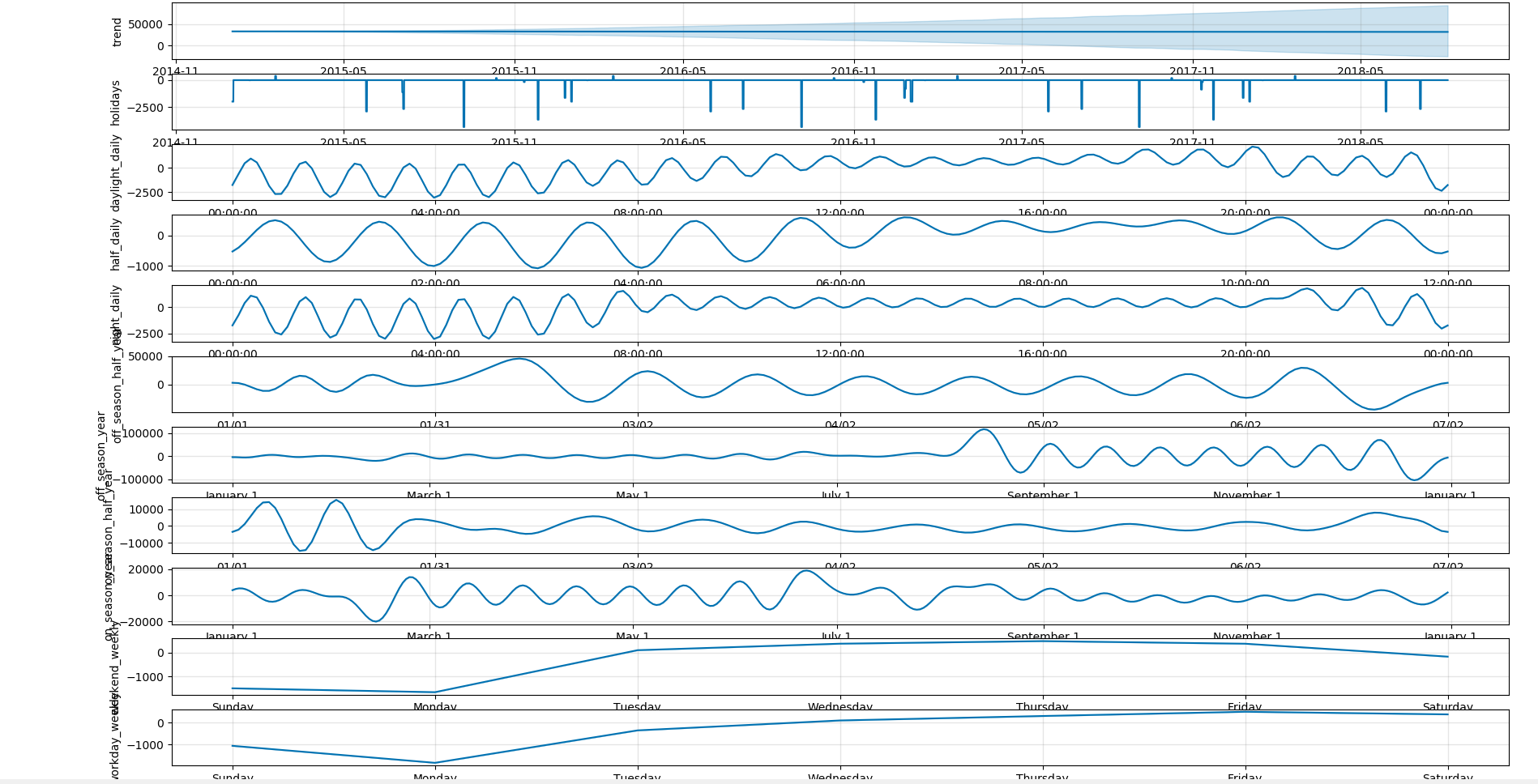
model.plot_components(y_test)
结果
我们可以看到误差结果竟然是3105。相比于我们第2篇的模型以及kaggle大神的5183要好很多。
但是我们的代码几乎没有变,也没有任何的参数调优啊?
3105.4775855473995
原因解析
其实提高的原因很简单,数据有bug!!
其实不是bug,应该是脏数据,而且隐藏的有点深。 一般我们预览head(5) 和tail(5),看到顺序是一致的,我们心里就会默认这个数据是按照时间顺序排列的。其实不是!
当我们预览前30行数据的时候就会发现,日期竟然是倒序的。而且中间还加了莫名其妙的1月1号。
我们代码中不起眼的一句 sort_value 竟然让误差巨幅降低。
而prophet 需要根据时间的先后顺序,提取一定的周期信号。所以观测对象在时间轴上的先后顺序无疑起着决定性作用。
相比于第3 篇介绍的lightgbm,它不会考虑时间的连续性,因此需要我们显式的告诉它一些时间特性,比如我们提取day,year 等信息。
所以prophet 没有那么差,只不过我们需要对数据进行清理,尤其是时间先后顺序。
Datetime,PJME_MW
2002-12-31 01:00:00,26498.0
2002-12-31 02:00:00,25147.0
2002-12-31 03:00:00,24574.0
2002-12-31 04:00:00,24393.0
2002-12-31 05:00:00,24860.0
2002-12-31 06:00:00,26222.0
2002-12-31 07:00:00,28702.0
2002-12-31 08:00:00,30698.0
2002-12-31 09:00:00,31800.0
2002-12-31 10:00:00,32359.0
2002-12-31 11:00:00,32371.0
2002-12-31 12:00:00,31902.0
2002-12-31 13:00:00,31126.0
2002-12-31 14:00:00,30368.0
2002-12-31 15:00:00,29564.0
2002-12-31 16:00:00,29098.0
2002-12-31 17:00:00,30308.0
2002-12-31 18:00:00,34017.0
2002-12-31 19:00:00,34195.0
2002-12-31 20:00:00,32790.0
2002-12-31 21:00:00,31336.0
2002-12-31 22:00:00,29887.0
2002-12-31 23:00:00,28483.0
2003-01-01 00:00:00,27008.0
2002-12-30 01:00:00,27526.0
2002-12-30 02:00:00,26600.0
2002-12-30 03:00:00,26241.0
2002-12-30 04:00:00,26213.0
2002-12-30 05:00:00,26871.0
高阶的prophet 参数配置
默认的prophet 配置可以让我们快速的建立baseline,但是对于时间序列,我们还可以自定义参数。 这里我们贴出代码,方便大家参考。
添加假日信息
比如我们可以添加美国的假日信息。该假日信息会传递给prophet holiday 参数
holidays = make_holidays.make_holidays_df(range(2002, 2018, 1), 'US')
自定义条件
对于同一个周期,我们可以定义一些条件进行区分。
- 比如一周的周期都是7天,但是前5天是工作日,后两天是周末。
- 或者一天可以分为白天和晚上,它们的周期依然都是1天。
- 一年可能会有淡季和旺季,比如夏天可能是用电高峰期(制冷设备),我们可以这样划分
raw_df['on_season'] = (raw_df['ds'].dt.month > 4) | (raw_df['ds'].dt.month < 8)
raw_df['off_season'] = ~(raw_df['ds'].dt.month > 4) | (raw_df['ds'].dt.month < 8)
raw_df['night'] = (raw_df['ds'].dt.hour > 20) | (raw_df['ds'].dt.hour < 8)
raw_df['daylight'] = ~(raw_df['ds'].dt.hour > 20) | (raw_df['ds'].dt.hour < 8)
raw_df['weekend'] = raw_df['ds'].dt.week > 5
raw_df['workday'] = ~raw_df['weekend']
建立复杂prophet模型
我们可以将模型默认的yearly_seasonality,weekly_seasonality,daily_seasonality 设置为False,然后添加自己定义的周期,或者叠加我们定义的条件。 此外,对于每一个周期,我们可以定义他的权重(prior_scale)。
model = Prophet(
holidays=holidays,
changepoint_prior_scale=0.5,
holidays_prior_scale=10,
seasonality_prior_scale=10,
yearly_seasonality=False,
weekly_seasonality=False,
daily_seasonality=False)
model.add_country_holidays(country_name='US')
model.add_seasonality(name='half_daily',period=0.5,fourier_order=12)
model.add_seasonality(name='daylight_daily',period=1,fourier_order=24,condition_name='daylight')
model.add_seasonality(name='night_daily',period=1,fourier_order=24,condition_name='night')
model.add_seasonality(name='weekend_weekly',period=7,fourier_order=14,prior_scale=10,condition_name='weekend')
model.add_seasonality(name='workday_weekly',period=7,fourier_order=14,prior_scale=10,condition_name='workday')
model.add_seasonality(name='on_season_half_year',period=182.625,fourier_order=24,prior_scale=10,condition_name='on_season')
model.add_seasonality(name='off_season_half_year',period=182.625,fourier_order=24,prior_scale=10,condition_name='off_season')
model.add_seasonality(name='on_season_year',period=365.25,fourier_order=24,prior_scale=10,condition_name='on_season')
model.add_seasonality(name='off_season_year',period=365.25,fourier_order=24,prior_scale=10,condition_name='off_season')
运行结果为:
3043.2366637873324
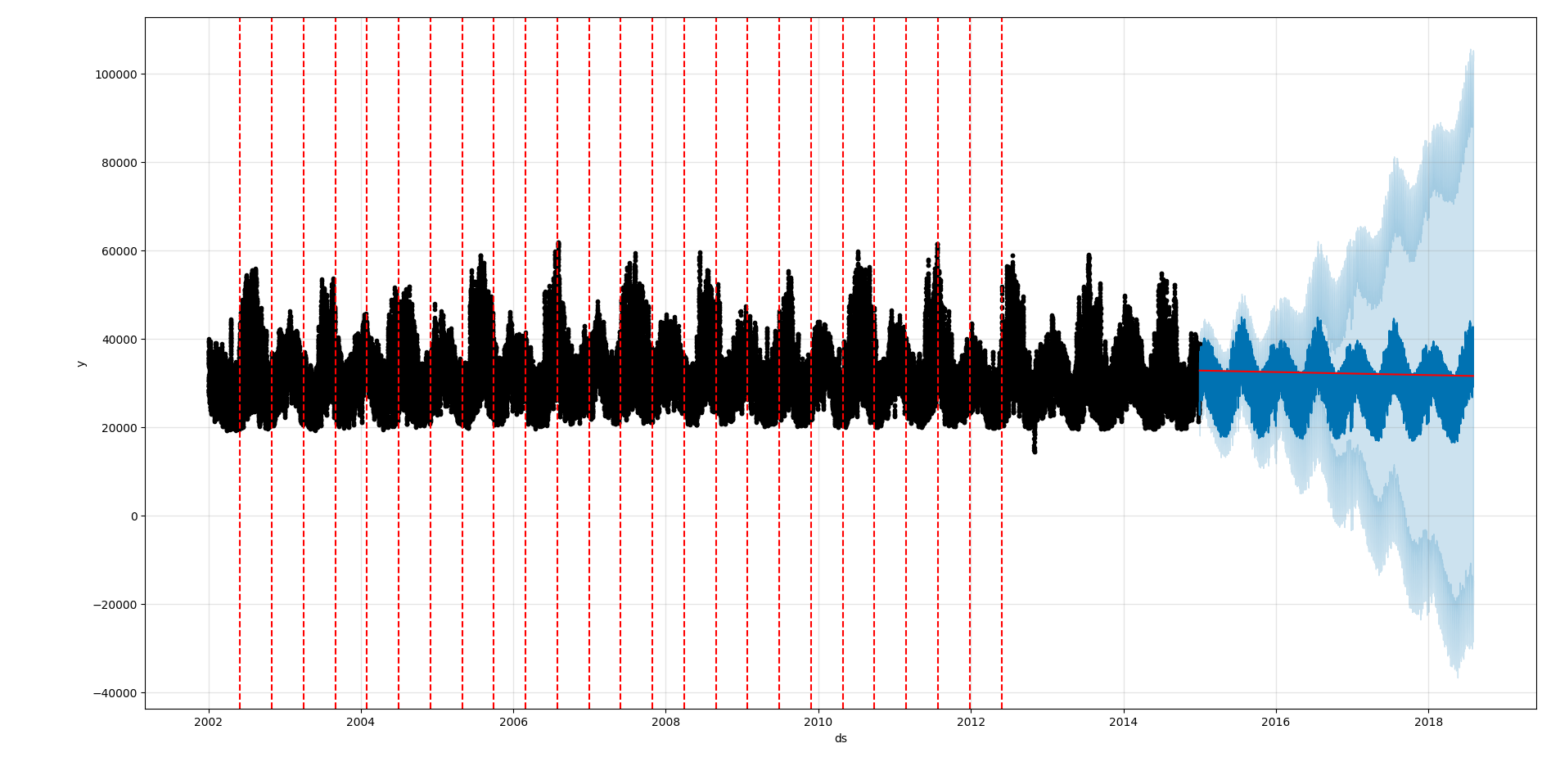
我们依然附上分解的结果:
总结
本文成功解决了prophet 建模时遇到的坑,将误差从5000多降低到3000多。 通过本文可以了解到:
- 时间序列的顺序对于prophet模型的重要性
- 有必要对时间序列的顺序做出验证。
- 可以自定义假日,周期,权重等参数,让模型更贴近预测的时间序列特性
