

在实际项目中会经常去使用Mysql的索引,那么索引为什么会用B+树呢可能又很少有人知道,那么咱们就来专门探讨探讨。
常用数据结构有哪些呢,没错,就是二叉树,红黑树,B-Tree,还有一个B+Tree,那么咱们今天就来讲讲这四种数据结构
既然今天要说说数据结构那么就告知大家一个网站https://www.cs.usfca.edu/~galles/visualization/Algorithms.html,这个网站就是关于数据结构的一个网站
首先二叉树:
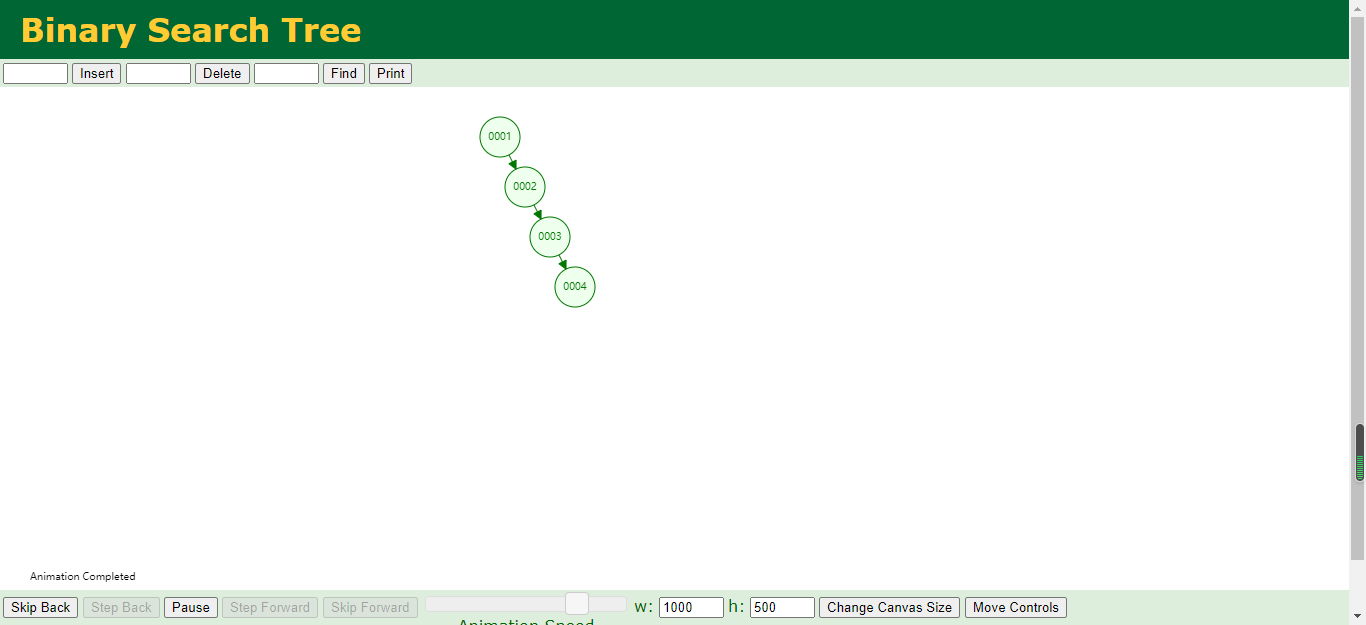
那么不知道大家有没有发现二叉树是怎么样的一个添加方式?
二叉树:
二叉树在插入数据的时候是在根节点依次增加的,有点类似咱们的数组的链表结构,不知道大家有没有发现哈,就像一个火车头牵引着后面的车厢,是单一节点的数据结构,所有的元素都会在原本的父节点下面进行增加,那么咱们在查询的时候效率可能就会比较慢一点,因为他需要一个个的去进行比对。所以在Mysql的数据索引中使用二叉树进行索引查找是非常费时间的,有这个索引和没有这个索引一样的,所以放弃二叉树。
其次咱们来看看红黑树:
红黑树其实在Java中比较重要,在JDK1.8以后的HashMap中就使用到了红黑树。那么红黑树是怎么样存储数据的呢,我们来看看。
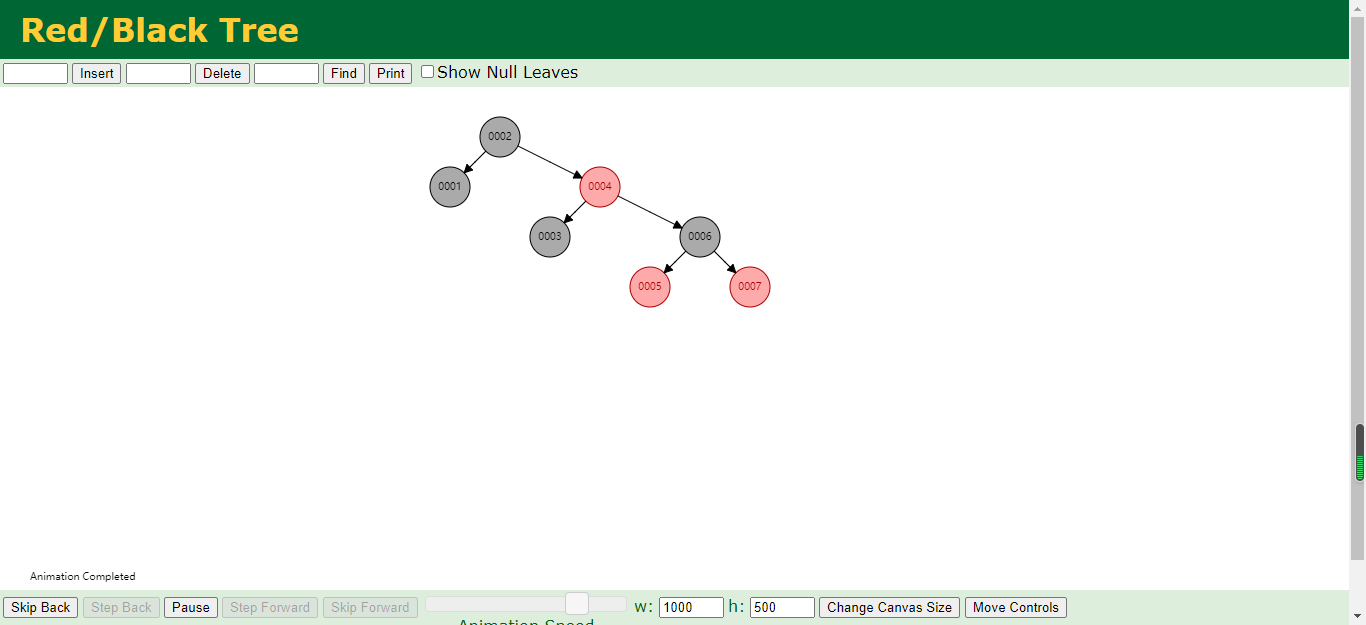
红黑树:
不知道你们有没有发现,可以去试试最开始呢是单边增长的,当单边增长过长的时候会旋转一次变成一个平衡树,也是一种二叉树,只不过他是自旋平衡二叉树,那么查找数据的时候红黑树的查找时间就比二叉树的时间减少一半。但是红黑树在一定场景下有一定的弊端,弊端在哪些地方呢?其实弊端就在于平衡二叉树在数据过多的时候高度会变得特别高,那么查找的时候效率也是特别慢的,并不会因为添加了索引带来很大的优势,所以Mysql放弃使用红黑树的结构作为索引。
再来看看B-Tree:
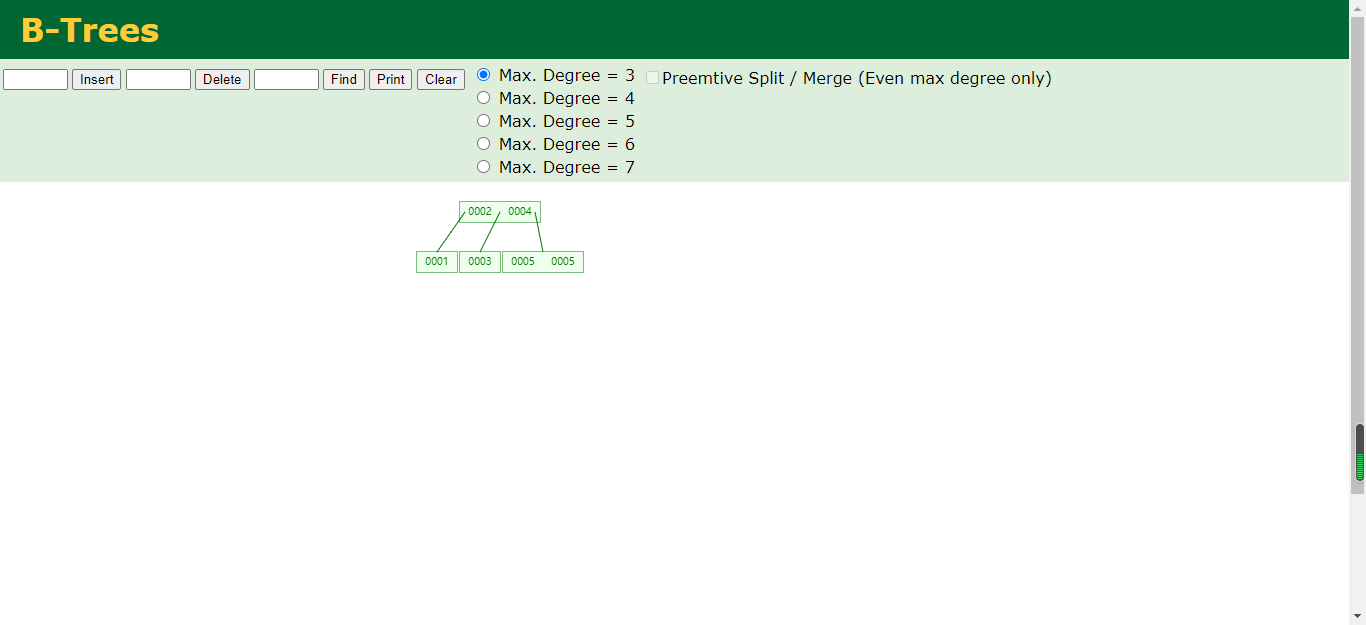
首先这个页面设置的时候那个3,4,5,6,7都是在他们原本的基础上减1的,那么Max.Degree 到底是什么呢,也就是说当长度大于后面的值得时候会取一个中间值作为顶级节点,把其他的数据作为子节点。
B树:
1.叶节点具有相同的深度
2.叶节点的指针为空
3.节点中的数据索引从左到右递增排列
那么为什么Mysql索引不用B-Tree呢,其实也是因为B树的查询也相对过慢,还有就是他的数据是存储在内存的,在数据量大的时候那么内存是吃不消的,而且磁盘加载大量数据的时候很慢,浪费内存空间,不可取。
最后我们来看看B+树
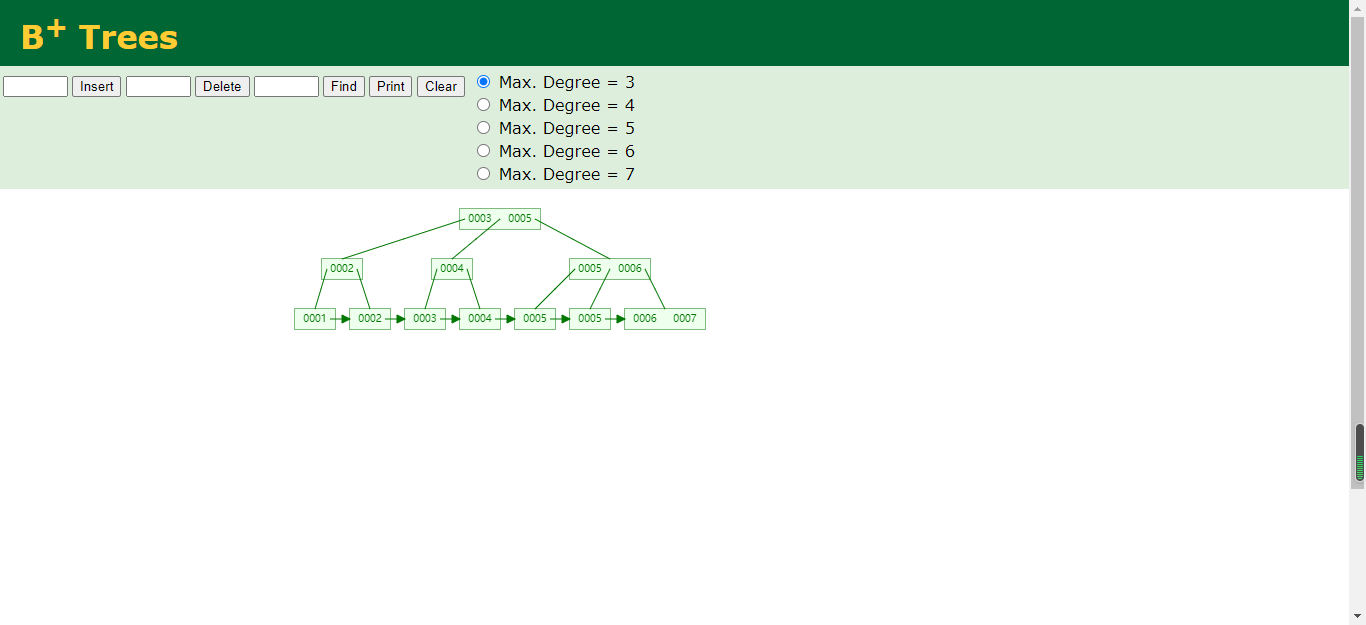
B+树(B树的变种)
1.非叶子节点不存储data,只存储索引,可以放更多的索引
2.叶子节点不存储指针
3.顺序访问指针,提高区间的访问性能
那么B+树,不知道你们发现没有,B+树的存储方式和B树很类似,在子节点存储特别完整的索引,把中间的索引元素往上提做一个冗余放非叶子节点,非叶子节点只会存储索引元素,不会去存储data。这样就可以存储更多的索引元素并减少树的高度。B+树这么设计的目的是在于减少树的高度,Mysql官方进行了修改,每一个节点只会有16KB的大小。可以大概存储2000多万行索引,那么查询的时候最多也就经过3次就能查询到磁盘的数据,那么很快就会找到咱们需要的数据。这也就是为什么Mysql会使用B+树来作为索引。
欢迎大家进行讨论,可能我自己的一些见解也不是很到位,勤劳积累记录见解,不喜勿喷。
