

Github官网:github.com/alibaba/Dat…
DataX是一个单进程多线程的ETL工具; 安装简单,解压即安装,使用方便,配置好任务的json文件,运行即可;
运行流程与原理
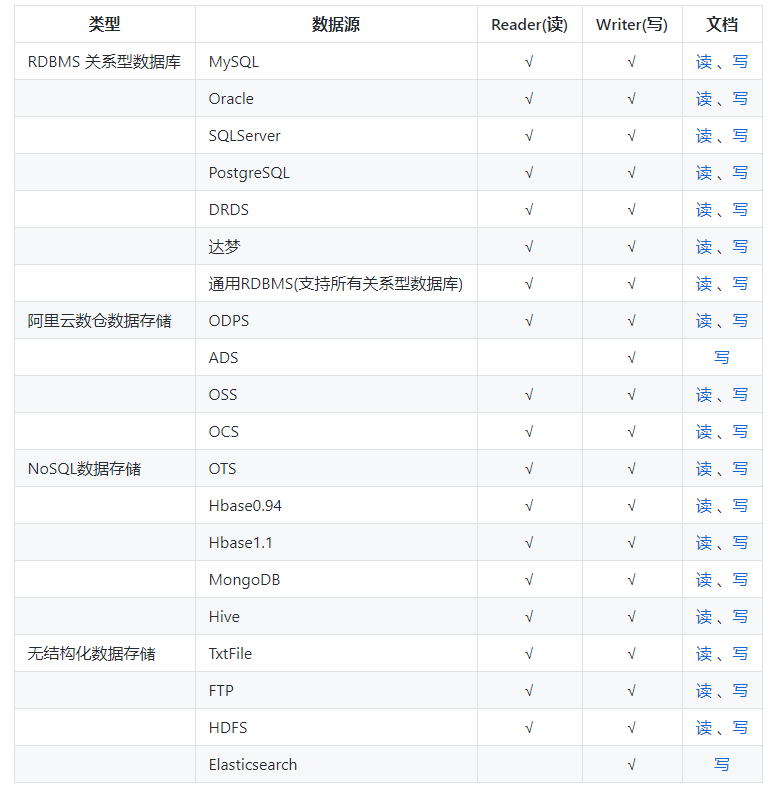
DataX对ETL中行为做了2个抽象:ETL行为抽象成Reader和Writer;
第1层: Reader负责读取数据源, Writer负责写数据目的地;
Reader和Writer通过DataX框架连接;形成一个数据流通管道;
Reader和Writer一一对应,如果有多个Reader/Writer对儿,则有多个数据流通管道;

下载
安装
因为datax是python写的,所以需要linux上安装python2.7,或python3(自带python2.7)
上传datax.tar.gz到服务器的 /opt/soft目录, 解压,tar -zxvf datax.tar.gz
使用
使用datax步骤:
- 配置任务的json配置文件,一个ETL任务对应一个jobxx.json配置文件
- 使用datax.py脚本执行任务 如:python datax.py /opt/soft/datax/job/oracle2hive_***.json 之后等待任务运行完毕即可 如何写任务的配置文件?
配置文件结构:
{ "job":
{ "setting":
{ "speed": { "channel": 5, } },
"content": [
{
"reader": { 编写部分 },
"writer": { 编写部分 }
}
] }
}
其中setting.speed中,channel是DataX的并发度,默认并发度为5;
因为Reader和Writer是一一对应的关系,所以channel的值可以视为是DataX任务中数据管道的数量;
但是在实际ETL过程中,配置了channel可能不产生效果,实际的DataX并发度由数据源的文件切片数量决定,比如数据源是hdfs上某个文件,这个文件的并发度是3,有3个文件,则Datax读取文件时会启动3个并发线程读取,忽视channel中设置的值;
所以,一般setting中不进行多余配置; 只编写reader和writer部分;
如何写reader和writer部分?
注意:
Oracle的读取是通过querySql中写sql实现的,走的是JDBC;
Hive的写入,是通过hdfsWriter写Hdfs实现;
{
"job": {
"setting": {
"speed": {
"channel": 2
}
},
"content": [{
"reader": {
"name": "oraclereader",
"parameter": {
"username": "username",
"password": "password",
"where": "",
"connection": [{
"querySql": [
"select sex,name,to_char(sysdate,'yyyy-mm-dd') from test_table "
],
"jdbcUrl": [
"jdbc:oracle:thin:@192.168.1.143:1521:orcl"
]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "sex",
"type": "string"
},
{
"name": "name",
"type": "string"
},
{
"name": "etl_time",
"type": "string"
}
],
"compress": "gzip",
"defaultFS": "hdfs://172.0.0.0:8020",
"fieldDelimiter": "\t",
"fileName": "dataxtest",
"fileType": "text",
"path": "/apps/hive/warehouse/test.db/t_305_sgrymd",
"writeMode": "append"
}
}
}]
}
}
关于性能
DataX的性能瓶颈主要取决于Reader,Reader读取的速度又取决于数据源文件切片的数量;
速度: oracle 2 hive 可达到117647rec/s ,一秒接近12万条记录
hive 2 hive 可达到463636rec/s ,一秒46万条记录
- 与集群规模有关,仅为测试时速率
注意
千万不要在windows上运行datax任务,由于路径的'\'与'/'区别,会导致任务过程中删除任务临时文件时路径有误,导致删除整个db;
