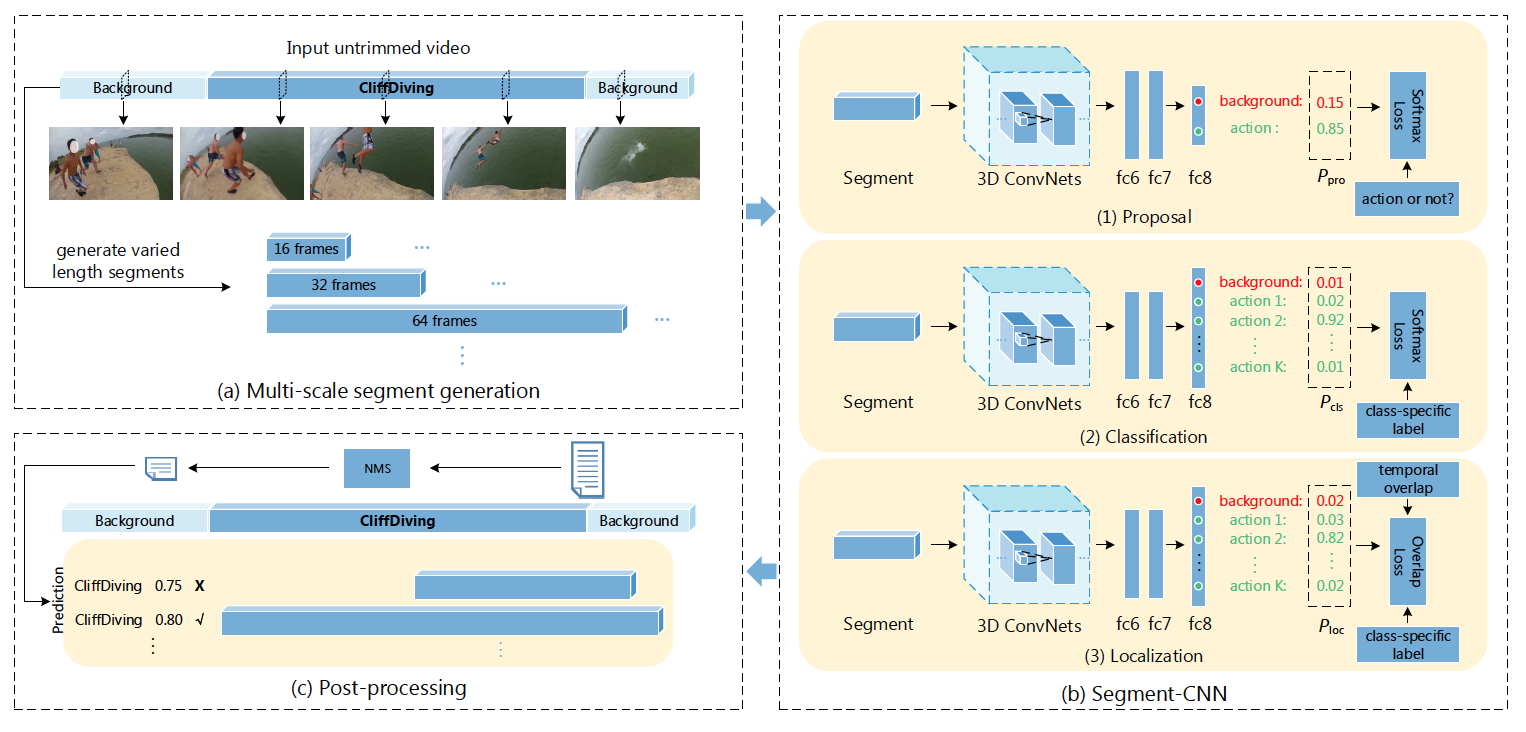
Temporal Action Localization in Untrimmed Videos via Multi-stage CNNs (SCNN)
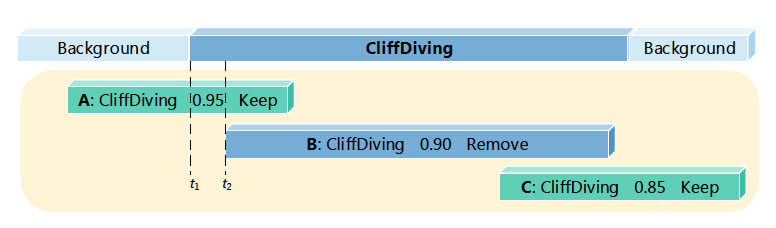
首先用滑窗(overlap:0.7)生成不同尺度的segment,然后固定提取16帧作为候选视频段(在原图上生成候选框,存在计算量大的问题)。整体网络分为三个部分。1)proposal networks:二分类网络,判断每个segment为前景(包含动作)还是背景。然后做正负样本平衡,大致为1:1。 2)classification networks:K+1分类,包括背景类。clas_net只在训练时使用,是为了给后续的localization network做初始化。 3)localization networks:在classification network的基础上增加了overlap loss,用以平衡分类score和iou之间的冲突(某些情况下,预测分类score很高,但iou并不是很高,在NMS的过程中反而会把iou高的proposal去掉)。最终同样做K+1的分类。该网络框架整体逻辑是生成一系列的候选框,用分类的方法做动作的定位,这种方法一般需要较高的候选框重合度,才能保证定位精度,因而计算量比较大。在THUMOS2014数据集上IOU=0.5时达到了19.0的MAP

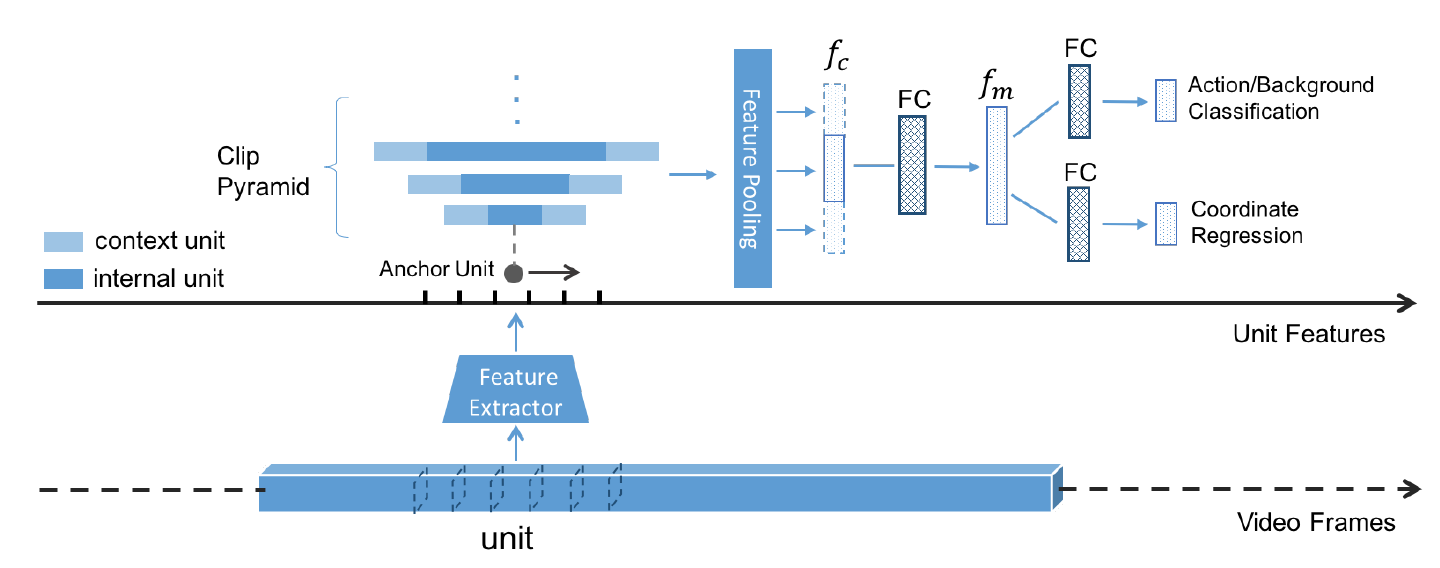
TURN TAP: Temporal Unit Regression Network for Temporal Action Proposals
这篇文章参考了faster rcnn的思想。候选框的生成不是在原始图像上,而是在特征图上,避免了特征的重复计算。同时把视频分割成多个unit,根据unit生成不同尺度的clip,然后对clip做分类(前景,背景二分类)和定位回归(采用了回归偏差的策略,类似于faster rcnn,且回归是unit-level不是frame-level),文章在THUMOS2014数据集IOU=0.5时的MAP为25.6%。