建表
CREATE TABLE `lock_test` (
`id` bigint(20) NOT NULL,
`value` varchar(255) NOT NULL,
PRIMARY KEY (`id`),
KEY `value_index` (`value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='锁测试表'
id主键, value 二级索引
next-key-lock
表中数据
| id |
value |
| 10 |
b |
| 20 |
f |
| 30 |
g |
| 40 |
j |
| 50 |
m |
| 60 |
p |
| 70 |
r |
| 80 |
y |
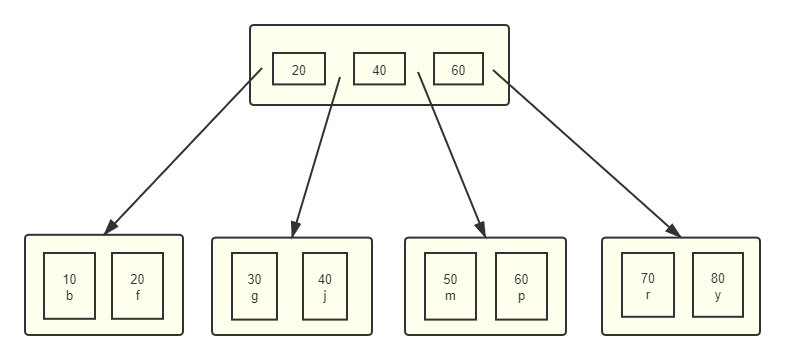
主键索引结构
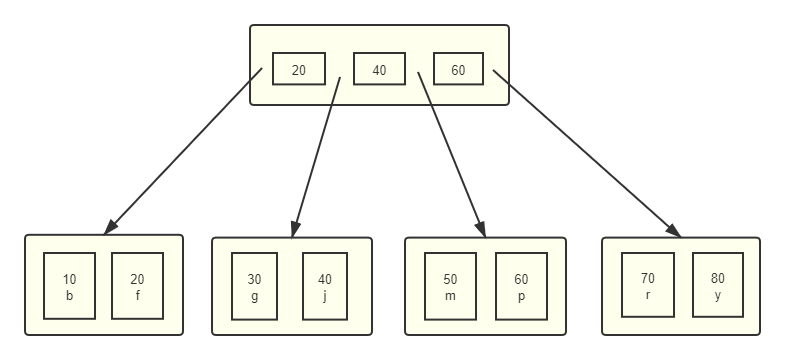
辅助索引结构
当前环境 where非聚集索引, 隔离级别RR
1. next-key-lock锁定范围测试
| TranscationA |
TranscationB |
| begin |
begin |
| select * from lock_test where value = 'j' for update |
|
|
insert into lock_test (id, value) VALUES (29, 'g') |
当前情况下事务A锁定的是(g,30)~(40, j) ~ (50,m)
从辅助索引结构来看是
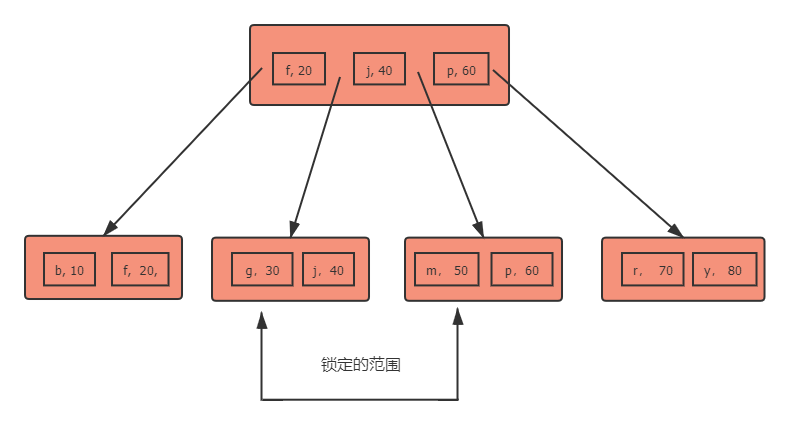
首先要理解辅助索引的排序规则,先按照索引字段排序,索引字段相同按照主键id排序, 因此从上面的insert来看可知(g, 29) 是插入到 (g, 30)前面,因此无需阻塞
对于下面事务
| TranscationA |
TranscationB |
| begin |
begin |
| select * from lock_test where value = 'j' for update |
|
|
insert into lock_test (id, value) VALUES (31, 'g') |
事务B会阻塞,因为根据辅助索引排序规则,(g, 31) 需要插入到锁定范围内,因此会阻塞
insert into lock_test (id, value) VALUES (49, 'm')
insert into lock_test (id, value) VALUES (51, 'm')
这两条哪个可以执行,哪条阻塞大家可以自己分析下
总结 :next-key-lock锁住的是前后的一个范围,根据索引 向前找到第一个存在的值,向后找第一个存在的值 这个区间范围进行锁定,具体锁定范围需要根据主键配合确定
当前环境 where主键索引, 隔离级别RR
2.主键聚集索引测试
| TranscationA |
TranscationB |
| begin |
begin |
| select * from lock_test where id = 40 for update |
|
|
insert into lock_test (id, value) VALUES (31, 'g') |
因为where条件是主键索引,不会重复,最多只能筛选出1条,因此只对id=40加一个行锁,非此行操作均不阻塞
| TranscationA |
TranscationB |
| begin |
begin |
|
insert into lock_test (id, value) VALUES (23, 'b') |
| select * from lock_test where value = 'b' for update |
|
|
commit |
| select * from lock_test where value = 'b' for update |
|
| select * from lock_test where value = 'b' |
|
| mvcc读无法读到 事务B的提交数据 |
|


