

基础知识
什么是进程和线程?
进程是应用程序的启动实例,进程拥有代码和打开的文件资源、数据资源、独立的内存空间。
线程从属于进程,是程序的实际执行者,一个进程至少包含一个主线程,也可以有更多的子线程,线程拥有自己的栈空间。
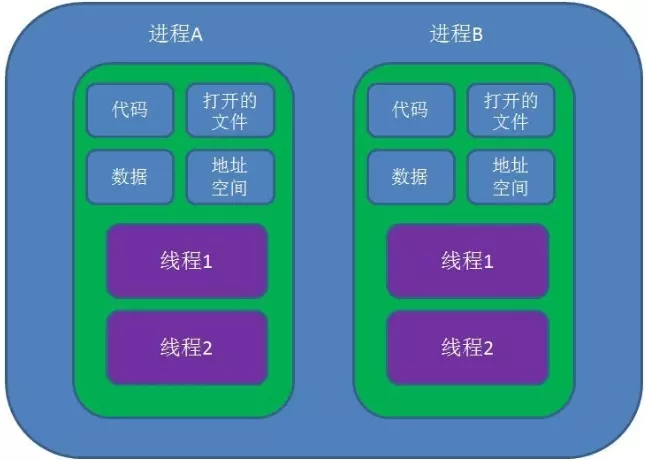
对操作系统而言,线程是最小的执行单元,进程是最小的资源管理单元。无论是进程还是线程,都是由操作系统所管理的。
线程的状态
线程具有五种状态:初始化、可运行、运行中、阻塞、销毁
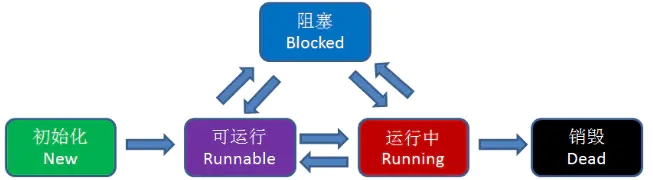
线程之间是如何进行协作的呢?
最经典的例子是生产者/消费者模式,即若干个生产者线程向队列中系欸如数据,若干个消费者线程从队列中消费数据。
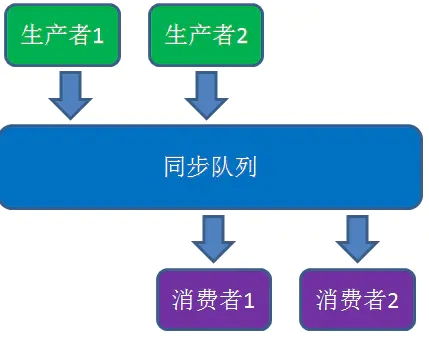
生产者/消费者模式的性能问题是什么?
涉及到同步锁 涉及到线程阻塞状态和可运行状态之间的切换 设置到线程上下文的切换
什么是协程呢?
协程(Coroutines)是一种比线程更加轻量级的存在,正如一个进程可以拥有多个线程一样,一个线程可以拥有多个协程。
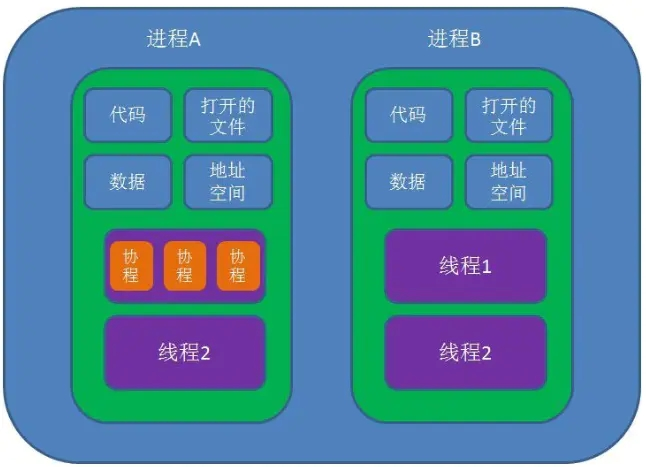
协程不是进程也不是线程,而是一个特殊的函数,这个函数可以在某个地方挂起,并且可以重新在挂起处外继续运行。所以说,协程与进程、线程相比并不是一个维度的概念。
一个进程可以包含多个线程,一个线程也可以包含多个协程。简单来说,一个线程内可以由多个这样的特殊函数在运行,但是有一点必须明确的是,一个线程的多个协程的运行是串行的。如果是多核CPU,多个进程或一个进程内的多个线程是可以并行运行的,但是一个线程内协程却绝对是串行的,无论CPU有多少个核。毕竟协程虽然是一个特殊的函数,但仍然是一个函数。一个线程内可以运行多个函数,但这些函数都是串行运行的。当一个协程运行时,其它协程必须挂起。
进程、线程、协程的对比
协程既不是进程也不是线程,协程仅仅是一个特殊的函数,协程它进程和进程不是一个维度的。 一个进程可以包含多个线程,一个线程可以包含多个协程。 一个线程内的多个协程虽然可以切换,但是多个协程是串行执行的,只能在一个线程内运行,没法利用CPU多核能力。 协程与进程一样,切换是存在上下文切换问题的。 上下文切换
进程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户是无感知的。进程的切换内容包括页全局目录、内核栈、硬件上下文,切换内容保存在内存中。进程切换过程是由“用户态到内核态到用户态”的方式,切换效率低。
线程的切换者是操作系统,切换时机是根据操作系统自己的切换策略,用户无感知。线程的切换内容包括内核栈和硬件上下文。线程切换内容保存在内核栈中。线程切换过程是由“用户态到内核态到用户态”, 切换效率中等。
协程的切换者是用户(编程者或应用程序),切换时机是用户自己的程序所决定的。协程的切换内容是硬件上下文,切换内存保存在用户自己的变量(用户栈或堆)中。协程的切换过程只有用户态,即没有陷入内核态,因此切换效率高。
协程的创建
导入相关依赖
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.1.1'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1'
- kotlin 协程 API
- 创建支持 kotlinx.coroutines 的项目
- 第一个协程程序
- launch 函数
- Job 对象
- runBlocking 函数
- 挂起函数
kotlin 协程 API
Kotlin 支持协程,并提供了丰富的协程编程所需的 API,主要是三个方面的支持: (1) 语言支持。kotlin 语言本身提供一些对协程的支持,例如 kotlin 中的 suspend 关键字可以声明一个挂起函数。 (2) 底层 API。kotlin 标准库中包含协程编程核心底层 API,来自于 kotlin. coroutines 包,这些底层 API 虽然也可以编写携程代码,但是使用起来非常麻烦,不推荐直接使用这些底层 API。 (3) 高级 API。高级 API 使用起来很简单,但 kotlin 标准库中没有高级 API,它来自于 kotlin 的扩展项目 kotlinx.coroutines 框架(github.com/Kotlin/kotl…),使用时需要额外配置项目依赖关系
创建支持 kotlinx.coroutines 的项目
kotlinx.coroutines 提供了协程开发的高级 API,使用起来比标准库中的底层 API 要简单得多。但使用 kotlinx.coroutines需要额外在项目中配置依赖关系。下面是在 build.gradle 文件中添加 kotlinx.coroutines 依赖关系的配置。
apply plugin: 'java-library'
apply plugin: 'kotlin'
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation "org.jetbrains.kotlin:kotlin-stdlib-jdk8:$kotlin_version"
implementation "org.jetbrains.kotlinx:kotlinx-coroutines-core:$kotlinx_coroutines" // 1️⃣
}
sourceCompatibility = "8"
targetCompatibility = "8"
buildscript {
ext.kotlin_version = '1.3.31' // 2️⃣
ext.kotlinx_coroutines = '1.3.0-M1'
repositories {
mavenCentral()
}
dependencies {
classpath "org.jetbrains.kotlin:kotlin-gradle-plugin:$kotlin_version"
}
}
repositories {
mavenCentral()
}
compileKotlin {
kotlinOptions {
jvmTarget = "1.8"
}
}
compileTestKotlin {
kotlinOptions {
jvmTarget = "1.8"
}
}
第一个协程程序
GlobalScope.launch {
for (i in 1..10) {
println("子协程执行第${i}次")
val sleepTime = (random() * 1000).toLong()
delay(sleepTime)
}
println("子协程执行结束")
}
sleep(10 * 1000)
println("主程序结束...")
打印结果:
子协程执行第1次
子协程执行第2次
子协程执行第3次
子协程执行第4次
子协程执行第5次
子协程执行第6次
子协程执行第7次
子协程执行第8次
子协程执行第9次
子协程执行第10次
子协程执行结束
主程序结束...
上述代码 GlobalScope.launch 函数创建并启动了一个协程,类似于线程的 thread 函数。代码 delay 函数是挂起协程,类似于线程的 sleep 函数,但不同的是 delay 函数不会阻塞线程,而 sleep 函数会阻塞线程。代码sleep让主线程休眠 10s。如果这里主线程不休眠,主线程就直接结束了,其他的线程或协程没有机会运行。
launch 函数
上面示例中的 GlobalScope.launch 函数是非常重要的,它的定义如下:
public fun CoroutineScope.launch(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> Unit
): Job {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyStandaloneCoroutine(newContext, block) else
StandaloneCoroutine(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
launch 是个扩展函数,接受3个参数,前面2个是常规参数,最后一个是个对象式函数,这样的话 kotlin 就可以使用以前说的闭包的写法:() 里面写常规参数,{} 里面写函数式对象的实现,就像上面的例子一样,刚从 java 转过来的朋友看着很别扭不是,得适应 GlobalScope.launch(Dispatchers.Unconfined) {...}
我们需要关心的是 launch 的3个参数和返回值 Job:
CoroutineContext - 可以理解为协程的上下文,在这里我们可以设置 CoroutineDispatcher 协程运行的线程调度器,有 4种线程模式:
Dispatchers.Default
Dispatchers.IO -
Dispatchers.Main - 主线程
Dispatchers.Unconfined - 没指定,就是在当前线程
不写的话就是 Dispatchers.Default
CoroutineStart - 启动模式,默认是DEAFAULT,也就是创建就启动;还有一个是LAZY,意思是等你需要它的时候,再调用启动 DEAFAULT - 模式模式,不写就是默认
ATOMIC -
UNDISPATCHED
LAZY - 懒加载模式,你需要它的时候,再调用启动,看这个例子
var job:Job = GlobalScope.launch( start = CoroutineStart.LAZY ){
Log.d("AA", "协程开始运行,时间: " + System.currentTimeMillis())
}
Thread.sleep( 1000L )
// 手动启动协程
job.start()
block - 闭包方法体,定义协程内需要执行的操作
Job - 协程构建函数的返回值,可以把 Job 看成协程对象本身,协程的操作方法都在 Job 身上了
job.start() - 启动协程,除了 lazy 模式,协程都不需要手动启动
job.join() - 等待协程执行完毕
job.cancel() - 取消一个协程
job.cancelAndJoin() - 等待协程执行完毕然后再取消
比如说当用户关闭页面时,后台请求尚未返回,但此时结果已经无关紧要了,我们可以通过Job.cancel() 函数来取消掉当前执行的协程任务。
再举个栗子?,如果我们将一些耗时任务放在子协程中处理,但是父协程需要用到子协程的结果,这时候我们该怎么办?这就是我们要介绍的 Job.join() 函数
fun testjob()= runBlocking {
var string = "4321"
val job = launch {
delay(3000)
string = "1234"
}
println(string)
job.join()
println(string)
}
返回
4321
1234
这是因为第一次执行打印时job还没有执行完毕,所以 string 的值为初始值,我们调用 join 将主协程挂起之后,主协程将会一直阻塞到 launch 内的代码执行完毕,再次打印就是重新赋值后的新值。
如果我们为 launch函数设置 CoroutineStart 参数 为 LAZY 时,join() 函数还起到启动子协程的作用。
Job 对象
- isActive 属性:判断 Job 是否处于获得状态。
- isCompleted 属性:判断 Job 是否处于完成状态。
- isCancelled 属性:判断 Job 是否处于取消状态。
- start 函数:开始 Job。
- cancel 函数:取消 Job。
- join 函数:使当前协程处于等待状态,直到 Job 完成,join 是一个挂起函数,只能在协程体或其他的挂起函数中调用。
val job = GlobalScope.launch {
for (i in 1..10) {
println("子协程执行第${i}次")
val sleepTime = (random() * 1000).toLong()
delay(sleepTime)
}
println("子协程执行结束")
}
println(job.isActive)
println(job.isCompleted)
sleep(10 * 1000)
println("主程序结束...")
println(job.isCompleted)
// 运行结果:
true
false
子协程执行第1次
子协程执行第2次
子协程执行第3次
子协程执行第4次
子协程执行第5次
子协程执行第6次
子协程执行第7次
子协程执行第8次
子协程执行第9次
子协程执行第10次
子协程执行结束
主程序结束...
true
以下是job 生命周期提前看下
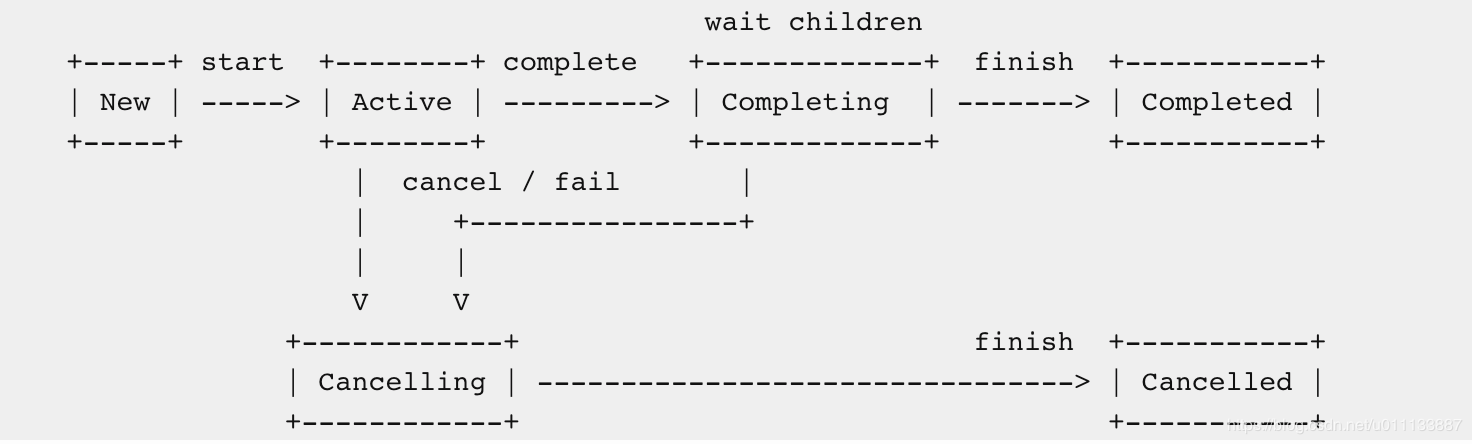
runBlocking 函数
前面的例子为了保持其他线程处于活动状态,示例中都使用了 sleep 函数。sleep 函数是线程提供的函数,最好不要在协程中使用,应该使用协程自己的 delay 函数,但 delay 是挂起函数,必须在协程体 或 其他的挂起函数中使用。
fun main(args: Array<String>?) = runBlocking {
GlobalScope.launch {
for (i in 1..10) {
println("子协程执行第${i}次")
val sleepTime = (random() * 1000).toLong()
delay(sleepTime)
}
println("子协程执行结束")
}
delay(10 * 1000) // 1️⃣
println("主程序结束...")
}
// 运行结果
子协程执行第1次
子协程执行第2次
子协程执行第3次
子协程执行第4次
子协程执行第5次
子协程执行第6次
子协程执行第7次
子协程执行第8次
子协程执行第9次
子协程执行第10次
子协程执行结束
主程序结束...
挂起函数
suspend fun 函数名(参数列表): 返回类型 {
// 函数体
}
注意:挂起函数只能在协程体中 或 其他的挂起函数中调用,不能在普通函数中调用。
挂起函数不仅可以是顶层函数,还可以是成员函数和抽象函数,子类重写挂起函数后还应该是挂起的。
abstract class SuperClass {
suspend abstract fun run()
}
class SubClass: SuperClass() {
override suspend fun run() { }
}
上述代码 SubClass 类实现了抽象类 SuperClass 的抽象挂起函数 run,重写后它还是挂起函数。
fun main(args: Array<String>?) = runBlocking {
GlobalScope.launch {
run("job1")
}
GlobalScope.launch {
run("job2")
}
delay(10 * 1000)
println("主程序结束...")
}
suspend fun run(name:String) {
for (i in 1..10) {
println("子协程 ${name} 执行第${i}次")
val sleepTime = (random() * 1000).toLong()
delay(sleepTime)
}
println("子协程 ${name} 执行结束")
}
// 运行结果
子协程 job1 执行第1次
子协程 job2 执行第1次
子协程 job1 执行第2次
子协程 job1 执行第3次
子协程 job1 执行第4次
子协程 job2 执行第2次
子协程 job2 执行第3次
子协程 job1 执行第5次
子协程 job1 执行第6次
子协程 job1 执行第7次
子协程 job2 执行第4次
子协程 job2 执行第5次
子协程 job2 执行第6次
子协程 job1 执行第8次
子协程 job1 执行第9次
子协程 job2 执行第7次
子协程 job2 执行第8次
子协程 job1 执行第10次
子协程 job1 执行结束
子协程 job2 执行第9次
子协程 job2 执行第10次
子协程 job2 执行结束
主程序结束...
注意!!,runBlocking和coroutineScope除了有本质的区别外,最大的不同就在于两者所在的协程被挂起后对所在线程的影响,runBlocking所在协程被挂起后会阻塞所在线程,线程不能处理协程之外的事情;coroutineScope所在的协程被挂起后,则会立即交出控制权给所在的线程,不会阻塞线程,线程可以处理协程之外的事情。
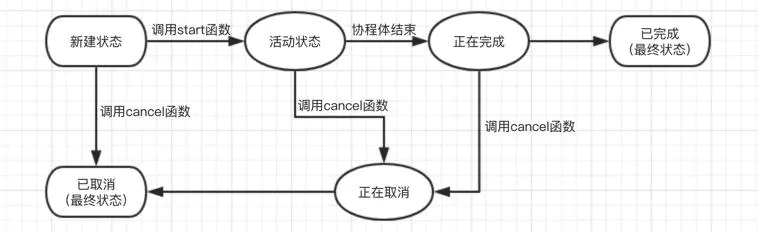
协程的生命周期
协程的声明周期是通过 Job 的几种状态体现的,Job协程有 6 种状态:
- 新建状态: 新建状态主要是通过 launch 函数创建协程对象,它仅仅是一个空的协程对象。
- 活动状态 : 新建协程调用 start 函数后,它就进入活动状态。launch 函数通过 start 参数判断是否启动协程。处于活动状态的协程会执行协程体。
- 正在完成状态 : 正在完成状态是一个瞬间过渡状态,从活动状态进入到已完成状态时经历的中间状态。
- 已完成状态 : 协程成功执行完协程体,就会进入已完成状态,这是最终状态,说明这个协程已经停止。
- 正在取消状态: 在活动状态或正在完成状态时,如果调用了 cancel 函数则会进入已取消状态,在此之前要先进入正在取消状态,正在取消状态也是一个瞬间过渡状态。
- 已取消状态
在新建状态、活动状态或正在完成状态时,如果调用 cancel 函数最终都会是已取消状态,只是新建状态没有经历正在取消状态,而直接是已取消状态。已取消状态是最终状态,使用这个协程已经停止。
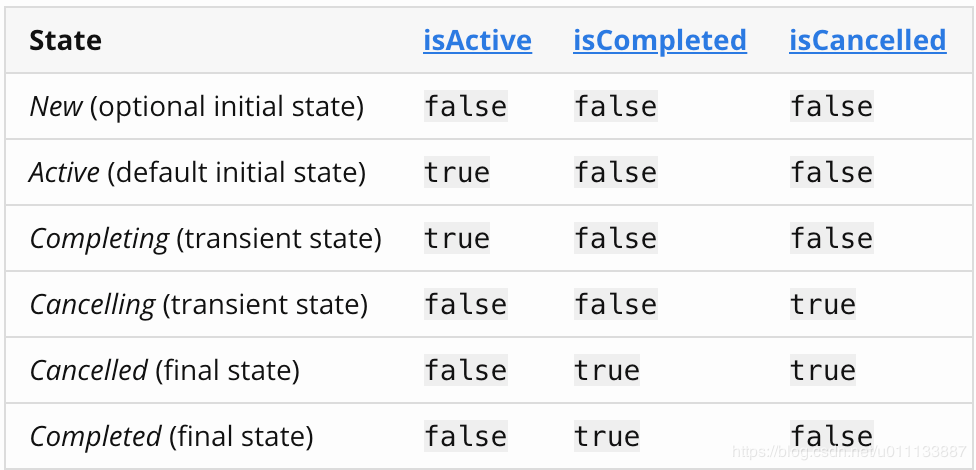
Job 状态可以通过 Job 的 isActive、isCompleted 和 isCancelled 属性判断而知,具体说明如下:
| 状态 | isActive | isCompleted | isCancelled |
|---|---|---|---|
| 新建状态 | false | false | false |
| 活动状态 | true | false | false |
| 正在完成状态 | true | false | false |
| 正在取消状态 | false | false | true |
| 已取消状态 | false | true | true |
| 正在取消状态 | false | true | false |
使用async和await实现协程高效并发
- 不使用async demo
- 使用async
- async 和await 简单分析
不使用async demo
private suspend fun intValue1(): Int {
delay(1000)
return 1
}
private suspend fun intValue2(): Int {
delay(2000)
return 2
}
fun main() = runBlocking {
val elapsedTime = measureTimeMillis {
val value1 = intValue1()
val value2 = intValue2()
println("the result is ${value1 + value2}")
}
println("the elapsedTime is $elapsedTime")
}
the result is 3
the elapsedTime is 3018
这个例子想要说明什么问题呢?要想实现功能A,需要依赖于功能B和功能C的结果,如果功能B和功能C之间又有依赖关系,那么只能B和C顺序执行;但是如果B和C是完全独立的,那么B和C就可以同时进行,从而缩短实现功能A所需时间。就好像本例中的intValue1()和intValue2(),它们是完全独立的,但是从运行结果来看,耗费的时间是intValue1()的时间 + intValue2()的时间。那么怎么实现协程的高效并发呢?
使用async demo
fun main() = runBlocking {
val elapsedTime = measureTimeMillis {
val value1 = async { intValue1() }
val value2 = async { intValue2() }
println("the result is ${value1.await() + value2.await()}")
}
println("the elapsedTime is $elapsedTime")
}
private suspend fun intValue1(): Int {
delay(1000)
return 1
}
private suspend fun intValue2(): Int {
delay(2000)
return 2
}
the result is 3
the elapsedTime is 2038
从结果上看,所耗时间变短了,执行效率也就提高了。
async 和await 简单分析
public fun <T> CoroutineScope.async(
context: CoroutineContext = EmptyCoroutineContext,
start: CoroutineStart = CoroutineStart.DEFAULT,
block: suspend CoroutineScope.() -> T
): Deferred<T> {
val newContext = newCoroutineContext(context)
val coroutine = if (start.isLazy)
LazyDeferredCoroutine(newContext, block) else
DeferredCoroutine<T>(newContext, active = true)
coroutine.start(start, coroutine, block)
return coroutine
}
通过aysnc的方法签名以及它的文档注释,我们可以得知:
它和CoroutineScope.launch{}类似,可以用来创建一个协程,不同的是launch的返回结果是Job类型,而aysnc的返回结果是Deferred类型 结果Deferred和Job一样,也能够被取消。 至此,我们创建协程的方式就有了五种:
GlobalScope.launch{}
launch{} //内部创建子协程
runBlocking{} //该协程直接回阻塞 主线程
coroutineScope{}
async{}
那么Deferred到底是个什么东东?它和Job之间又有怎样的联系和区别?
public interface Deferred<out T> : Job
Deferred value is a non-blocking cancellable future — it is a [Job] with a result
从类的层次结构上看,Deferred是Job的子接口;从功能上来看,Deferred就是带返回结果的Job。
await: Deferred接口定义的方法
Awaits for completion of this value without blocking a thread and resumes when deferred computation is complete,returning the resulting value or throwing the corresponding exception if the deferred was cancelled
不会阻塞当前线程
会等待,当计算完毕时,恢复执行
会返回结果值或者由于被取消而对应的异常
CoroutineScope.async()中的start参数:默认值为CoroutineStart.DEFAULT
public enum class CoroutineStart {
DEFAULT,
LAZY,
ATOMIC,
UNDISPATCHED
}
DEFAULT: 默认值,它会上下文立即调度线程的执行
LAZY:它不会立即调度协程的执行,而是在需要的时候才会触发执行
ATOMIC:原子性调度,即不会被取消
UNDISPATCHED:也会立即调度,直到当前的第一个挂起点,这个后面讨论分发器的时候还会说
这个参数在launch里面也有,表达的含义是一致的。
总结: launch 与 async 这两个函数大同小异,都是用来在一个 CoroutineScope 内开启新的子协程的。不同点从函数名也能看出来,launch 更多是用来发起一个无需结果的耗时任务(如批量文件删除、创建),这个工作不需要返回结果。async 函数则是更进一步,用于异步执行耗时任务,并且需要返回值(如网络请求、数据库读写、文件读写),在执行完毕通过 await() 函数获取返回值。
如何选择这两个函数就看我们自己的需求啦,比如只是需要切换协程执行耗时任务,就用 launch 函数。如果想把原来的回调式的异步任务用协程的方式实现,就用 async 函数
retrofit 结合协程
- 添加依赖
添加依赖
implementation 'com.squareup.retrofit2:retrofit:2.7.1' // 必须2.6以上不然不兼容协程
implementation 'com.squareup.retrofit2:converter-gson:2.7.1'
implementation 'androidx.lifecycle:lifecycle-extensions:2.2.0'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-core:1.1.1'
implementation 'org.jetbrains.kotlinx:kotlinx-coroutines-android:1.1.1'
implementation 'androidx.lifecycle:lifecycle-viewmodel-ktx:2.2.0'
