

最近公司项目用了分库分表,用了ShardingSphere组件,为了在碰到问题的时候去解决,那么对这个组件需要有个大概的认识,也是这个专题的由来。
ss version:4.1.0 版本
按照官网文档描述,核心由SQL解析 => 执行器优化 => SQL路由 => SQL改写 => SQL执行 => 结果归并的流程组成,那我们看源码也就是按照这个顺序来展开,我也是边摸索边看,会记录我看代码的过程
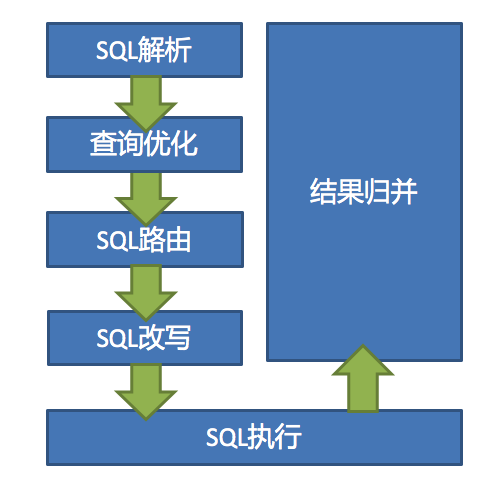
SQL解析 & 路由
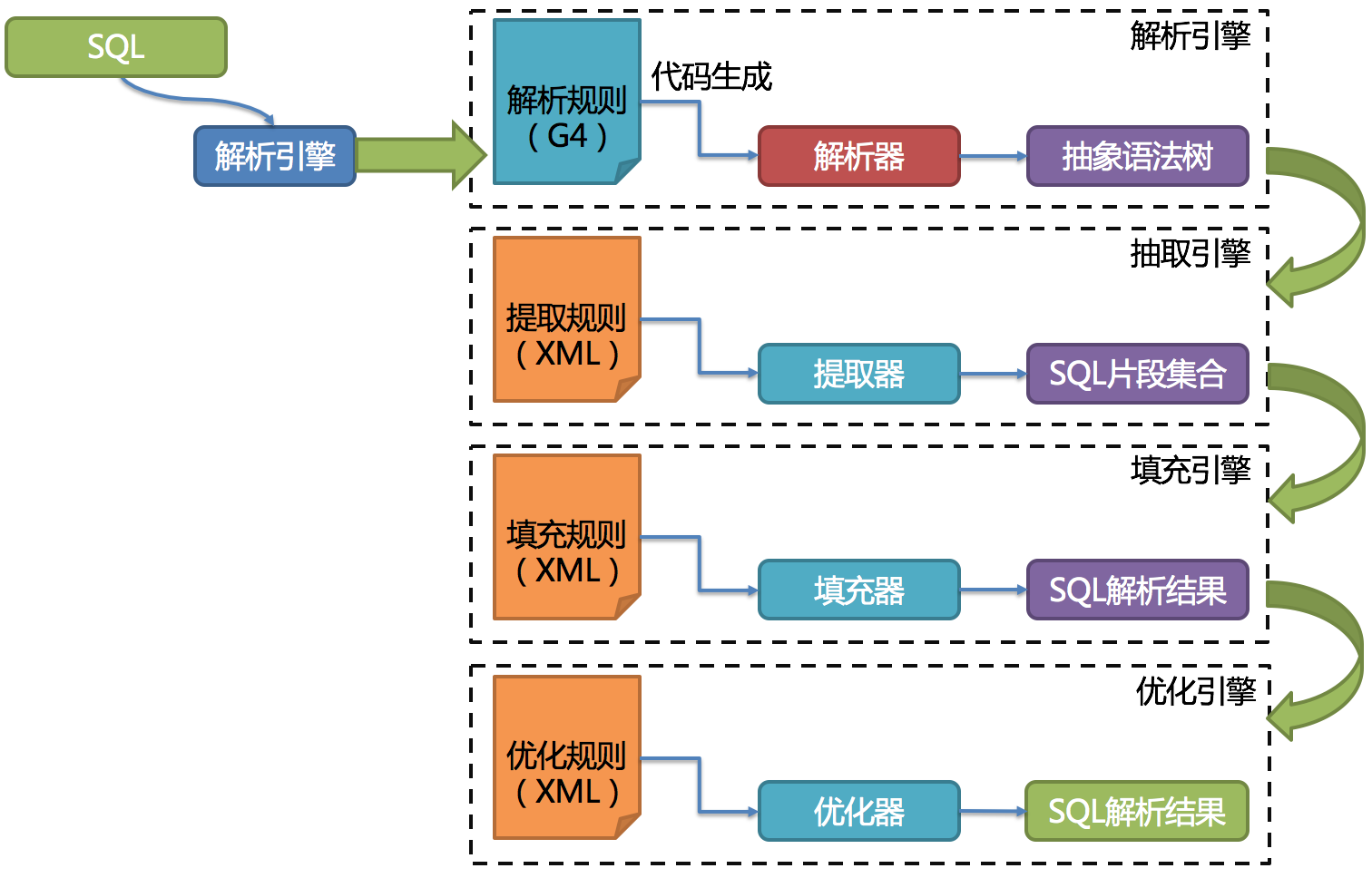
从官网上拷贝的一张图片,我觉得现阶段我们可以不去了解ss怎么去使用ANTLR来解析优化sql,但是官网上的一句话需要注意,“经过实例测试,ANTLR解析SQL的性能比自研的SQL解析引擎慢3-10倍左右。为了弥补这一差距,ShardingSphere将使用PreparedStatement的SQL解析的语法树放入缓存。 因此建议采用PreparedStatement这种SQL预编译的方式提升性能”,这点我们需要关注,在实际使用过程中,这里曾经是一个坑。
我们先找到一个关键的类 ShardingPreparedStatement,他实现了PreparedStatement接口,看下execute()方法,标准的JDBC步骤,也许这里就是我们分析代码的入口,再看下这个类的属性有BasePrepareEngine,PreparedStatementExecutor,ResultSet,更加确信了我们的猜测
@Override
public boolean execute() throws SQLException {
try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}
1.先进prepare()方法,进prepareEngine#prepare,BasePrepareEngine是一个抽象类,此时的实现类是PreparedQueryPrepareEngine
private void prepare() {
executionContext = prepareEngine.prepare(sql, getParameters());
...
}
2.进了prepare方法之后,我们看到了executeRoute方法,好像是我们需要关注的,registerRouteDecorator方法看起来也不知道是干嘛的,先跳过,先看route()方法,这个route是一个抽象方法
private RouteContext executeRoute(final String sql, final List<Object> clonedParameters) {
registerRouteDecorator();
return route(router, sql, clonedParameters);
}
3.进入PreparedQueryPrepareEngine#route方法,继续进入DataNodeRouter#route,先不考虑dataNodeRouter是怎么来的
protected RouteContext route(final DataNodeRouter dataNodeRouter, final String sql, final List<Object> parameters) {
return dataNodeRouter.route(sql, parameters, true);
}
4.到这里,我们看到了很重要的一点提示,hook方法,代表了routing逻辑的开始,文档上不是说先解析sql的么,关于hook后面单独写一篇文章探讨一下sharding的hook和openTrancing以及sharding监控,继续进入DataNodeRouter#executeRoute方法
public RouteContext route(final String sql, final List<Object> parameters, final boolean useCache) {
routingHook.start(sql);
try {
RouteContext result = executeRoute(sql, parameters, useCache);
routingHook.finishSuccess(result, metaData.getSchema());
...
}
5.进入到DataNodeRouter#createRouteContext,这里看到parse方法,所以parse是包含在整个路由方法里面的,
private RouteContext createRouteContext(final String sql, final List<Object> parameters, final boolean useCache) {
SQLStatement sqlStatement = parserEngine.parse(sql, useCache);
...
}
6.进入到SQLParserEngine#parse方法里面,这里有一个spihook,说明这里的hook是可以提供扩展的
public SQLStatement parse(final String sql, final boolean useCache) {
ParsingHook parsingHook = new SPIParsingHook();
parsingHook.start(sql);
try {
SQLStatement result = parse0(sql, useCache);
...
}
7.进入到parse0方法后,看到了这里用到了缓存,还记得文档上有写过parse很慢,所以用了缓存,
private SQLStatement parse0(final String sql, final boolean useCache) {
if (useCache) {
Optional<SQLStatement> cachedSQLStatement = cache.getSQLStatement(sql);
if (cachedSQLStatement.isPresent()) {
return cachedSQLStatement.get();
}
}
ParseTree parseTree = new SQLParserExecutor(databaseTypeName, sql).execute().getRootNode();
...
}
这里我们不继续深入看怎么做的解析,但是到这里我们知道了2点重要的点
- pase可以扩展hook,至于怎么扩展,我打算放在最后的监控部分去探讨
- parse比较慢,做了缓存
8.回到DataNodeRouter#executeRoute方法中,parse完成后我们得到了RouteContext结果,接下来的decorators对象是哪里来的,其实是在BasePrepareEngine#executeRoute中的registerRouteDecorator()方法,最终把ShardingRouteDecorator和MasterSlaveRouteDecorator注册到DataNodeRouter的decorators属性中,从名字上可以看出来这是为了路由做准备,做一了层装饰器,封装了路由的上下文信息
private RouteContext executeRoute(final String sql, final List<Object> parameters, final boolean useCache) {
RouteContext result = createRouteContext(sql, parameters, useCache);
for (Entry<BaseRule, RouteDecorator> entry : decorators.entrySet()) {
result = entry.getValue().decorate(result, metaData, entry.getKey(), properties);
}
return result;
}
9.进入ShardingRouteDecorator#decorate方法,初始化ShardingRouteEngine
public RouteContext decorate(final RouteContext routeContext, final ShardingSphereMetaData metaData, final ShardingRule shardingRule, final ConfigurationProperties properties) {
...
ShardingRouteEngine shardingRouteEngine = ShardingRouteEngineFactory.newInstance(shardingRule, metaData, sqlStatementContext, shardingConditions, properties);
RouteResult routeResult = shardingRouteEngine.route(shardingRule);
...
}
10.我们先看标准的ShardingStandardRoutingEngine,属性如下
public final class ShardingStandardRoutingEngine implements ShardingRouteEngine {
//逻辑表名
private final String logicTableName;
//SQL解析之后的上下文信息
private final SQLStatementContext sqlStatementContext;
//分片条件
private final ShardingConditions shardingConditions;
private final ConfigurationProperties properties;
//datasoure和table信息
private final Collection<Collection<DataNode>> originalDataNodes = new LinkedList<>();
11.进入ShardingStandardRoutingEngine#route方法,shardingRule.getTableRule方法是通过逻辑表名去获取路由规则,路由规则就是我们通过配置文件配置的规则,然后进入getDataNodes,这个方法是通过我们的配置的路由规则来确定Collection,DataNode里面存放着dataSourceName和tableName,最终在HintShardingStrategy#doSharding方法中调用了shardingAlgorithm.doSharding,也就是我们实现的分片算法,(这里用的是强制分片算法),
@Override
public RouteResult route(final ShardingRule shardingRule) {
...
return generateRouteResult(getDataNodes(shardingRule, shardingRule.getTableRule(logicTableName)));
}
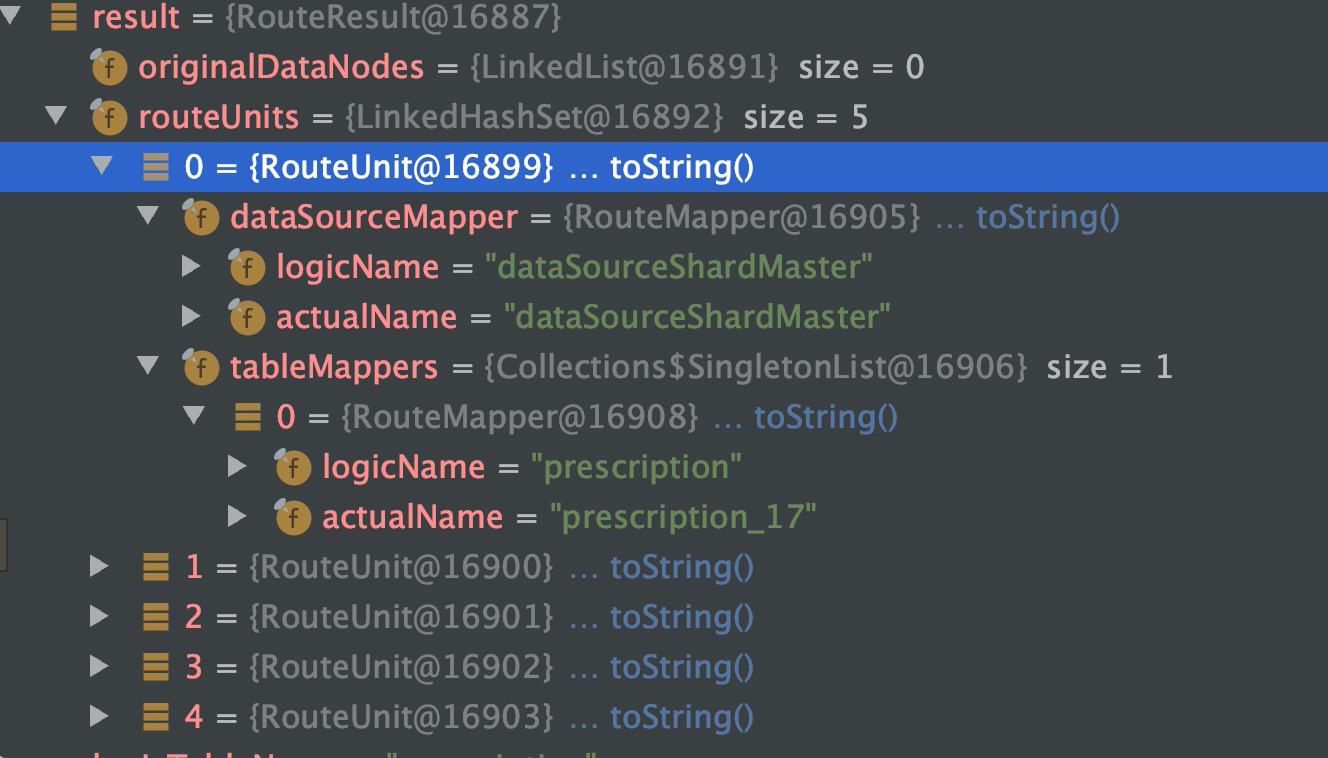
- 最终通过generateRouteResult方法组装得到RouteResult,下图可以看到routeUnit的属性,主要是datasource和table的属性,最终会把RouteResult封装到RouteContext中
public RouteContext route(final String sql, final List<Object> parameters, final boolean useCache) {
routingHook.start(sql);
try {
RouteContext result = executeRoute(sql, parameters, useCache);
routingHook.finishSuccess(result, metaData.getSchema());
return result;
// CHECKSTYLE:OFF
} catch (final Exception ex) {
// CHECKSTYLE:ON
routingHook.finishFailure(ex);
throw ex;
}
}
总结一下,routing 包含了parse,自定义分片策略执行和sql优化,sql优化这里没有体现,回头补上
