

Echarts
数据可视化
数据可视化的概念
借助图形化的数段,清晰有效的传递和沟通信息,以视觉的方式展现数据,便于用户的认知,偏于图表的样式,相对于文字说明更加直观
图表分类:饼图,柱状图,折线图,气泡图,面积图,地图等
什么是数据可视化
- 科学可视化(出现最早,最成熟)
处理科学数据,面向科学和工程数据方面,研究带有空间坐标和几何信息的三维空间,如何呈现数据中的几何特征 主要面向自然科技中产生数据的建模操作和处理 应用于医疗(透析,CT),科研,航天,天气,生物等技术
- 信息可视化(更常见,接触更多)
科学可视化演变而来,主要处理非结构化,非几何的数据 金融交易,社交网络,文本数据展示 减少视觉混淆对有用数据的干扰,把无用的数据过滤掉,而非简单信息的堆叠(数据加工,提取可用信息) 更倾向于展示信息
- 可视化分析(前两者的结合)
分析数据导向进行展示,需要了解具体的事物逻辑
7个经典的可视化案例
图表是一种美观而强大的工具,可以帮助我们探索和诠释这个世界。数百年来,人们一直在使用图表来解释跟数据相关的种种。
◆◆ ◆
1. 俄法战争
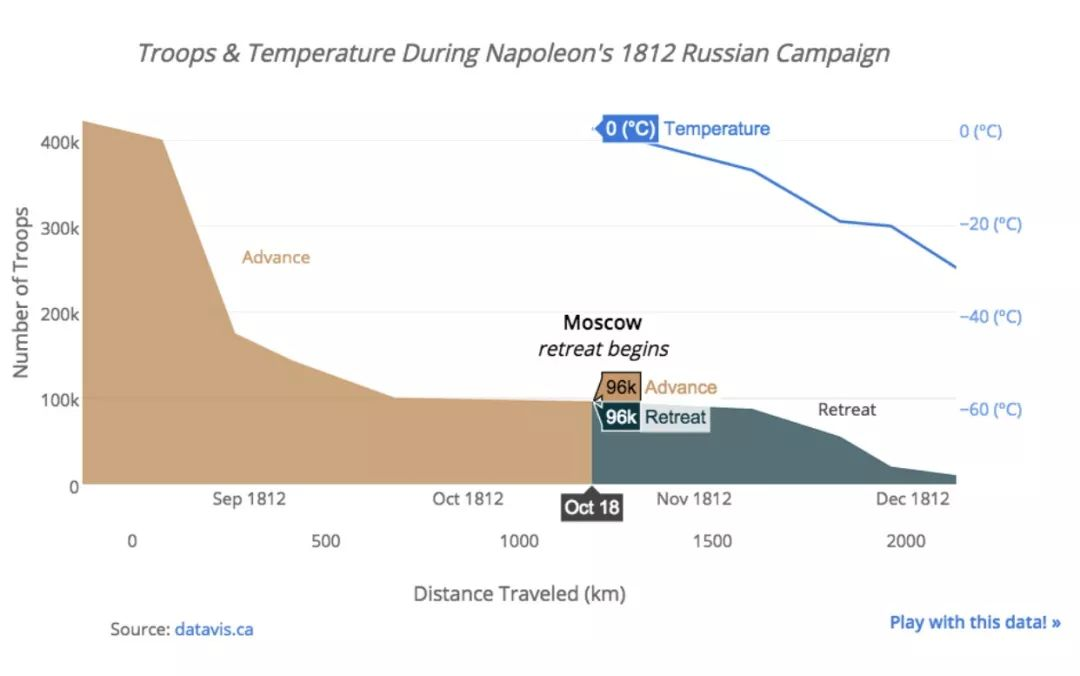
◆◆ ◆
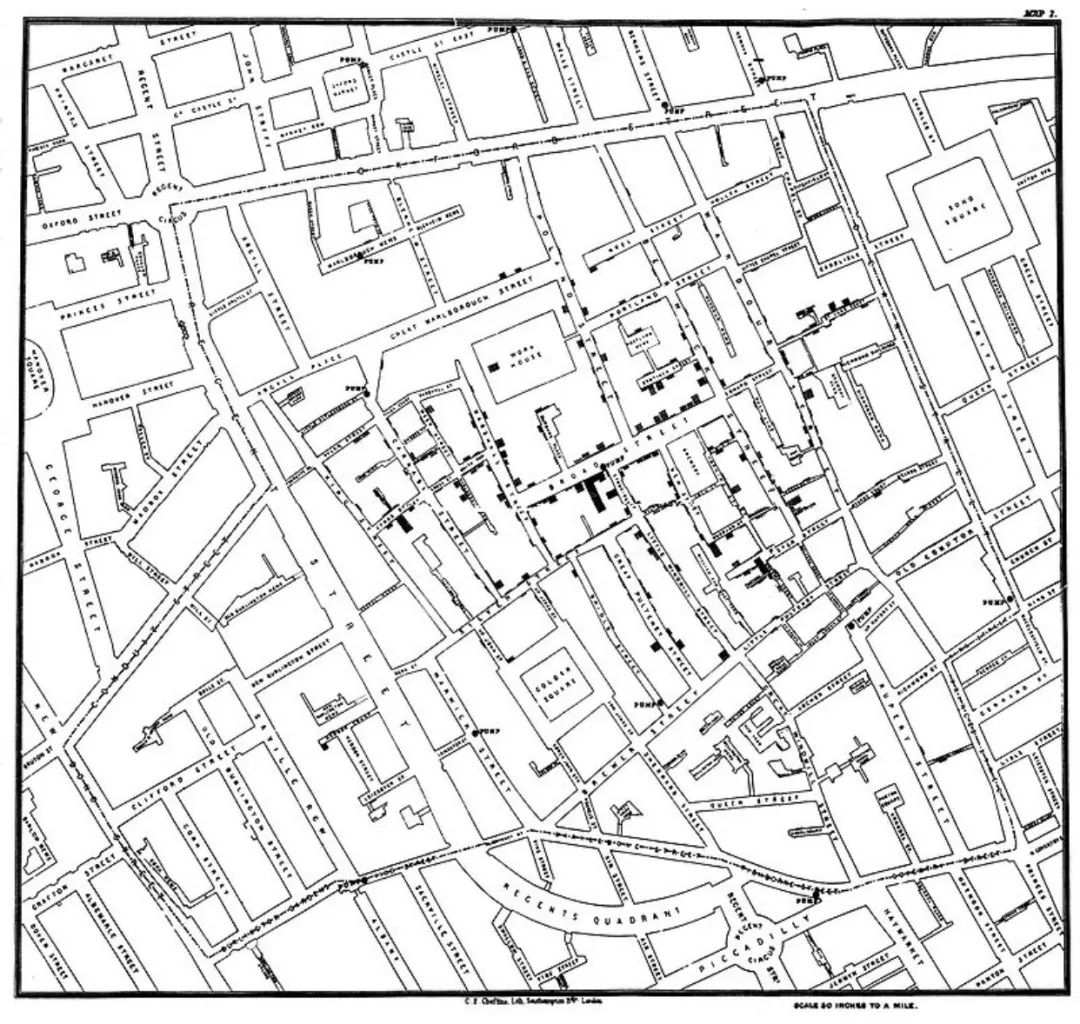
2. 约翰·雪诺(John Snow)和霍乱案例
下方是约翰·雪诺的地图,展示了1854年伦敦霍乱爆发时的发病源头。线条代表街道。黑色的长条代表了所在街区死亡的人数。圆点代表抽水泵。特别注意在宽街 (Broad Street)上的抽水泵周围的死亡人数相对集中。
雪诺用他的这幅地图佐证了他极富争议的理论:霍乱是由被污染的引用水传播开来的。当政府关闭了宽街上的水泵,霍乱的蔓延也平息了。引发霍乱的病菌最终由德国物理学家罗伯特·科赫(Robert Koch)在1883年分离出来。
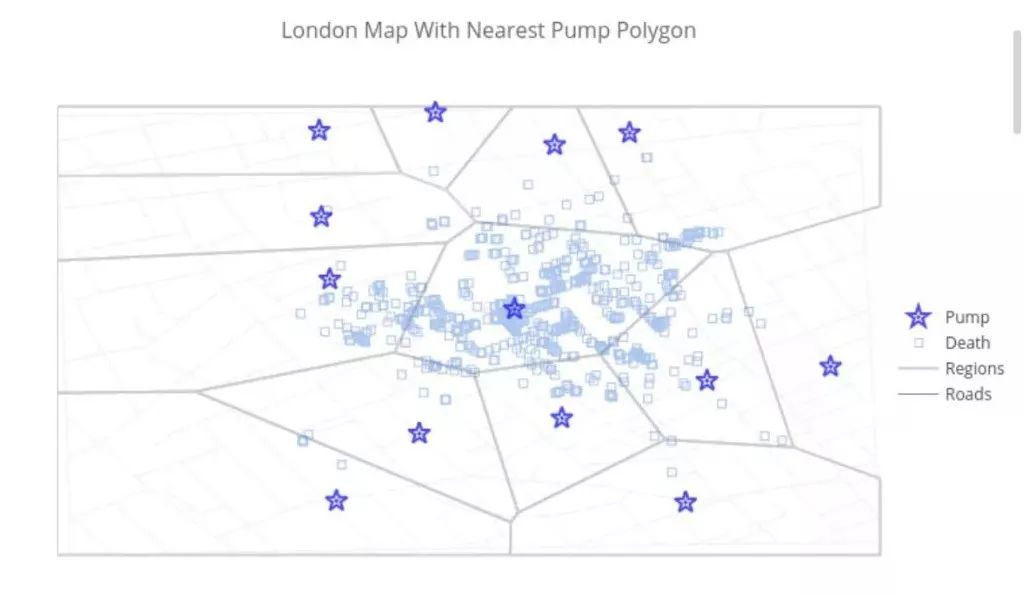
我们重制了这张图表,用蓝色半透明方块来表示死亡人数。沿着灰色街道的深色块表示多人死亡。星形表示抽水泵。图中的多边形展现了基于抽水泵区域而分布的死亡人群分布:即最近的打水区域。最右侧的区域超出了地图绘制的范围。如果你将鼠标放在某个抽水泵图标上,你就可以看到这个区域内的死亡人数。放大图像则可以展开某一个群组看到详细数据。
◆◆ ◆
3. 死亡原因及坐标
弗洛伦斯·南丁格尔(Florence Nightingale)是一位著名的英国社会改革者和统计学家。她是皇家统计学会的第一位女性成员,是使用极坐标图的先驱。当向国会展示她的研究成果时,南丁格尔使用区块来解释克里米亚战争。她的区块显示了在1854到1856年间克里米亚战争中人们死亡的原因。
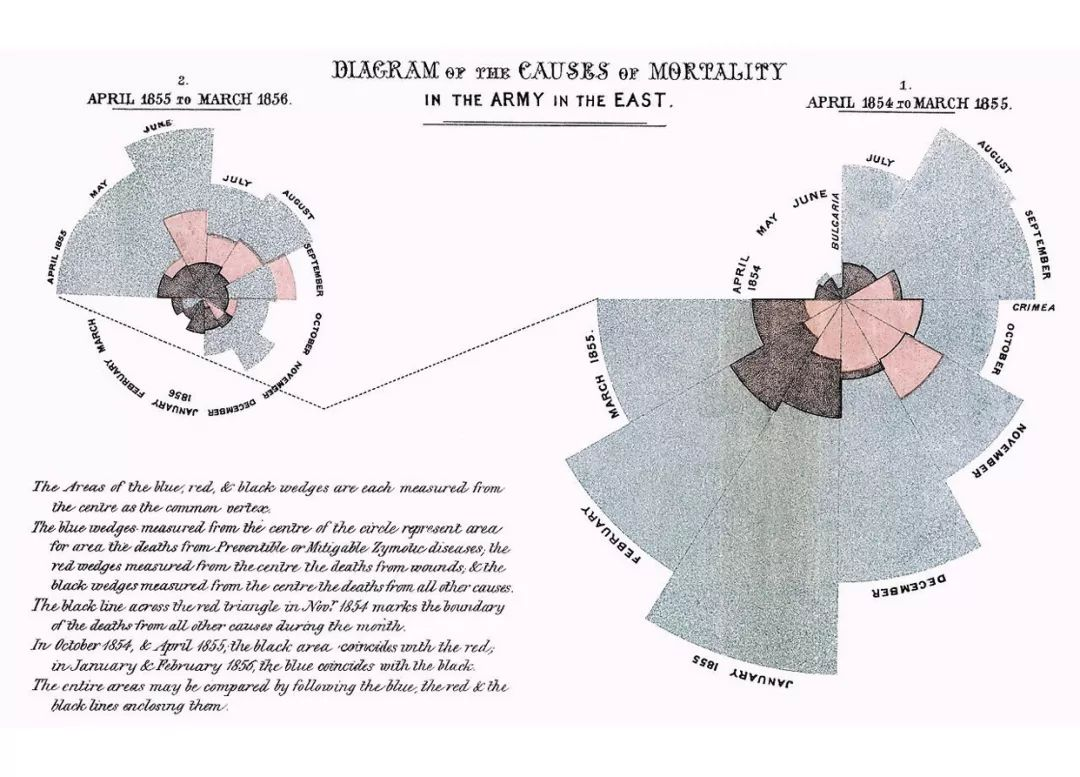
◆◆ ◆
4. 地球
地图应该是最早形式的图表。下面的地图分别由马丁·瓦尔德泽米勒(Martin Waldseemüller)在1507年,亚伯拉罕·奥特柳斯(Abraham Ortelius)在1570年和伊曼纽尔-鲍文(EmanuelBowen)在1744年制作完成的。

◆◆ ◆
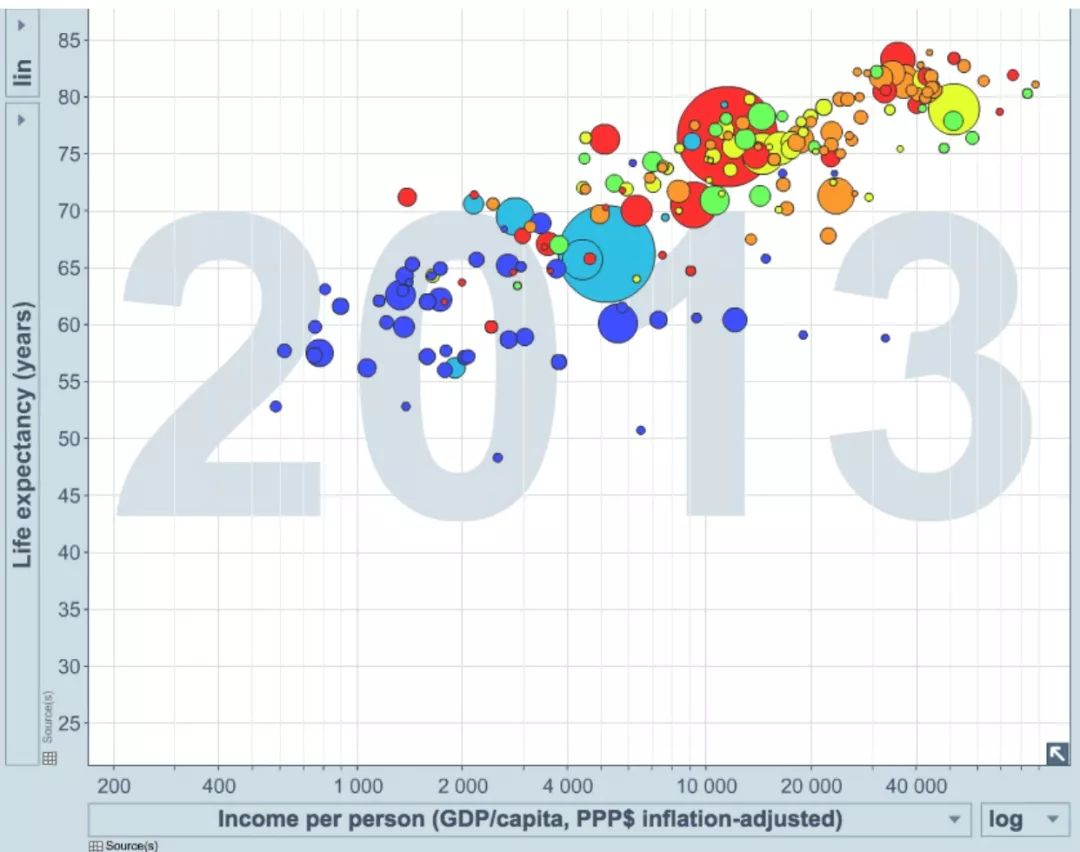
5. 汉斯·罗斯林(HansRosling)
汉斯•罗斯林是Gapminder(注:一个在线互动图表数据平台)的创办人之一,他制作了气泡图来展示每个国家四个维度的变量指标:平均寿命(y轴),GDP(x轴),七大洲(颜色)和人口数量(气泡大小)。
◆◆ ◆
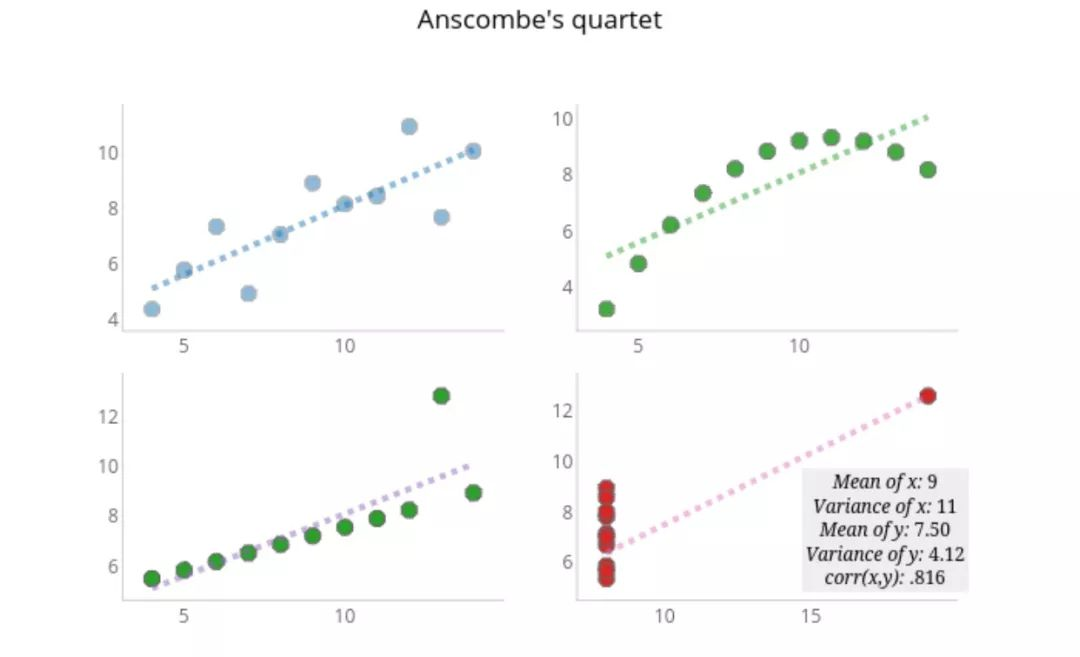
**6. Anscombe四图:**为什么要制作图表
Anscombe四图展示了弗朗西斯·安斯库姆(Francis Anscombe)在1973年构造的四组数据集。数据集具有相同的线性回归参数,x、y均值,x、y方差和Pearson相关系数(精确到两位小数)。《Nature》中的一篇文章重新发布了该数据集并绘制成如下图表。
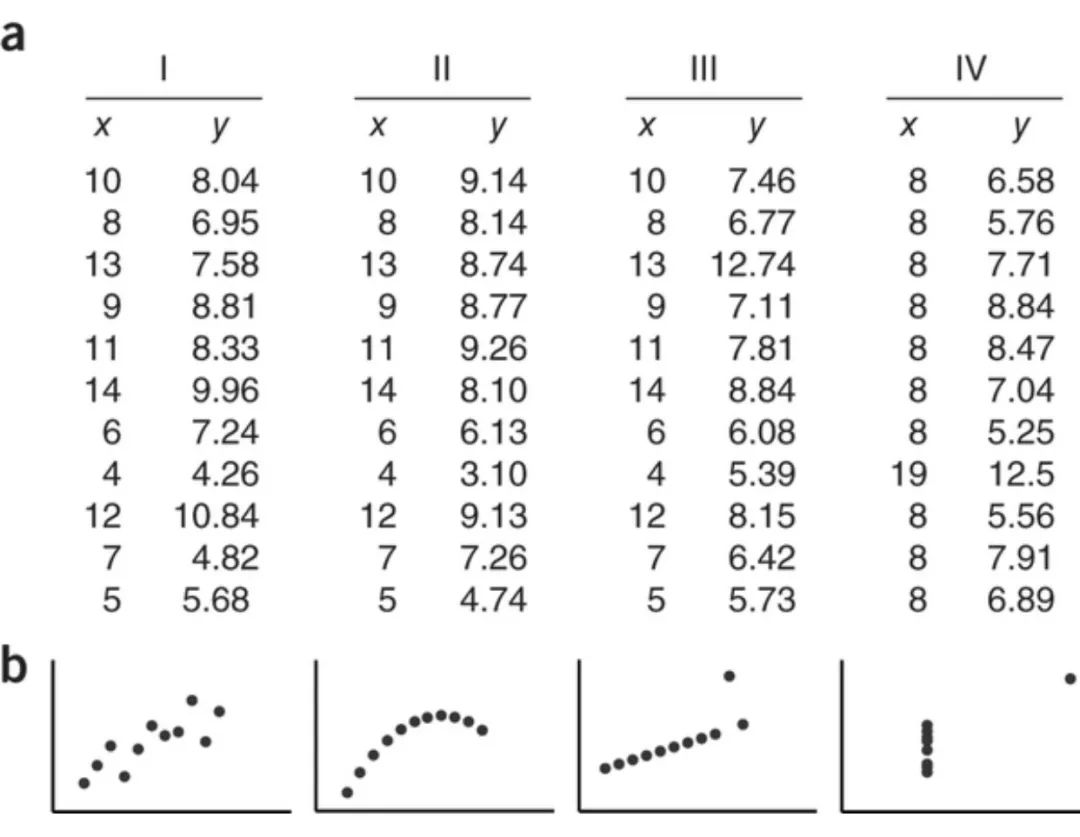
关键点是:**仅仅只有统计数据会变得混淆杂乱和不完整。**图表能让我们更好的理解数据。
◆◆ ◆
7. 进口量&出口量折线图
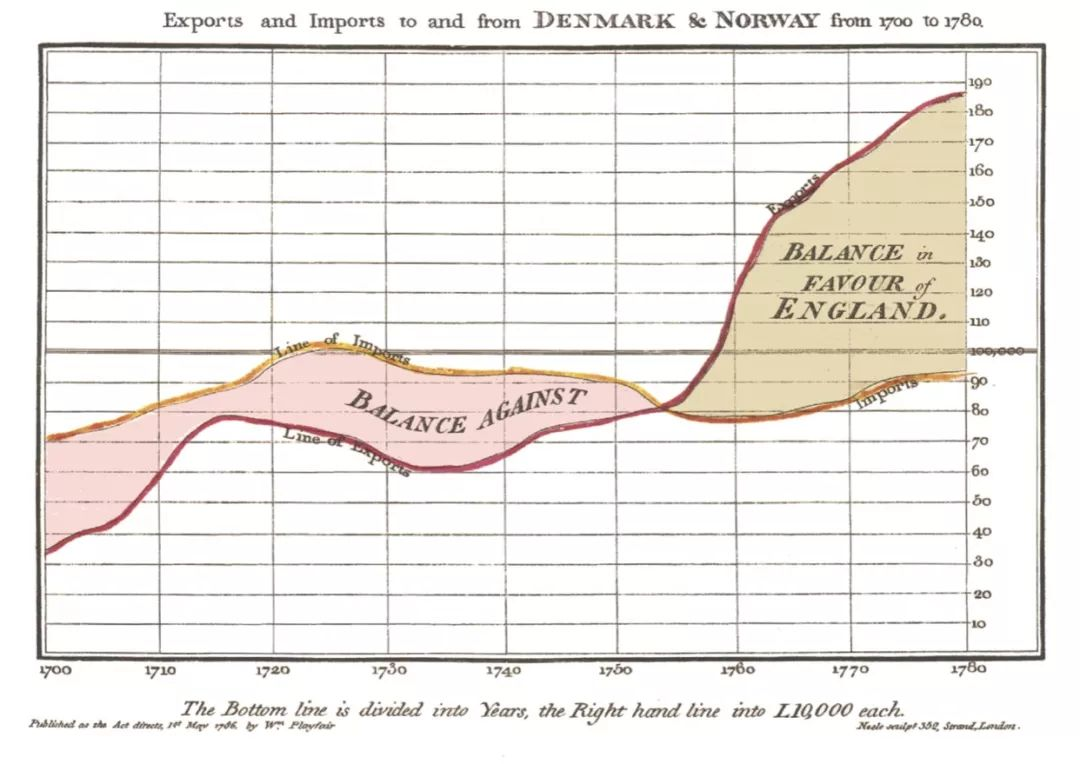
⼤数据可视化的价值
1、把庞杂的大数据直观的展现到决策的面前,才能更加节省时间,使工作变得更加高效;
2、利用数据更好的分析用户,针对性的为用户提供服务,增加数据背后与用户的互动性;
3、在数据爆炸增长时代,只有很好的把握时效,才能更好敏锐的掌握机遇。

数据可视化工具、书籍、案例
工具
1、FineBI
前是国内市场占有率第一的自助式BI工具,也是一款成熟的数据分析产品。内置丰富图表,不需要代码调用,可直接拖拽生成。可用于业务数据的快速分析,制作dashboard,也可构建可视化驾驶舱。
有别于Tableau的是,它更倾向于企业应用,从内置的ETL功能以及数据处理方式上看出,侧重业务数据的快速分析以及可视化展现。可与大数据平台,各类多维数据库结合,所以在企业级BI应用上广泛,个人使用免费。
2、Tableau
几乎是数据分析师人人会提的数据可视化驾驶舱工具,内置常用的分析图表,和一些数据分析模型,可以快速的探索式数据分析,制作数据分析报告。因为是商业智能,解决的问题更偏向商业分析,用Tableau可以快速地做出动态交互图,并且图表和配色也非常拿得出手。
3、PowerBI
微软继Excel之后推出的BI产品,可以和Excel无缝连接使用,创建个性化的数据看板。擅长数据可视化,采用的CS架构,主要的报表连接过程使用的客户端,浏览器端可以进行简单的报表编辑。
其连接数据源需要单独下载msi驱动,而不是目前主流的JDBC的连接方式。操作基本都是拖拽,不过其探索式分析能力有限,不适合做定制化开发(这个不符合我们需要集成的需求)。学习成本较低上手快,但功能简单,无法支持复杂的业务场景,不支持定制开发。
4、网易有数
一款企业级的数据可视化软件,主打互联网行业用户,但目前的版本功能还比较粗糙,不支持很多功能。比如不支持本地数据库,数据加载没有全量增量加载类型控制,不支持跨库跨数据源的多表关联,页面布局简单,不支持自由式表格。
5、DataFocus
这款可视化工具,从图表的设计、开发,到可视化驾驶舱的开发,是不需要写一行代码的。再复杂的数据分析也可以通过DataFocus的搜索功能来实现。这款工具,其实相当于DataV+QuickBI的混合体,从数据可视化,到数据分析和洞察,功能都涵盖了,而且还自带数据仓库。
6、DataV
这是阿里云的一款大屏可视化工具,天猫双十一大屏就用DataV做的。前端组件的功能也比较多,虽然不能像Ecahrts那样提供开源支持,但是它的前端开发倒是不需要写什么代码。不过,虽然前端省心了,如何链接数据,那还是得写很多SQL的,每次一个图表的开发,如果设计到很多聚合、筛选等等,稍微复杂一点儿的数据展现,就得在写SQL语句下下功夫了。
7、数字冰雹
专注于做数据图像、三维处理、数据分析等相关业务,通过图像可视化方式呈现数据分析,在智慧城市、工业监控用的比较多。就是商业的,不过官网上有很多大屏设计,可以提供灵感。
8、FineReport
这个工具它也能做可视化报表,也能做大屏。因为后端通常连接业务系统数据,所以可以实时连接业务数据,做企业的一些经营数据展示。比如展览中心、BOSS驾驶舱,还有城市交通管控中心、交易大厅等。
书籍
-
数据可视化之美
作者:Julie Steele
内容:
书中有着20多位可视化方面的专家(如艺术家、设计师、评论家、科学家、分析师、统计学家等)在数据可视化方面的经典案例。那些经典案例展示了专家们如何在他们各自的学科领域内开展项目的方法、可视化所能实现的功能和如何使用可视化来改变这个世界。
经典案例:
标签云、纽约地铁图、飞机的飞行线路、社交网络、参议员的关系网络、维基百科文档修改历史、数据库模型、用户浏览纽约时报的行为、虚拟尸检等。
-
鲜活的数据
作者:Nathan Yau
译者:向怡宁
内容:
有人说,“本书就像是一封写给Python、R、地图和数据的情书。”书里面各种各样的分析、数据资源和绝对精美的图表,不仅思路清晰,实例丰富,是经常与数据打交道的入门人士的首选。
-
大数据
作者:涂子沛
内容:
这是中国大数据领域的第一本专著,它引领了中国社会对大数据战略、数据治国和开放数据的讨论热潮。
本书呢,通过讲述美国在那半个多世纪的信息开放和技术创新的历史,借助一些经典案例——奥巴马"前所未有的开放政府"的雄心、美国矿难的悲情历史、数据开放运动的全球兴起,以及云计算、Facebook和推特等社交媒体等等,仔细的讲解了数据创新已经带来和即将会给公民、政府和社会带来的挑战和变革。并且通过书中对美国案例的种种剖析,联系中国现实,一定程度上反应中国到底缺少些什么。
-
数据可视化的基本原理和方法
作者:陈为
内容:
本书对当前科学可视化、信息可视化以及可视分析研究和应用的新形势做了总结,专门为计算机、数据处理、视觉设计、统计、数学、遥感影像等专业本科生开设数据可视化课程而编写的一本教材。本书以数据类型为导向,以行业应用为目标,内容完整,叙述简明。此外,本书的作者还专门地收集和整理了相关的课程教案、典型数据、精彩案例、可视化作品等方面的相关资料。
-
最简单的圆形与最复杂的信息
作者:美黄慧敏(Dona M.Wong)
内容:
本书将数据分析和图形制作有机巧妙地结合在了一起,作者还讲述了怎样将纷繁复杂的图形和陈述报告变得简单而具有表现力,有很强的实际操作性,易于理解,适合入门。
-
The Visual Display of Quantitative Information
作者:Edward R. Tufte
内容:
本书呢,是统计图形,图表,表格方面的经典之作,信息可视化类书籍中的经典。书里面作者运用理论与实践的数据进行图形显示,详细地分析了怎样才能使数据准确有效。它简明扼要的讲解了定量数据的可视化,并且特别强调了可视化对不同变量之间关系的呈现。
案例
一、航线星云
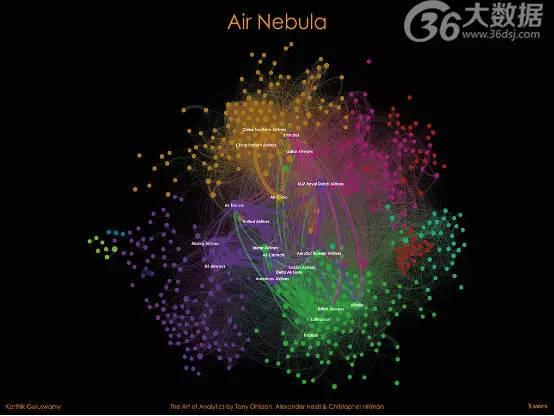
关于洞察
截止到2012年1月,开源网站OPENFLIGHTS.ORG上记载了大约6万条直飞航班信息,这些航班穿梭在3000多个机场间,覆盖了500多条航线。
通过高级分析技术,我们可以看到世界上各家不同的航空公司看起来就像是一个美丽的星云(国际星云的组成部分)。同种颜色的圆点和粗线提供了见解,它们代表提供相同航线的航空公司,显示出它们之间的竞争以及在不同区域间的潜在合作。
这张基于数据可视化的Sigma图表显示了服务城市相似的不同航空公司。图中的圆点或圆圈代表航空公司,连线的粗细和远近则反映两个航空公司之间的相似性;连线越粗或越短则代表两家航司服务的城市越相似。图表中有几组航空公司,直观地表现了它们所服务的地理区域。
这张图表中的关键洞察当然地是航空公司之间的相似性甚至是重叠,它们是中国的南航和东航、阿联酋航空和卡塔尔航空、英航和汉莎航空、美航和达美航空;我们可以从中看出这些公司之间的竞争关系。瑞安航空则通过服务与汉莎航空和英航存在潜在协力的城市占据了一个利基市场;比起意大利或汉莎等其他的欧洲航司,法国航空则与美国联航等美国航空公司更为相似,这也许可以解释为联合品牌效应。本质上说,这是一张多维的韦恩图,用一种简明扼要的方式揭示了不同主体间的复杂关系。
总的来说,这张图表揭示了不同航司之间的相似性和竞争情况,有利于发掘潜在的合作关系、增加市场份额和市场覆盖面。这项技术可以通过不同参与者之间的相同变量,用于分析任何生态系统。
分析技术
这张可视化图表通过Aster App中心生成,运用到了关联挖掘的分析技术,研究上下文中各条目的共现关系。其中关联挖掘的算法是协同过滤,它作用于航线和城市数据,并将数据当做零售篮子数据。也就是说,篮子代表城市,而航空公司则是条目。两个航司之间的相似性由相似性得分确定,计分的原则是比较各个航司独有的航线以及同时运营的航线。之后再将这些成对的相似性得分当做连线的权重,再把各个航司当做节点,共同输入可视化仪器当中,运用具有模块上色技术的force-atlas算法,最终生成出这张美丽的图表。
二、Calling Circles

关于洞察
我们无论何时何地都在使用手机并且产生出非常大量的资料,这些资料代表了我们每天的行为及活动。我们与其他人的每通电话及简讯都对应到我们的社会关系、商业活动以及更广泛的社群互动并且形成了许多复杂互相联结的通话圈。
这个资料视觉化图表是从行动电话使用者的通话模式资料所制作的。每个点都代表一个使用者拨出的手机号码,愈大的点就代表这个号码被拨打愈多次。每条两点之间的线都代表着从一个号码拨打到另一个号码。
每个行动电话使用者都会有一种独特的通话模式,这种模式可以用来发展适合的话费方案并且可以用来定义或预测他/她的行为。举例来说,当一个使用者正要从现在的行动电话服务商转换到另一个服务商时,我们可以从网内及网外发现两个类似的通话模式。
这张特别的图表是在前期由一连串的分析产生用来过滤第一层的通话模式。这里使用到的资料只从在几秒钟的时间取得。从图表的左上角可以看到许多大回圈,这些回圈表示短时间内这些号码被拨打了许多次。可以推测这些号码有可能是机器,像是自动答录机、互动式语音应答(IVR) 系统、安全系统或警报。人类不可能在短时间拨出这么多电话。这些电话会先放置在一个分开的群组,后续的分析就可以集中在个人使用者的通话模式上。
分析技术
我们利用图表来达成资料视觉化,虽然在调整版面格式的参数与传统展示图表不同。有一个常见的问题就是这些互连的图表通常在短时间就会变成非常巨大且因为庞大的互动次数导致几乎不可能被视觉化。从一个高度连结的图表里选出一段范例是一个困难的问题,因为我们需要决定忽略哪些连结。在这个例子里,我们取用来自非常短的时间的资料来达到一个可以呈现的资料范围。
资料格式就相对简单,拨话号码、收话号码、拨话时间、通话时间。我们先利用机器学习(machine-learning) 来对资料作分群然后再利用Aster Lens 来展示图表。
三、互联网络
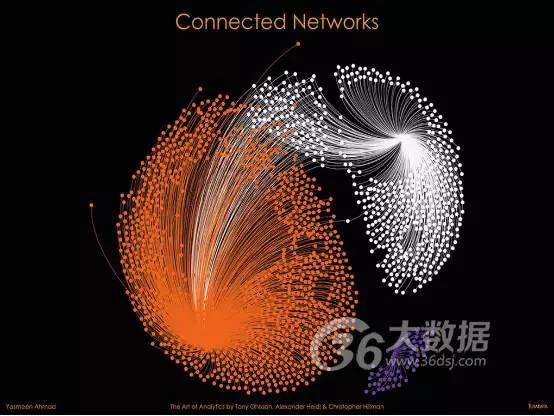
关于洞察
这一匿名可视化报告用于支持一家Telco运营商分析住宅Telco线路。该项目旨在确定线路与网络硬件性能之间的关联,此类关联可能影响到客户体验。
点(节点)代表Telco网络上的DSLAM(数字用户线接入复用器)。DSLAM提供了一项重要服务,能够影响客户呼叫体验;它们可将客户线路连接到主网络。
DSLAM服务级别有多项测量指标,例如衰减、比特率、噪声容限和输出功率,并可针对每条线路整合至三个性能类别。紫色节点显示具备卓越性能的DSLAM,橙色显示具备出色性能的DSLAM,白色显示性能较差的DSLAM。
在图表中,仅少数DSLAM体验到了高质量服务(紫色)。这些 DSLAM 在同一建筑中与主网络基础设施共置,由于靠近中央网络中枢,从而带来了优质服务。大多数客户实现了出色体验(橙色),同时我们发现城市郊区存在服务较差(白色)的DSLAM。
当客户获得可变网络质量时,客户体验和满意度会受到很大影响。Telco的主要目标是确保客户获得一致的体验,即使是那些身处主城市外部的用户也不例外。此图表确定了每个提供可变服务级别的 DSALM;以出色(橙色)和较差(白色)簇之间共享的节点表示。借助这一数据,Telco现在能够调查和优化可变DSLAM。
分析方法
这一西格玛可视化报告使用内建分析和在Teradata Aster平台内发现的可视化创建而成。
收到的数据来自整个城市的住宅线路,其属性包括衰减、比特率等。我们对这些属性进行了整合,以确定表明客户网络体验的性能等级。
这些簇构成了相关性和回归分析的基础,以确定在不同因素下网络性能的变化,这些因素包括:线路技术和长度、调制解调器类型和配置、DSLAM、卡技术、地理位置等。
该西格马可视化图表仅显示了整体分析的一部分,即DSLAM与网络性能间的联系。
四、综合数据库(IDW)淘金热

关于洞察
欢迎来到“中介大数据”的世界。在这个世界里,讽刺地是,大数据将被用于降低成本和优化大数据本身。
如果你可以看到一个大型的综合数据库(IDW)里面,你会发现那是一个由数百万相互关联的数据元素和对象交织成的巨大网络。在一个综合数据库每天加载数据时,成百上千的对象将在一个微小却精心设计的处理链上相互作用,并将越加相互关联紧密。在此过程中,数据被转化、整合,并生成出最终的用户视图和报告。
那很棒,但是,如果你想要缩减数据库加载时间,优化分析生态系统中的数据存储,或者想转到一个双活性系统时,那该怎么办呢?
首创“元数据科学家”保罗.丹瑟提出了这一无名的可视化方法。在Teradata 数据库一个很大的产品持续近20年的发展历史中,这个可视化第一次显示出数据对象网络的完全复杂性。金点(节点)显示数据库对象,灰线(边缘)显示他们相互的依赖性,因此我们可以看见那些微小而相互关联的过程链。大块密集群体是核心的、整合的数据结构,外侧疏散的岛屿则是集市。
可视化让我们能够看到,所有微小的过程链都是相互依赖,且按顺序排列的。因此,它就是优化IDW最好的工具。其图表可以被用来决定双活性选择,并能在没有依赖风险下,针对数据库对象顺序进行细节设计和部署。该可视化还可以揭露出大量各种各样的非正式遗产“提取转换与加载”模式(ETL),这些模式对优化新的加载和转换程序十分的异常与危险。
分析方法
预定的Java应用曾通过获取图形进行可视化,递归式地从每个对象中提取“数据定义语言”(DDL)。其对象均起始于Teradata数据库层次结构中的一个根。每个定义作为候补参考对象被搜索,并匹配一个模式,然后在内存中依据一个完整的数据库对象进行验证。一旦确定有效,“顶点”或者“节点”与“边缘”关系将会被加入“有向非循环图”对象中。
另外,一个对象列表也会输出指定一个有效的顺序部署。顺序是通过“拓补排序法”在图上决定的。有效的顺序部署有很多种。
Teradata系统配置的加载最小化,利用Java应用在客户端进行文本模型匹配和图形处理。
五、Branch社区之树
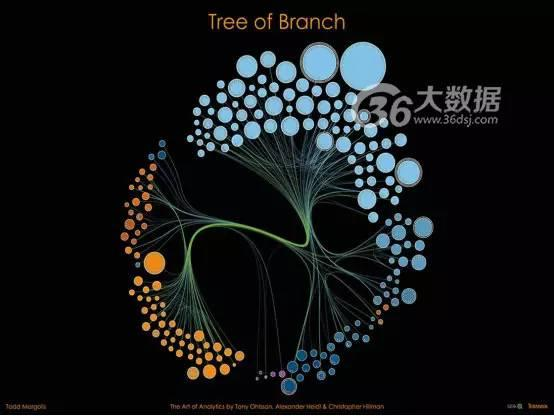
关于洞察
这张可视化图表被用于帮助开发和分析Qlik的开源程序员社区Branch,这个社区被设计成为一个互动性开放式的探索导航平台,而这个新的应用使得访客得以发现关于网站中用户、项目和它们之间关系的新含义。这张图表可以用来理解这个网络社区的社会动态,也能了解每个个体用户的行为。为了加深理解、获取洞察,关于相似性、类目、浏览量、评论和公司的元数据都被反映在这张图表中。
图中的圆点代表不同的项目,其大小代表浏览量的多少,这使得我们可以方便快速地发现那些最受欢迎的项目。节点还反映了项目的参与者及评论的多少,使我们能够直观地看到不同项目中合作程度的高低。图中的圆点按照产品类目进行聚合并着色;圆点之间的连线则代表项目之间就相似程度和用户群的联系。
图中最大的两个点集标识了Qlik社区对于可视化拓展的关注;此外还有七个中等大小、五个小型的点集,向我们展示了这个社区的发展空间。浅蓝色的线条连接着每个类目中的相似项目以及Qlik的两个主要可视化类目;绿色的连线给出了一个令人惊讶的信息:大多数贡献者倾向于跨越整个产品谱系开发项目,这也印证了Qlik分析平台的威力。
分析方法
这张网络可视图利用Qlik Sense生成。图中数据利用Kimono APIs从Qlik Branch网站中收集,并被存到Sense的储存器中。图中的分析主要关注哪些是已经公开的信息,之后也许会整合其他的网络分析技术。
这张可视化图表利用到了HTML, Java, CSS和高人气的D3.js数据驱动可视化库。最初的图层基于把相似项目拉到一起的力导向图;为了按类目进行项目分类,之后又增强了聚合力图层;最后再利用Danny Holten的分层边缘捆绑算法画出连线。我们将来计划开始利用Teradata Aster的K最近邻聚类、朴素贝叶斯分类器等功能,创造更多关于这个数据集的洞察。这张图表依然保持着与新用户活动的互动,并每天进行更新。
Ecarts概述
ECharts是百度开源的纯 Javascript 图表库,目前开源可以与highcharts相匹敌的一个图表库.支持折线图(区域图)、柱状图(条状图)、散点图(气泡图)、K线图、饼图(环形图)、雷达图(填充雷达图)、和弦图、力导向布局图、地图、仪表盘、漏斗图、事件河流图等12类图表,同时提供标题,详情气泡、图例、值域、数据区域、时间轴、工具箱等7个可交互组件,支持多图表、组件的联动和混搭展现。
Echarts特性介绍
-
ECharts的一些基础知识点
一、接口 echarts(enterprise charts 图标库) 二、图类 Bar:柱状图
line:折线图
Scatter:散点图
K:K线图
Pie:饼图
Radar:雷达图
Force:力导布局图
三、组件 Axis:坐标轴 Grid:网络 Polar:极坐标 Title:标题 Tooltip:提示 Legend:图例 data:值
四、基础库
zrender(canvas类库)
Echarts3.x与Echarts2.x的区别
-Echarts2.x的使用方法 Echarts2.x更加强调模块化,因此在引入时官方推荐使用模块化包引入,引入方式也很简单:
require.config(
{
paths: './dist'
}
);
-Echarts3.x的使用方法 ECharts 3 开始不再强制使用 AMD 的方式按需引入,代码里也不再内置 AMD 加载器。因此引入方式简单了很多,只需要像普通的 JavaScript 库一样用 script 标签引入。
<header>
<meta charset="utf-8">
<!-- 引入 ECharts 文件 -->
<script src="echarts.min.js"></script>
</header>
一个基本的柱状图
option = {
xAxis: {
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [{
data: [120, 200, 150, 80, 70, 110, 130],
type: 'bar',
showBackground: true,
backgroundStyle: {
color: 'rgba(220, 220, 220, 0.8)'
}
}]
};
Echarts基础的开发模板
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Echarts图表</title>
<script src="../js/echarts.min.js"></script>
</head>
<body>
<div id="main" style="width:600px;height:400px;"></div>
</body>
</html>
<script>
var myChart=echarts.init(document.getElementById('main'))
var option={
legend:{
padding:10,
itemGap:10,//图例间隔
data:['邓艳波','杨国娥']//legend的data值要和series的对象的每个name 值相对应,不然不出来lenend
},
tooltip:{//悬浮的时候提示框
trigger:'item'//触发方式
},
xAxis:{
type:'category',//什么类型的,比如数值?
data:['周一','周二','周三','周四','周五','周六','周日']
},
yAxis:{
type:'value',
boundaryGap:[0.1,0.1],//类目起始和结束两端空白策略,见下图,默认为true留空,false则顶头
splitNumber:4,//数值的分割段数,不指定的时候根据最大值最小值进行划分
},
series:[
{
name:'邓艳波',//系列名如启用legend,该值将被legend.data索引相关
type:'line',//折线图
data:[112,23,45,56,233,343,454,89,343,123,45,76]
},
{
name:'杨国娥',//系列名
type:'line',//折线图
data:[54,543,23,322,33,63,111,222,23]
}
]
}
myChart.setOption(option)
</script>
一个基本的折线图
option = {
xAxis: {
type: 'category',
data: ['Mon', 'Tue', 'Wed', 'Thu', 'Fri', 'Sat', 'Sun']
},
yAxis: {
type: 'value'
},
series: [{
data: [820, 932, 901, 934, 1290, 1330, 1320],
type: 'line'
}]
};
动态数据展示折线图
option = {
title: {
text: '折线图堆叠'
},
tooltip: {
trigger: 'axis'
},
legend: {
data: ['邮件营销', '联盟广告', '视频广告', '直接访问', '搜索引擎']
},
grid: {
left: '3%',
right: '4%',
bottom: '3%',
containLabel: true
},
toolbox: {
feature: {
saveAsImage: {}
}
},
xAxis: {
type: 'category',
boundaryGap: false,
data: ['周一', '周二', '周三', '周四', '周五', '周六', '周日']
},
yAxis: {
type: 'value'
},
series: [
{
name: '邮件营销',
type: 'line',
stack: '总量',
data: [120, 132, 101, 134, 90, 230, 210]
},
{
name: '联盟广告',
type: 'line',
stack: '总量',
data: [220, 182, 191, 234, 290, 330, 310]
},
{
name: '视频广告',
type: 'line',
stack: '总量',
data: [150, 232, 201, 154, 190, 330, 410]
},
{
name: '直接访问',
type: 'line',
stack: '总量',
data: [320, 332, 301, 334, 390, 330, 320]
},
{
name: '搜索引擎',
type: 'line',
stack: '总量',
data: [820, 932, 901, 934, 1290, 1330, 1320]
}
]
};
