

一、从输入 URL 到页面加载完成,发生了什么?
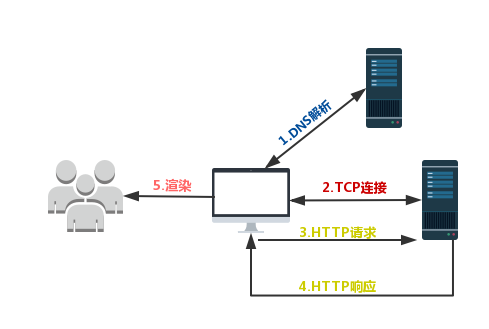
1.DNS解析
2.TCP连接
3.HTTP请求跑出
4.服务端处理请求,HTTP响应返回
5.浏览器拿到响应数据,解析响应内容,把解析的结果展示给用户
二、前端性能优化知识图谱
三、WebPack性能调优与Gzip原理
大家可以从第一节的示意图中看出,我们从输入 URL到显示页面这个过程中,涉及到网络层面的,有三个主要过程:
1.DNS解析
2.TCP连接
3.HTTP请求/响应
对于 DNS 解析和 TCP 连接两个步骤,我们前端可以做的努力非常有限。相比之下,HTTP 连接这一层面的优化才是我们网络优化的核心。
HTTP 优化有两个大的方向:
①减少请求次数
②减少单次请求所花费的时间
这两个优化点直直地指向了我们日常开发中非常常见的操作——资源的压缩与合并。没错,这就是我们每天用构建工具在做的事情。而时下最主流的构建工具无疑是 webpack,所以我们这节的主要任务就是围绕业界霸主 webpack 来做文章。
webpack 的优化瓶颈,主要是两个方面:
①webpack 的构建过程太花时间
②webpack 打包的结果体积太大
webpack优化方案
1.不要让load做太多事
module: {
rules: [
{
test: /\.js$/,
exclude: /(node_modules|bower_components)/,
use: {
loader: 'babel-loader',
options: {
presets: ['@babel/preset-env']
}
}
}
]
}
这段代码帮我们规避了对庞大的 node_modules 文件夹或者 bower_components 文件夹的处理。但通过限定文件范围带来的性能提升是有限的。除此之外,如果我们选择开启缓存将转译结果缓存至文件系统,则至少可以将 babel-loader 的工作效率提升两倍。要做到这点,我们只需要为 loader 增加相应的参数设定:
loader: 'babel-loader?cacheDirectory=true'
以上都是在讨论针对 loader 的配置,但我们的优化范围不止是 loader 们。
2.使用第三方库
第三方库以 node_modules 为代表,它们庞大得可怕,却又不可或缺。
处理第三方库的姿势有很多,其中,Externals 不够聪明,一些情况下会引发重复打包的问题;而 CommonsChunkPlugin 每次构建时都会重新构建一次 vendor;出于对效率的考虑,我们这里为大家推荐 DllPlugin。
DllPlugin 是基于 Windows 动态链接库(dll)的思想被创作出来的。这个插件会把第三方库单独打包到一个文件中,这个文件就是一个单纯的依赖库。这个依赖库不会跟着你的业务代码一起被重新打包,只有当依赖自身发生版本变化时才会重新打包。
用 DllPlugin 处理文件,要分两步走:
①基于 dll 专属的配置文件,打包 dll 库
②基于 webpack.config.js 文件,打包业务代码
以一个基于 React 的简单项目为例,我们的 dll 的配置文件可以编写如下:
const path = require('path')
const webpack = require('webpack')
module.exports = {
entry: {
// 依赖的库数组
vendor: [
'prop-types',
'babel-polyfill',
'react',
'react-dom',
'react-router-dom',
]
},
output: {
path: path.join(__dirname, 'dist'),
filename: '[name].js',
library: '[name]_[hash]',
},
plugins: [
new webpack.DllPlugin({
// DllPlugin的name属性需要和libary保持一致
name: '[name]_[hash]',
path: path.join(__dirname, 'dist', '[name]-manifest.json'),
// context需要和webpack.config.js保持一致
context: __dirname,
}),
],
}
编写完成之后,运行这个配置文件,我们的 dist 文件夹里会出现这样两个文件:
vendor-manifest.json
vendor.js
vendor.js 不必解释,是我们第三方库打包的结果。这个多出来的 vendor-manifest.json,则用于描述每个第三方库对应的具体路径
我们只需在 webpack.config.js 里针对 dll 稍作配置:
const path = require('path');
const webpack = require('webpack')
module.exports = {
mode: 'production',
// 编译入口
entry: {
main: './src/index.js'
},
// 目标文件
output: {
path: path.join(__dirname, 'dist/'),
filename: '[name].js'
},
// dll相关配置
plugins: [
new webpack.DllReferencePlugin({
context: __dirname,
// manifest就是我们第一步中打包出来的json文件
manifest: require('./dist/vendor-manifest.json'),
})
]
}
一次基于 dll 的 webpack 构建过程优化,便大功告成了!
Happypack——将 loader 由单进程转为多进程
const HappyPack = require('happypack')
// 手动创建进程池
const happyThreadPool = HappyPack.ThreadPool({ size: os.cpus().length })
module.exports = {
module: {
rules: [
...
{
test: /\.js$/,
// 问号后面的查询参数指定了处理这类文件的HappyPack实例的名字
loader: 'happypack/loader?id=happyBabel',
...
},
],
},
plugins: [
...
new HappyPack({
// 这个HappyPack的“名字”就叫做happyBabel,和楼上的查询参数遥相呼应
id: 'happyBabel',
// 指定进程池
threadPool: happyThreadPool,
loaders: ['babel-loader?cacheDirectory']
})
],
}
3.删除冗余代码
一个比较典型的应用,就是 Tree-Shaking。
Tree-Shaking 的针对性很强,它更适合用来处理模块级别的冗余代码。至于粒度更细的冗余代码的去除,往往会被整合进 JS 或 CSS 的压缩或分离过程中。
这里我们以当下接受度较高的 UglifyJsPlugin 为例,看一下如何在压缩过程中对碎片化的冗余代码(如 console 语句、注释等)进行自动化删除:
const UglifyJsPlugin = require('uglifyjs-webpack-plugin');
module.exports = {
plugins: [
new UglifyJsPlugin({
// 允许并发
parallel: true,
// 开启缓存
cache: true,
compress: {
// 删除所有的console语句
drop_console: true,
// 把使用多次的静态值自动定义为变量
reduce_vars: true,
},
output: {
// 不保留注释
comment: false,
// 使输出的代码尽可能紧凑
beautify: false
}
})
]
}
按需加载
首先 webpack 的配置文件要走起来:
output: {
path: path.join(__dirname, '/../dist'),
filename: 'app.js',
publicPath: defaultSettings.publicPath,
// 指定 chunkFilename
chunkFilename: '[name].[chunkhash:5].chunk.js',
},
路由处的代码也要做一下配合:
const getComponent => (location, cb) {
require.ensure([], (require) => {
cb(null, require('../pages/BugComponent').default)
}, 'bug')
},
<Route path="/bug" getComponent={getComponent}>
核心就是这个方法:require.ensure(dependencies, callback, chunkName)
这是一个异步的方法,webpack 在打包时,BugComponent 会被单独打成一个文件,只有在我们跳转 bug 这个路由的时候,这个异步方法的回调才会生效,才会真正地去获取 BugComponent 的内容。这就是按需加载。
