

1. redis key过期删除原理。
官网解释

简言之:
消极方法(passive way)
在主键被访问时如果发现它已经失效,那么就删除它
passive way 不能清除不被访问的key,所以还是需要active way来清理。
积极方法(active way)
a. 随机测试 20 个带有timeout信息的key;
b. 删除其中已经过期的key;
c. 如果超过25%的key被删除,则重复执行步骤a;
这是一个简单的概率算法(trivial probabilistic algorithm),基于假设我们随机抽取的key代表了全部的key空
间。
2. redis 发布订阅。
基本使用
Redis提供了发布订阅功能,可以用于消息的传输,Redis提供了一组命令可以让开发者实现“发布/订阅”模式 (publish/subscribe) . 该模式同样可以实现进程间的消息传递,它的实现原理是 发布/订阅模式包含两种角色,分别是发布者和订阅者。订阅者可以订阅一个或多个频道,而发布者可以向指定的 频道发送消息,所有订阅此频道的订阅者都会收到该消息 发布者发布消息的命令是PUBLISH, 用法是
PUBLISH channel message
比如向channel.1发一条消息:hello
PUBLISH channel.1 "hello"
这样就实现了消息的发送,该命令的返回值表示接收到这条消息的订阅者数量。因为在执行这条命令的时候还没有 订阅者订阅该频道,所以返回为0. 另外值得注意的是消息发送出去不会持久化,如果发送之前没有订阅者,那么后 续再有订阅者订阅该频道,之前的消息就收不到了.
订阅者订阅消息的命令是SUBSCRIBE,用法是
SUBSCRIBE channel [channel …]
该命令同时可以订阅多个频道,比如订阅channel.1的频道。
SUBSCRIBE channel.1
执行SUBSCRIBE命令后客户端会进入订阅状态
使用场景
redis的哨兵就是用到了发布订阅监控集群状态,还有简单的消息中间件。
3. redis 的数据是如何持久化的。
RDB(快照)
可以通过 save(阻塞)、bgsave(非阻塞,fork一个子进程进行快照保存)
AOF(保存操作命令)
对于同一个key的多次操作命令都会记录,会导致文件过大,这时候可以重写AOF文件。
重写AOF文件原理:
-
对当前redis存在数据进行备份,而不是在原文件上修改。
-
备份过程中的请求被记录到缓存。
-
将缓存记录到重写的AOF文件。
4. redis 的内存回收策略。
一共有五种回收策略:
针对所有key:
allkeys-lru:最近最少使用的key淘汰;
allkeys-random:随机淘汰。
针对设置了过期时间的key:
volatile-random:随机淘汰;
volatile-lru:最近最少使用淘汰;
volatile-ttl:过期时间最短的淘汰。
5. redis 是单进程单线程,为什么处理速度这么快。
基于事件驱动模型, IO多路复用,即一个线程管理多个io连接
6. redis 保证原子性。
lua脚本的支持。
7. redis 集群,哨兵模式。
Master-slaver,选主需要用到哨兵。哨兵高可用(集群,相互监听)。哨兵通过pub/sub订阅所有集群中的节点。
8. redis-cluster数据分区规则?
redis-cluster分为多个节点组,每个节点组有且只有一个master和多个slaver,采用hash分区规则,
虚拟槽分区巧妙地使用了哈希空间,使用分散度良好的哈希函数把所有的数据映射到一个固定范围内的整数集合,
这个集合定义为槽(slot)。比如Redis Cluster槽的范围是0 ~ 16383。槽是集群内数据管理和迁移的基本单位。采用
大范围的槽的主要目的是为了方便数据的拆分和集群的扩展,每个节点负责一定数量的槽。对key进行hash操作,
确定key的分片位置。
9. 如何将相关联的key分布在同一个分片?
HashTags
通过分片手段,可以将数据合理的划分到不同的节点上,这本来是一件好事。但是有的时候,我们希望对相关联的 业务以原子方式进行操作。举个简单的例子 我们在单节点上执行MSET , 它是一个原子性的操作,所有给定的key会在同一时间内被设置,不可能出现某些指定 的key被更新另一些指定的key没有改变的情况。但是在集群环境下,我们仍然可以执行MSET命令,但它的操作不 在是原子操作,会存在某些指定的key被更新,而另外一些指定的key没有改变,原因是多个key可能会被分配到不 同的机器上。 所以,这里就会存在一个矛盾点,及要求key尽可能的分散在不同机器,又要求某些相关联的key分配到相同机器。 这个也是在面试的时候会容易被问到的内容。怎么解决呢? 从前面的分析中我们了解到,分片其实就是一个hash的过程,对key做hash取模然后划分到不同的机器上。所以为 了解决这个问题,我们需要考虑如何让相关联的key得到的hash值都相同呢?如果key全部相同是不现实的,所以 怎么解决呢?在redis中引入了HashTag的概念,可以使得数据分布算法可以根据key的某一个部分进行计算,然后 让相关的key落到同一个数据分片 举个简单的例子,加入对于用户的信息进行存储, user:user1:id、user:user1:name/ 那么通过hashtag的方式, user:{user1}:id、user:{user1}.name; 表示 当一个key包含 {} 的时候,就不对整个key做hash,而仅对 {} 包括的字符串做hash。
10. 分片迁移
删除一个主节点,将该节点的槽均匀分布到剩余的节点组中。
新增一个主节点,将已存在的节点中的槽迁移出一些到新节点中。
11. 槽迁移
槽迁移的过程中有一个不稳定状态,这个不稳定状态会有一些规则,这些规则定义客户端的行为,从而使得Redis Cluster不必宕机的情况下可以执行槽的迁移。下面这张图描述了我们迁移编号为1、2、3的槽的过程中,他们在 MasterA节点和MasterB节点中的状态。
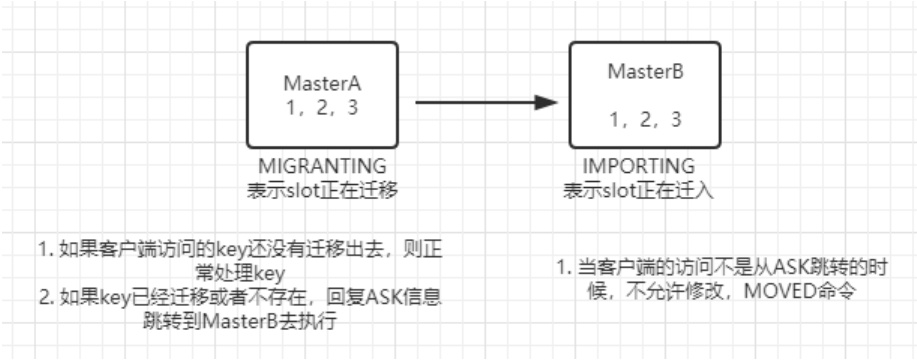
简单地说:
-
当一个变更请求到达MasterA后,会将MasterA中key对应的槽设置为MIGRANTING状态,表示该槽正在像MasterB迁移。 若该槽还没迁移到MasterB,正常处理。若该槽已经迁移完成,则回复客户端ASK信息让他跳转到MasterB去执行。
-
当一个变更请求到达MasterB后,会将MasterB中key对应的槽设置为IMPORTING状态,表示对应的slot正在向MasterB迁入。 当客户端的请求不是从第一步的ASK请求跳转过来的。这时候Master会将这个请求转发给Master进行处理(回到第一步),防止冲突。
