

常见面试问题
- redis集群模式的工作原理?
- 什么是一致性hash算法?
redis cluster
redis集群模式(redis cluster)是Redis的分布式解决方案,在3.0版本推出的分布式解决方案,使得具有高可用、可扩展性、分布式、容错 等特性。它将数据进行分片,每个master上放一部分数据,支撑n个master node,每个master还可以挂载slave,如果master挂掉了,会自动切换到slave实例上来。在redis cluster架构下,每个redis要放开两个端口号,例如一个是6379,另外一个就是加10000的端口号16379,16379端口号是用来进行节点间通信的,用来进行故障检测,配置更新,故障转移授权。redis cluster节点间是采用gossip协议进行通信的。
如何进行分片
- hash算法
hash算法很简单,比如你部署n个master实例,那么如何将一个key存储到对应master实例上呢?就是通过计算key的hash值然后对N取模,通过这样的方式映射到N个实例上。很显然这样缺点是,当有一个节点挂了或者想扩容一个节点,你的所有缓存基本上都失效了,这样会数据库的压力访问剧增,从而可能导致数据库宕机。
- 一致性hash算法
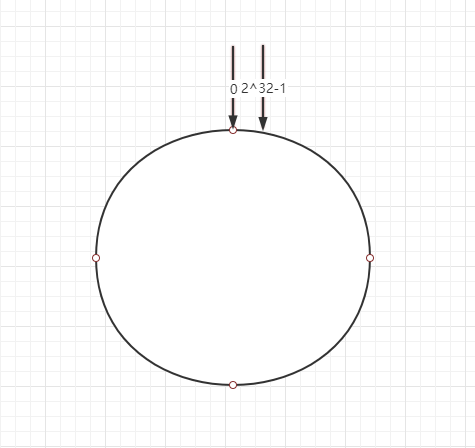
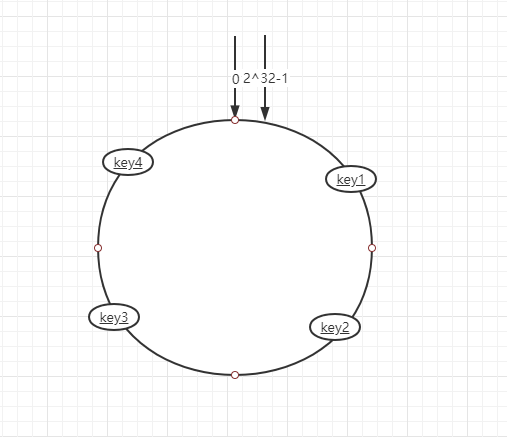
一致性hash算法它其实也是采用取模的方法,它是对2^32取模,我们按照常用的hash算法将对应的key哈希到一个具有2^32个桶的空间中,我们可以想象成0~2^32-1头尾相连组成一个闭合的hash环。
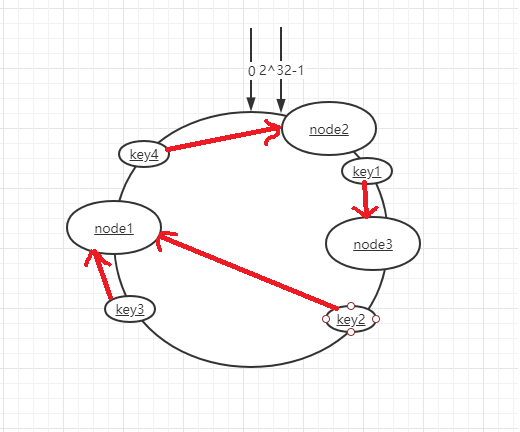
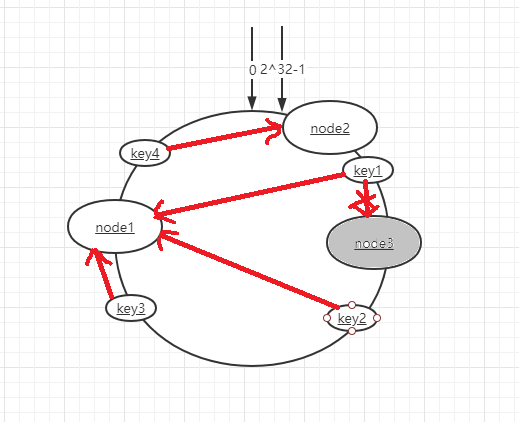
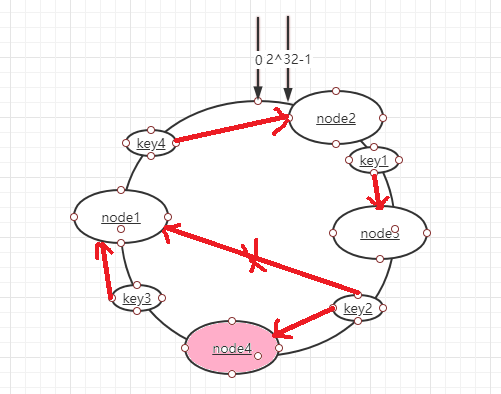
然而,当服务节点太少时,一致性hash算法容易导致hash环的数据倾斜问题,造成节点数据分布不均匀,例如集群只有两个节点,我们可以看下图,造成大量数据分布在A节点。
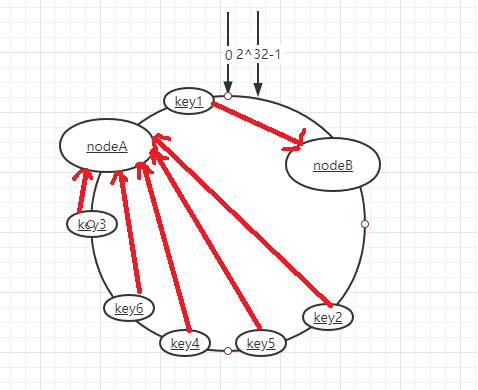
为了解决这种数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。具体做法可以在服务器IP或主机名的后面增加编号来实现,在实际应用中,通常将虚拟节点数设置为32甚至更大,因此即使很少的服务节点也能做到相对均匀的数据分布。
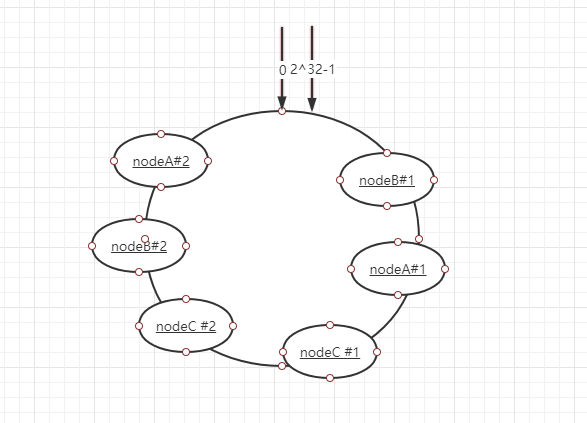
- redis cluster hash slot算法
redis cluster有固定的16384个hash slot,对每个key计算CRC16值,然后对16384取模,可以获取key对应的hash slot,redis cluster中每个master都会持有部分slot,hash slot让node的增加和移除很简单,增加一个master,就将其他master的hash slot移动部分过去,减少一个master,就将它的hash slot移动到其他master上去,并且移动hash slot的成本是非常低的。
