2.Kafka消息详解
注:本文参考自 极客时间专栏 kafka核心技术与实战,书籍 深入理解kafka
2.1消息格式
2.1.1 消息集合版本 变迁
2.1.1.1. V0,V1版本
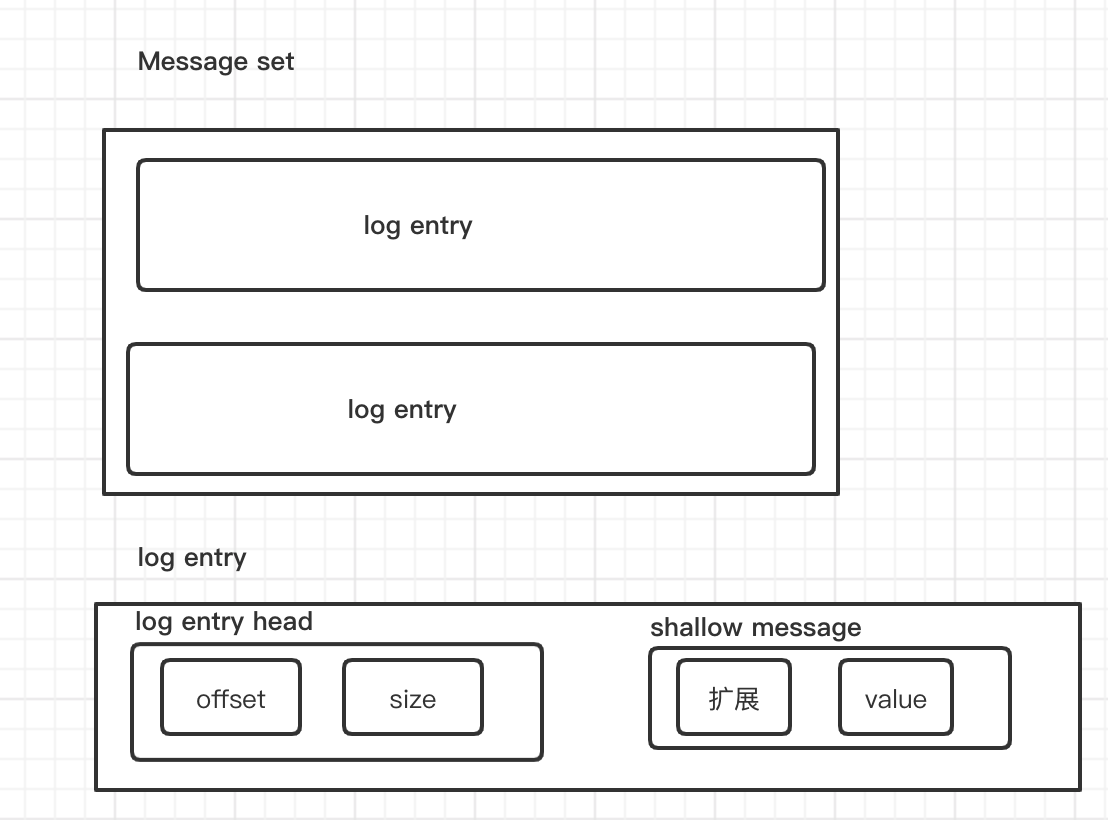
如上图所示,为kafka 的消息集合以及消息的日志项。一个消息集合总是包含了若干个日志项,每个日志都封装了实际的消息和一组元数据信息。kafka不会再消息层面上直接操作,总是在消息集合上进行写入操作。
- shallow message
- value 字段 ,如果消息没有压缩,value存储的就是消息本身。否则,kafka会将多条消息封装到value字段,此时shallow message 被称为 wrapper 消息(外部消息),value 字段包含的所有压缩消息,称为 inner message(V0,V1版本中的日志项职能包含一条浅层消息)。
- log entry head
- offset(该消息在分区日志中的offset)
- 如果不压缩,就是消息的offset
- 如果压缩,是inner message 最后一条消息的offset(此时,如果需要获取 日志项的base offset (起始位移)是非常困难的,broker 需要执行解压缩的操作,并且对inner message 进行深度遍历计算等操作。
- offset(该消息在分区日志中的offset)
2.1.1.2. V2版本
V2版本的消息集合变成了RecodBatch。
下图为最新的RecordBatch格式:
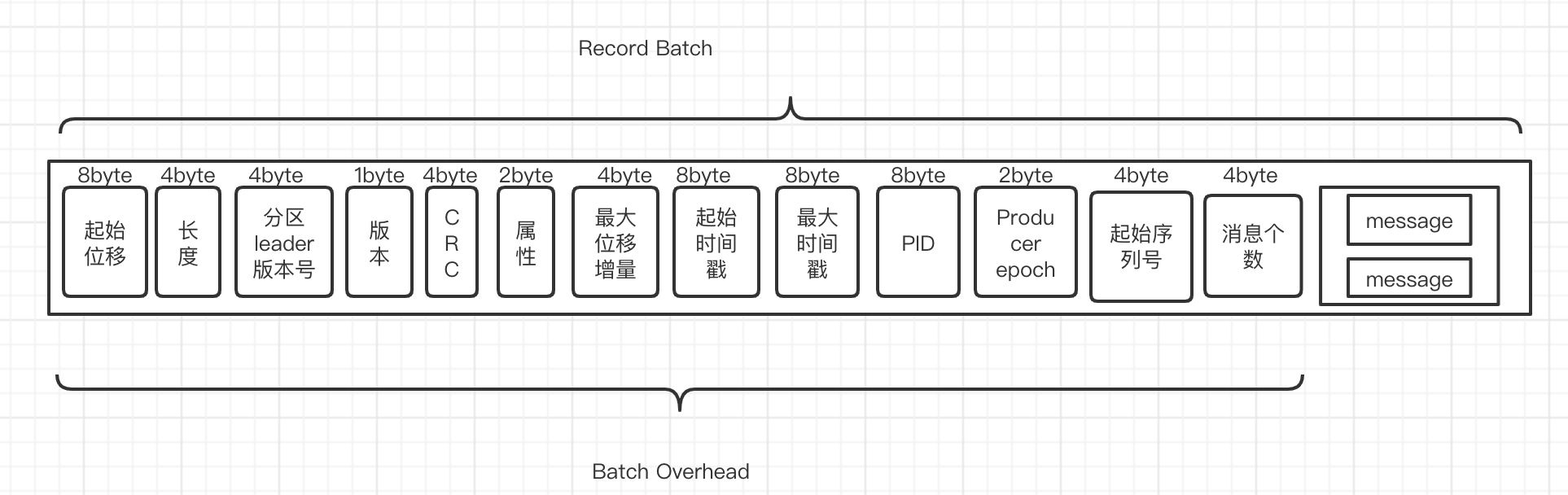
- CRC 从消息层面移到batch 层
- PID、producer epoch和起始序列号,都是为了实现0.11.0版本的新特性幂等性producer和事务性producer 而存在的。
- V2版本看似增加了batch的开销,增加到了61个字节,但是v2 版本的batch允许保存多条消息,因此分摊到每条消息上,总体上反而减少了空间。
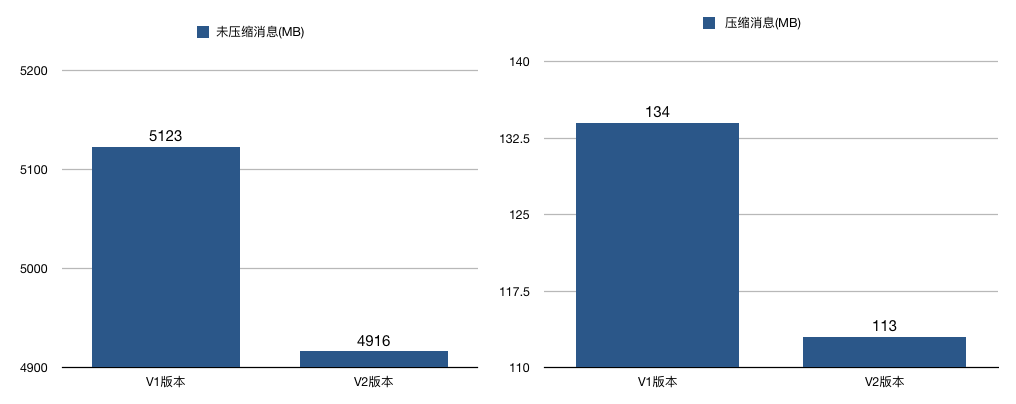
不同版本占据内存大小的对比:
2.1.2 Message 版本变迁
2.1.2.1 V0 版本(0.10.0以前)
消息格式:
| Message | -字段- | -含义- |
|---|---|---|
| message head | CRC校验码 | 4个字节CRC校验码,用于确保消息再传输过程中不会被恶意篡改 |
| message head | magic字段 | 单字节的版本号,V0 magic = 0 ,V1 magic =1 ,v2 magic =2 |
| message head | attribute | 单个字节属性字段,目前仅仅使用后三位来表示消息传输的压缩类型 |
| message head | key长度字段 | 4字节的消息key长度信息。若为指定key,默认值为-1 |
| message body | key值 | 消息key,长度由key长度字段确定,如果为-1,则没有该消息字段 |
| message head | value长度字段 | 4字节的消息长度,未指定 默认值为-1 |
| message body | value字段 | 消息value 长度由value长度字段确定 -1,消息没有该字段 |
消息头一共占用了14byte,一条V0版本的kafka消息再小也无法小于14个字节,否则会被kafka视为非法消息。
attribute: 1个byte,8个bit位,用最低三位来代表消息压缩的格式
- 0x00: 未启用压缩
- 0x01: GZIP
- 0x02: Snappy
- 0x03: LZ4
消息实践:
定义一条压缩格式为LZ4 ,key是“mykey” value 是“hellokafka”的消息:
- CRC : 对所有字段进行CRC校验后的CRC值,防止消息被恶意篡改
- Magic: 1
- attribute: 0x03
- key长度:5
- key:mykey
- value长度10
- value:hellokafka
messageTotalByte = 4 + 1 + 1 + 4 + 5 + 4 + 10 = 29byte
若不指定key key长度字段也会占用4个byte,少的byte只是key的字节数,因此可以进行改进。
2.1.2.2 V1版本(0.10.0)
V0版本消息格式弊端:
- 1.消息不存储时间的话,kafka定期删除消息日志的时候,只能依靠日志段文件的“最近修改时间”,但是这种方式事不安全的,一旦我们通过系统的命令操作了文件,并且更新了该日志文件的最近修改时间,kakfa就不能对其做成正确的判断了。
- 2.很多流处理框架都需要消息的保存时间以便对消息执行时间窗口等聚合操作。
V1版本消息格式:
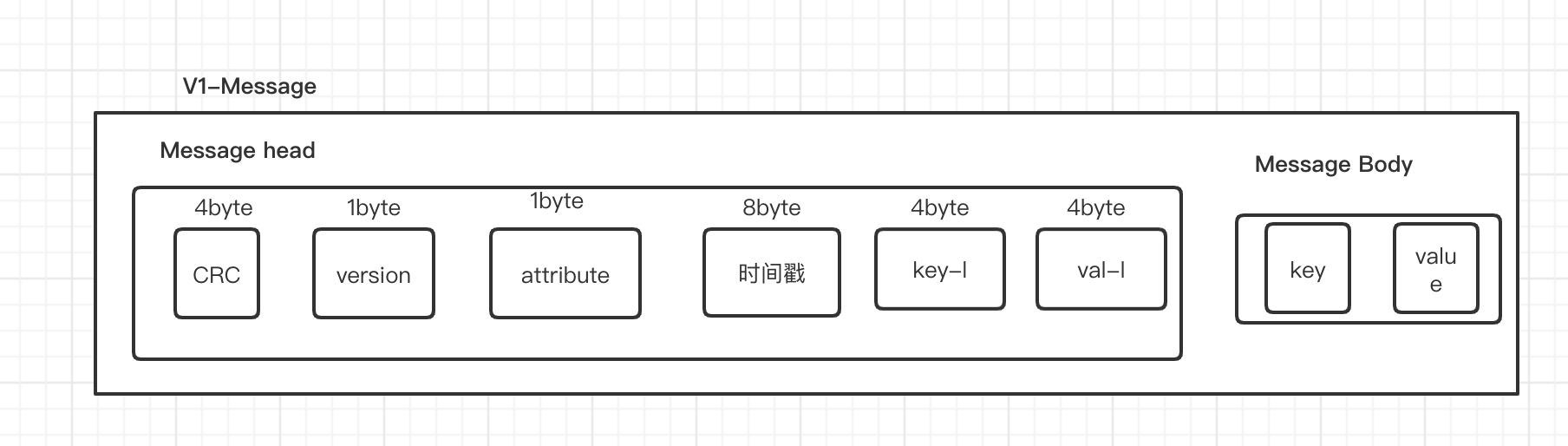
如上图所示,仅仅是对V0版本的消息增加了一个字段时间戳(Timestamp),这个字段占用了8个字节。因此相对于V0版本的消息,每条V1版本的消息要多8个byte。
而且还在attribute字段上做了一下变化,V0版本的attribute的后三位是表示压缩类型的,这个V1不变,但是V1版本的第四位,进行表示时间戳类型。
时间戳类型
- CREATE_TIME:producer 指定时间戳
- LOG_APPEND_TIME : broker 指定时间戳
2.1.2.3 V2 版本([0.11.0,now) )
时间的车轮总是滚滚向前,随着时间的推移,旧版消息的弊端也一一体现出来,总体如下:
- 空间利用率不高
- key-lengh 和value-size 字段总是4byte,显得有些浪费,因为大部分场景来说,key和value的字段只用一个字节来存储都足矣,每条消息都浪费3个字节,试想每天发送十几亿条消息的kafka会浪费多少数据。
- 只保存最新的消息的位移
- 若启用压缩,offset字段就只会保存,最新的消息唯一,我们需要获得第一条消息的位移,就必须先解压缩,然后从后向前遍历获取offset的值
- 冗余的消息级CRC校验
- 每条消息都进行CRC校验显的有些多余
- 为保存消息的长度
- 需要用到消息长度的时候,都需要重新计算,而且每次计算为了防止对原始数据的破坏,都会使用的大量的副本,解序列化的效率很低。
V2版消息格式:

新版消息做的优化:
- 1.可变长度:
kafka会根据具体的情况来却确定到底需要几个字节来保存数据,为了在序列化时降低使用的字节数,kafka借鉴了 Google ProtoBuffer中的Zig-zag编码方式,可以使用较少的字节来保存绝对值很小的负数。
首先,因为key和value往往跟我们业务挂钩,所以长度都不会太大,往往一个字节就可以存储的下,相对于之前版本的无脑的四个字节,省下了六个字节,使用新的编码方式,是为了不像之前版本那样用32位整数的补码来保存负数,直接使用新的编码方式,对于绝对值不大的负数来说也是占一个字节的,编码规则如下图:
| -编码前- | -编码后- |
|---|---|
| 0 | 0 |
| -1 | 1 |
| 1 | 2 |
| -2 | 2 |
| 2 | 4 |
可能多个字节来编码一个数字,Zig-zag会固定的把第一个bit位作为标记,表示该字节是否位某个数编码后的最后一个字节。0就表示是,1表示不是,继续读取后边的字节。
一个字节可以表示的范围为[-64-64].
- 2.增加消息总长度字段
- 一次性就是出消息的总长度,保存下来,就不用每次使用的时候都重新计算了。
- kafka可以直接通过消息的总长度,创建出对应的ByteBuffer,然后分别装填其他字段,简化了消息的处理过程,
- 可以实现消息遍历的时候快速的跳跃和过滤,省去了很多空间拷贝的开销。
- 3.保存时间戳增量
- Batch 存储了其实时间戳的值,每个消息中储存的都是增量时间戳。如果所有的时间戳的差值在64ms之内,只需要一个字节就可以存储,不像之前的需要8个字节去存储。
- 4.保存位移增量
- 与保存增量时间戳一样,使用可变长度的字节来存储,不用固定的八个字节,占用了太多的空间。
- 5.抽取CRC校验
- 对整个 Record Batch 进行CRC校验,而不是每个message都进行CRC校验
- 废弃attribute字段
- 把之前的attribute字段抽取出来放在batch中。抽取出来的attribute字段由两个字节存储,后四位还是和之前的含义一样,第六位和第七位都是和事务相关的,message存储的attribute字段保留作为扩展字段。
2.2 消息压缩
2.2.1为什么要压缩?
压缩(compressing),时间换空间的一种思想,用cpu时间去换取磁盘io或者网络io,希望以较小的cpu开销来换取更小的磁盘占用或者更少的网络io传输。
2.2.1 kafka何时压缩与解压缩
因为压缩和解压缩都会占用cpu,所以我们要尽量减少不必要的压缩和解压缩。
kafka的正常压缩与解压缩的时机为:Producer 压缩 -> Broker保持 -> Consumer 解压缩
不必要的压缩和解压缩:
- 当Produer 和 Broker 指定的压缩规则不一致的时候,会先对消息进行解压缩,然后再按照Broker进行压缩
- Broker 做消息格式转换,为了兼容老版本的消费者程序。也会对消息进行解压缩和压缩。需要注意的是在这里不仅仅需要压缩和解压缩,而且还丧失了kafka 的**Zero Copy **的特性,对性能有极大的影响。
所以我们要避免这些不必要的操作。
目前必要的压缩和解压缩:
- 进行CRC校验,需要先解压缩,进行消息格式的校验。(要保证数据正确性的前提下去提升性能)。
2.2.1压缩的种类
如下图所示是压缩算法的对比(摘自极客时间kafka专栏):
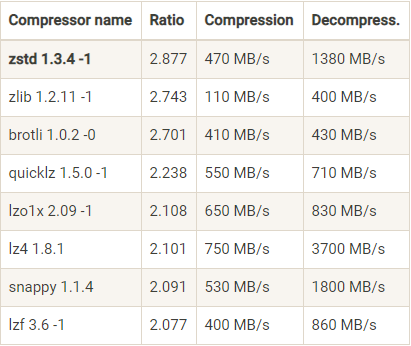
- Ratio(压缩比)
- 压缩比越高,相同的大小的文件压缩后的size 就越小。
- Compression(吞)
- D ecompress(吐)
评判一个压缩算法的标准不仅仅仅仅从一个方面来评判,要通过压缩比,和吞吐量以来来进行评判,具体使用那个要根据自己的应用场景来进行评估。
压缩虽好当时当我们系统的cpu负载已经很高的情况下还是不要开启压缩模式了。只会继续的增加我们的系统的负载,效果往往是适得其反。
2.3消息存储
2.3.1消息如何存储
kafka的消息是以分区为单位来存储的,每条消息根据对应的分区数以及制定的路有策略路由到相应的分区所在的Broker上,分区中的每一条消息都会有一个唯一的序列号,就是通常所说的(offset)
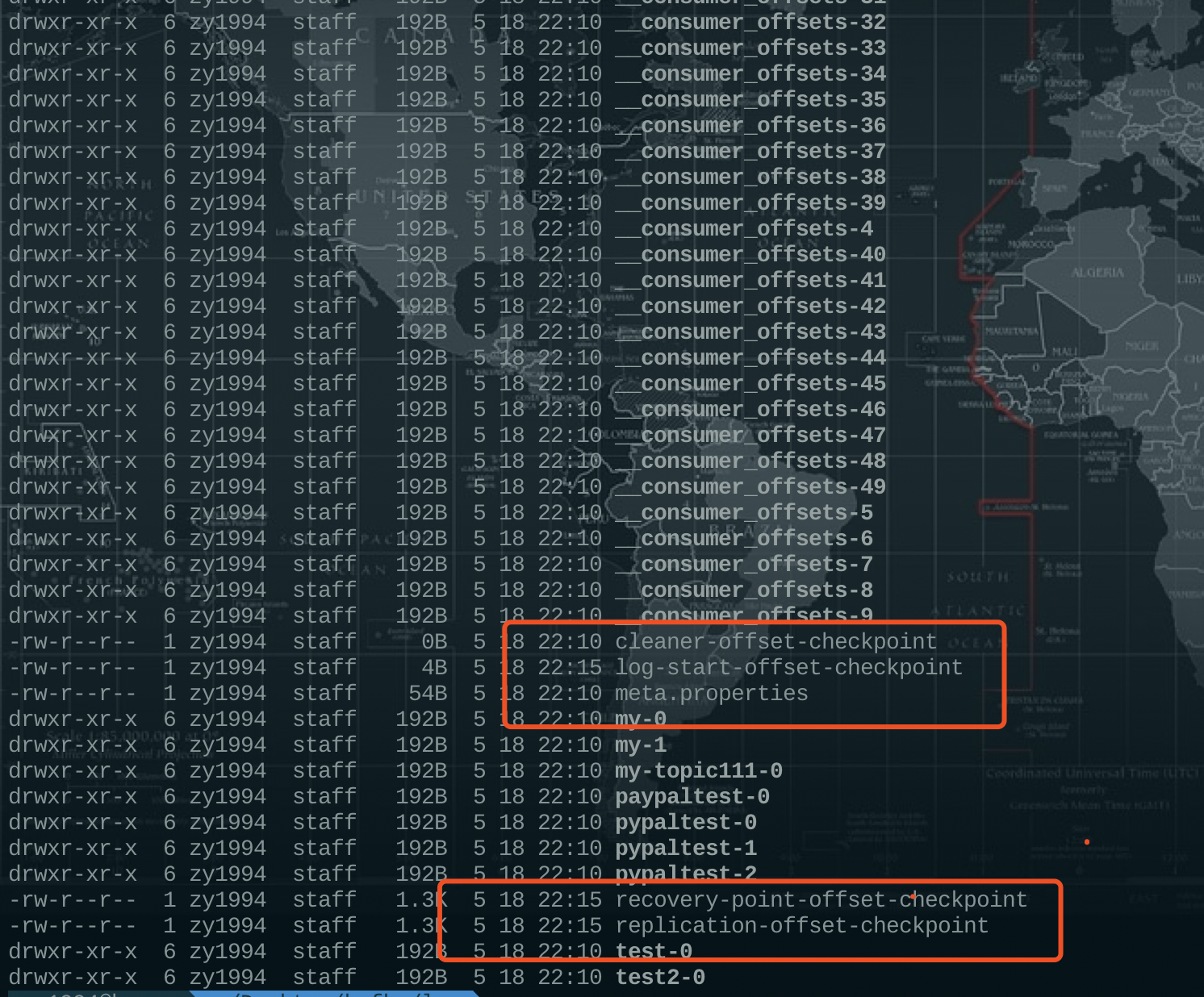
一个分区对应一个Log,Log在物理上只是文件夹的形式,下边有很多的 LogSegmemt,一个LogSegment 对应在磁盘上就是**.log文件,.index文件,.timeindex**文件,以及其他文件组成,如下图所示,只是一个Topic存储数据的逻辑概念,具体的存储会根据Topic路由到不同的分区,进行存储。
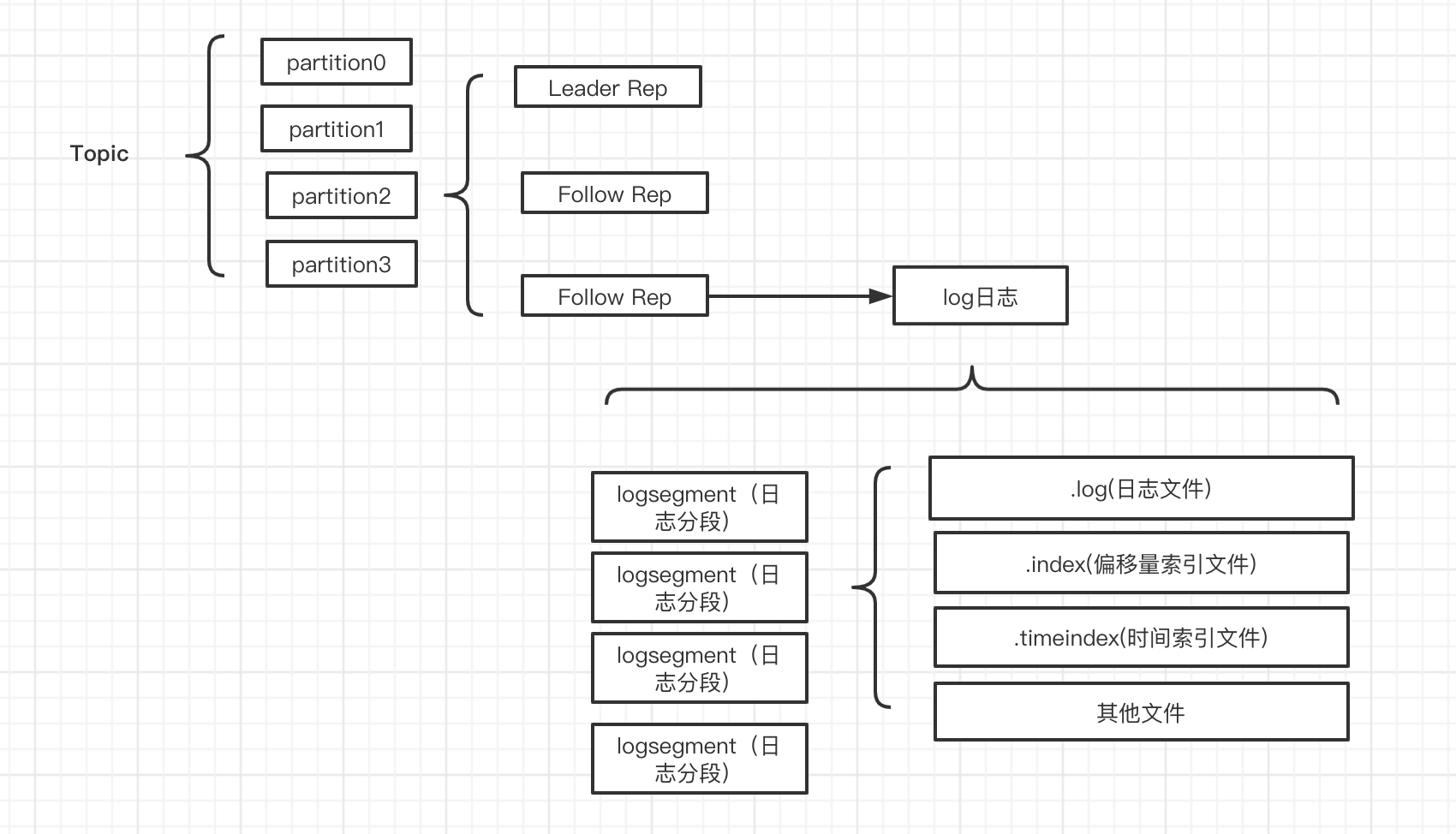
每个Log的命名都是很Topic 和 分区有关系的,假如你的分区名称是“hello-kafka”,而且当前Broker存储的是分区id为2的数据,对应的文件夹名称就是 hello-kafka-2,.
Log下边存储着很多的LogSegment是具体的数据存储的方式,由于Log写入数据的时候只能是顺序写入的,所以只有最后一个LogSegment是可以写入数据的,被称为activeSegmemnt,当Active也被写满的时候,就会创建一个新的Segment称为activeSegement。
LogSegment的组成
- .log
- 存储数据的文件
- .index
- 偏移量索引文件
- .timeindex
- 时间戳索引文件
每个LogSegment 都有一个记住偏移量,用来表示当前LogSegment的第一条消息的offset,这三个文件的前缀都是一样的,名称固定的长度为20位的数字,而开始都是每个日志文件的起始偏移量(baseOffset),其他的位置补零凑够二十位即可,具体如下:

当然每个LogSegment不仅仅包含这些文件,还可能包含“.deleted”,".cleaned",".swap"文件的等等。
我们知道kafka具体存储文件的路径是根据"log.dir或者log.dirs"配置的,所以这些文件都会在这些文件配置位根目录存储,如果是配置的多个根目录,kafka会根据那个路径存储的分区最少进行路由。kafka在创建的时候也会创建五个默认的文件夹,具体如下标红部分所示,而kafka的内部主题_consumer_offsets 也会创建对应的log文件。