

在拿到一份数据准备做挖掘建模之前,首先需要进行初步的数据探索性分析,对数据探索性分析之后要先进行一系列的数据预处理步骤。因为拿到的原始数据存在不完整、不一致、有异常的数据,而这些“错误”数据会严重影响到数据挖掘建模的执行效率甚至导致挖掘结果出现偏差,因此首先要数据清洗。数据清洗完成之后接着进行或者同时进行数据集成、转换、归一化等一系列处理,该过程就是数据预处理。一方面是提高数据的质量,另一方面可以让数据更好的适应特定的挖掘模型,在实际工作中该部分的内容可能会占整个工作的70%甚至更多。
系列文章
第1章 Pandas基础操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第2章 精通pandas索引操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第3章 Pandas 分组(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第4章 精通pandas变形操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第5章 精通pandas合并操作(使用pandas进行数据分析,从小白逆袭大神,你会了吗?)
第6章 缺失数据
在接下来的两章中,会接触到数据预处理中比较麻烦的类型,即缺失数据和文本数据(尤其是混杂型文本)
Pandas在步入1.0后,对数据类型也做出了新的尝试,尤其是Nullable类型和String类型,了解这些可能在未来成为主流的新特性是必要的
import pandas as pd
import numpy as np
df = pd.read_csv('data/table_missing.csv')
df.head()
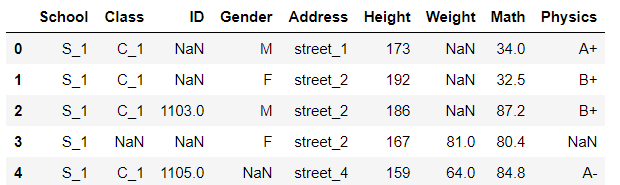
一、缺失观测及其类型
1. 了解缺失信息
(a)isna和notna方法
对Series使用会返回布尔列表
df['Physics'].isna().head()

df['Physics'].notna().head()

df.isna().head()
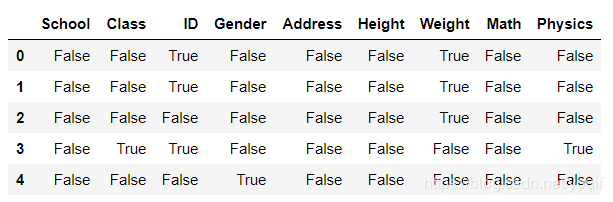
df.isna().sum()
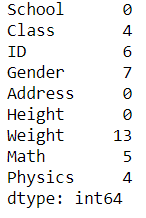
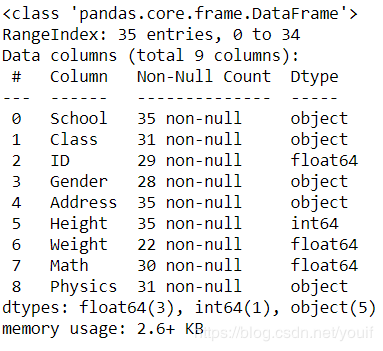
df.info()
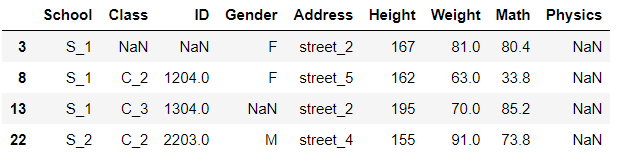
以最后一列为例,挑出该列缺失值的行
df[df['Physics'].isna()]
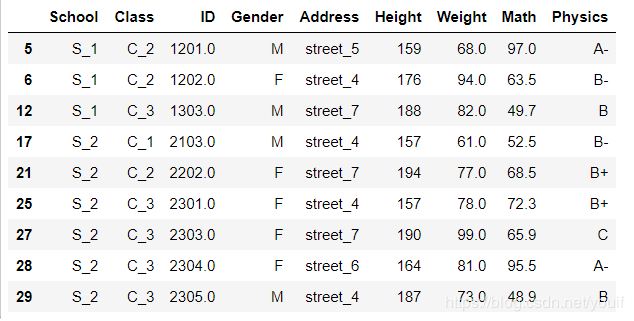
使用all就是全部非缺失值,如果是any就是至少有一个不是缺失值
df[df.notna().all(1)]
2. 三种缺失符号
(a)np.nan
np.nan是一个麻烦的东西,首先它不等与任何东西,甚至不等于自己

在用equals函数比较时,自动略过两侧全是np.nan的单元格,因此结果不会影响
df.equals(df)
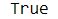
pd.Series([1,np.nan,3],dtype='bool')

s = pd.Series([True,False],dtype='bool')
s[1]=np.nan
s

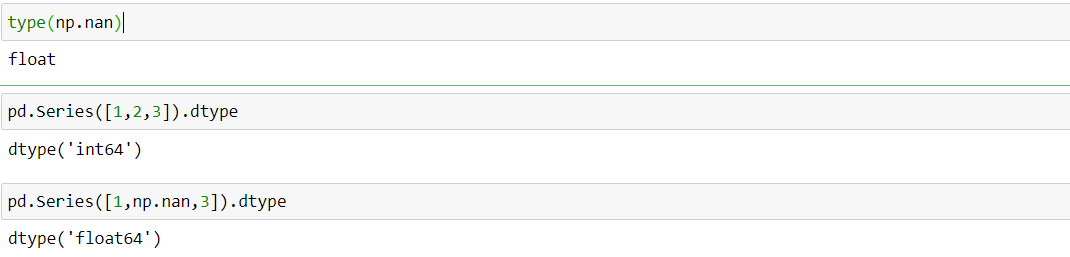
在所有的表格读取后,无论列是存放什么类型的数据,默认的缺失值全为np.nan类型
因此整型列转为浮点;而字符由于无法转化为浮点,因此只能归并为object类型('O'),原来是浮点型的则类型不变
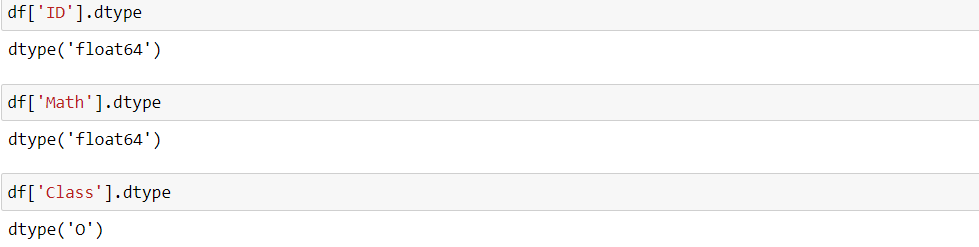
None比前者稍微好些,至少它会等于自身
None == None
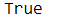
pd.Series([None],dtype='bool')

s = pd.Series([True,False],dtype='bool')
s[0]=None
s

type(pd.Series([1,None])[1])
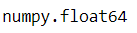
type(pd.Series([1,None],dtype='O')[1])

pd.Series([None]).equals(pd.Series([np.nan]))
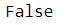
NaT是针对时间序列的缺失值,是Pandas的内置类型,可以完全看做时序版本的np.nan,与自己不等,且使用equals是也会被跳过
s_time = pd.Series([pd.Timestamp('20120101')]*5)
s_time
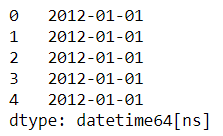
s_time[2] = None
s_time
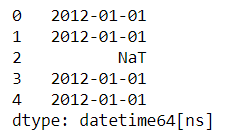
s_time[2] = np.nan
s_time
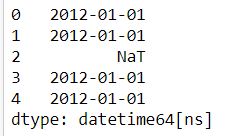
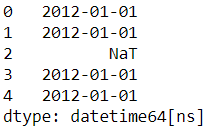
s_time[2] = pd.NaT
s_time
type(s_time[2])
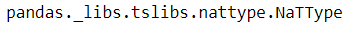
s_time[2] == s_time[2]
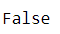
s_time.equals(s_time)

s = pd.Series([True,False],dtype='bool')
s[1]=pd.NaT
s

3. Nullable类型与NA符号
这是Pandas在1.0新版本中引入的重大改变,其目的就是为了(在若干版本后)解决之前出现的混乱局面,统一缺失值处理方法
"The goal of pd.NA is provide a “missing” indicator that can be used consistently across data types (instead of np.nan, None or pd.NaT depending on the data type)."——User Guide for Pandas v-1.0
官方鼓励用户使用新的数据类型和缺失类型pd.NA
(a)Nullable整形 对于该种类型而言,它与原来标记int上的符号区别在于首字母大写:'Int'
s_original = pd.Series([1, 2], dtype="int64")
s_original
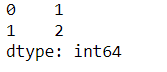
s_new = pd.Series([1, 2], dtype="Int64")
s_new
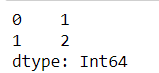
s_original[1] = np.nan
s_original

s_new[1] = np.nan
s_new

s_new[1] = None
s_new

s_new[1] = pd.NaT
s_new

对于该种类型而言,作用与上面的类似,记号为boolean
s_original = pd.Series([1, 0], dtype="bool")
s_original

s_new = pd.Series([0, 1], dtype="boolean")
s_new

s_original[0] = np.nan
s_original

s_original = pd.Series([1, 0], dtype="bool") #此处重新加一句是因为前面赋值改变了bool类型
s_original[0] = None
s_original

s_new[0] = np.nan
s_new

s_new[0] = None
s_new

s_new[0] = pd.NaT
s_new

s = pd.Series(['dog','cat'])
s[s_new]

该类型是1.0的一大创新,目的之一就是为了区分开原本含糊不清的object类型,这里将简要地提及string,因为它是第7章的主题内容
它本质上也属于Nullable类型,因为并不会因为含有缺失而改变类型
s = pd.Series(['dog','cat'],dtype='string')
s

s[0] = np.nan
s

s[0] = None
s

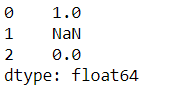
s = pd.Series(["a", None, "b"], dtype="string")
s.str.count('a')
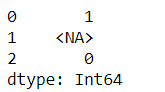
s2 = pd.Series(["a", None, "b"], dtype="object")
s2.str.count("a")
s.str.isdigit()

s2.str.isdigit()

4. NA的特性
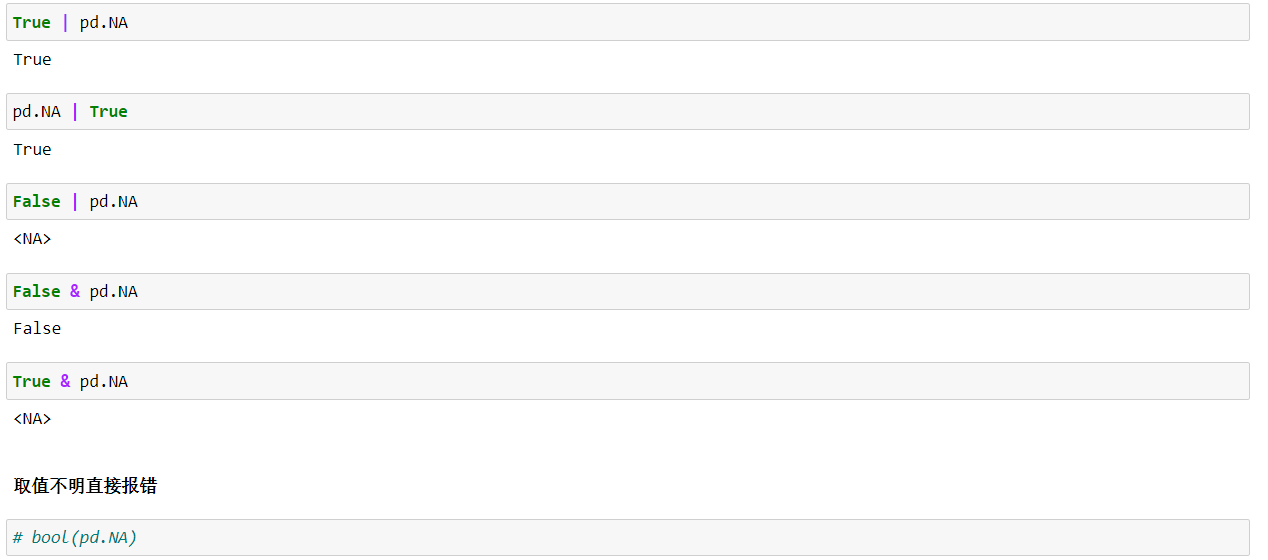
(a)逻辑运算 只需看该逻辑运算的结果是否依赖pd.NA的取值,如果依赖,则结果还是NA,如果不依赖,则直接计算结果
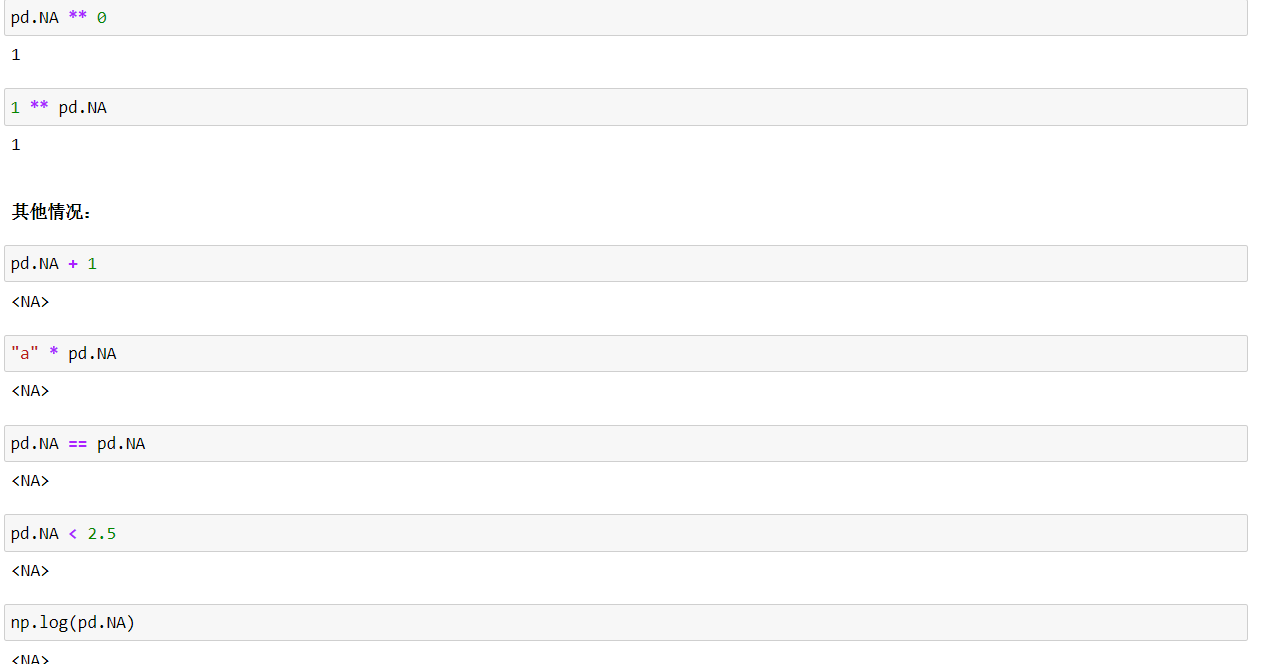
(b)算术运算和比较运算 这里只需记住除了下面两类情况,其他结果都是NA即可
5. convert_dtypes方法
这个函数的功能往往就是在读取数据时,就把数据列转为Nullable类型,是1.0的新函数
pd.read_csv('data/table_missing.csv').dtypes
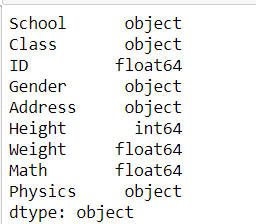
pd.read_csv('data/table_missing.csv').convert_dtypes().dtypes

二、缺失数据的运算与分组
1. 加号与乘号规则
使用加法时,缺失值为0
s = pd.Series([2,3,np.nan,4])
s.sum()
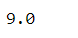
s.prod()
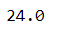
s.cumsum()

s.cumprod()
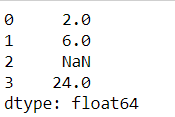
s.pct_change()

2. groupby方法中的缺失值
自动忽略为缺失值的组
df_g = pd.DataFrame({'one':['A','B','C','D',np.nan],'two':np.random.randn(5)})
df_g
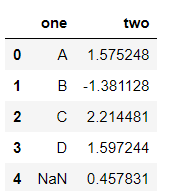
df_g.groupby('one').groups
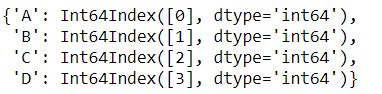
三、填充与剔除
1. fillna方法
(a)值填充与前后向填充(分别与ffill方法和bfill方法等价
df['Physics'].fillna('missing').head()

df['Physics'].fillna(method='ffill').head()

df['Physics'].fillna(method='backfill').head()

df_f = pd.DataFrame({'A':[1,3,np.nan],'B':[2,4,np.nan],'C':[3,5,np.nan]})
df_f.fillna(df_f.mean())
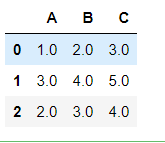
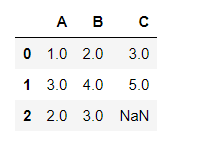
df_f.fillna(df_f.mean()[['A','B']])
2. dropna方法
(a)axis参数
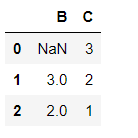
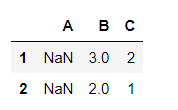
df_d = pd.DataFrame({'A':[np.nan,np.nan,np.nan],'B':[np.nan,3,2],'C':[3,2,1]})
df_d
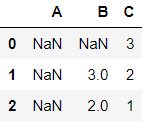
df_d.dropna(axis=0)

df_d.dropna(axis=1)
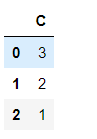
df_d.dropna(axis=1,how='all')
df_d.dropna(axis=0,subset=['B','C'])
四、插值(interpolation)
1. 线性插值
(a)索引无关的线性插值
默认状态下,interpolate会对缺失的值进行线性插值
s = pd.Series([1,10,15,-5,-2,np.nan,np.nan,28])
s

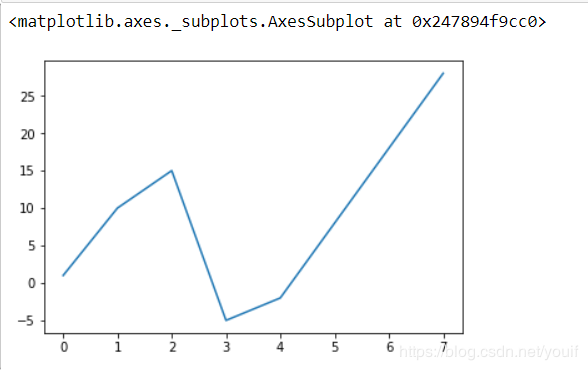
s.interpolate()

s.interpolate().plot()
s.index = np.sort(np.random.randint(50,300,8))
s.interpolate()
#值不变
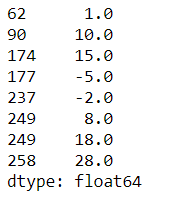
s.interpolate().plot()
#后面三个点不是线性的(如果几乎为线性函数,请重新运行上面的一个代码块,这是随机性导致的)
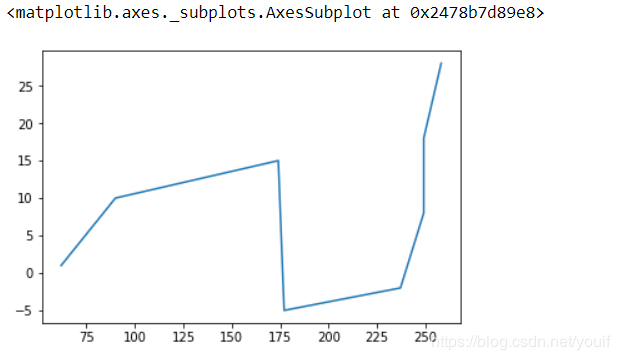
method中的index和time选项可以使插值线性地依赖索引,即插值为索引的线性函数
s.interpolate(method='index').plot()
#可以看到与上面的区别
s_t = pd.Series([0,np.nan,10]
,index=[pd.Timestamp('2012-05-01'),pd.Timestamp('2012-05-07'),pd.Timestamp('2012-06-03')])
s_t
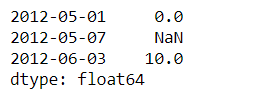
s_t.interpolate().plot()
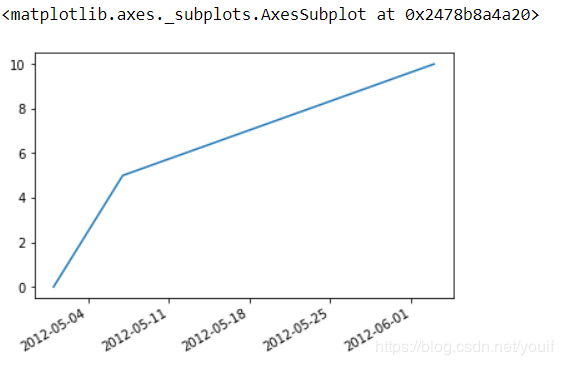
s_t.interpolate(method='time').plot()
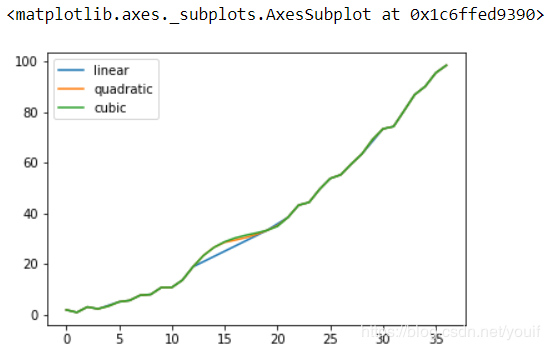
2. 高级插值方法
此处的高级指的是与线性插值相比较,例如样条插值、多项式插值、阿基玛插值等(需要安装Scipy),方法详情请看这里
关于这部分仅给出一个官方的例子,因为插值方法是数值分析的内容,而不是Pandas中的基本知识:
import pandas as pd
import numpy as np
ser = pd.Series(np.arange(1, 10.1, .25) ** 2 + np.random.randn(37))
missing = np.array([4, 13, 14, 15, 16, 17, 18, 20, 29])
ser[missing] = np.nan
methods = ['linear', 'quadratic', 'cubic']
df = pd.DataFrame({m: ser.interpolate(method=m) for m in methods})
df.plot()
3. interpolate中的限制参数
(a)limit表示最多插入多少个
s = pd.Series([1,np.nan,np.nan,np.nan,5])
s.interpolate(limit=2)

s = pd.Series([np.nan,np.nan,1,np.nan,np.nan,np.nan,5,np.nan,np.nan,])
s.interpolatae(limit_direction='backward')
代码和数据地址:github.com/XiangLinPro…
另外博主收藏这些年来看过或者听过的一些不错的常用的上千本书籍,没准你想找的书就在这里呢,包含了互联网行业大多数书籍和面试经验题目等等。有人工智能系列(常用深度学习框架TensorFlow、pytorch、keras。NLP、机器学习,深度学习等等),大数据系列(Spark,Hadoop,Scala,kafka等),程序员必修系列(C、C++、java、数据结构、linux,设计模式、数据库等等)以下是部分截图
更多文章见本原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】即可领取哦。


所有巧合的是要么是上天注定要么是一个人偷偷的在努力。
有收获?希望老铁们来个三连击,给更多的人看到这篇文章
1、给俺点个赞呗,可以让更多的人看到这篇文章,谢谢各位亲。
2、亲们,关注我的原创微信公众号「五角钱的程序员」,我们一起成长,一起学习。一直纯真着,善良着,温情地热爱生活。关注回复【电子书】有很多资源哦。
给大家推荐一个Github,上面非常非常多的干货:github.com/XiangLinPro…
Whatever I believed, I did; and whatever I did, I did with my whole heart and mind.
凡是我相信的,我都做了;凡是我做了的事,都是全身心地投入去做的。
关于Datawhale
Datawhale是一个专注于数据科学与AI领域的开源组织,汇集了众多领域院校和知名企业的优秀学习者,聚合了一群有开源精神和探索精神的团队成员。Datawhale以“for the learner,和学习者一起成长”为愿景,鼓励真实地展现自我、开放包容、互信互助、敢于试错和勇于担当。同时Datawhale 用开源的理念去探索开源内容、开源学习和开源方案,赋能人才培养,助力人才成长,建立起人与人,人与知识,人与企业和人与未来的联结。
2020.5.22于城口
