

一、背景
近年来,随着万物互联时代的到来和5G网络的普及,网络边缘的设备数量和其产生的数据量都急剧增长。根据相关数据预测,到2021年,全球范围内将有超过500亿的终端设备,这些设备每年产生的数据总量将达到847 ZB,其中约有10%的数据需要进行计算处理。另外,智能终端设备已成为人们生活的一部分,人们对服务质量的要求有了进一步提升。在这种情况下,以云计算为代表的集中式处理模式将无法高效地处理边缘设备产生的数据,无法满足人们对服务质量的需求。这时,边缘计算的出现正好解决了这一系列问题,边缘计算设备处理了部分产生的临时数据,不再需要将全部数据上传至云端,只需要传输有价值的数据,这极大地减轻了网络带宽的压力,且减少了对计算存储资源的需求。其次,在靠近数据源端进行数据处理,能够大大地减少系统时延,提高服务的响应时间。而以端边云为架构的通信网络也将成为未来的趋势。而通过人工智能对计算卸载任务进行智能化调度也已经成为新的研究方向。
二、卸载计算
本文将以边端协同的机器人人脸识别为具体场景,详细展开描述深度强化学习如何帮助智能终端进行计算卸载到边缘服务器。人脸识别是人工智能领域应用最广泛的场景之一,而人脸识别的精确度不仅与深度神经网络模型的复杂度相关也对计算设备的规格要求比较高,这个时候我们就会去思考为什么不将一些大型的深度神经网络模型部署在边缘服务器,而终端设备仅部署一些轻量级模型,从而不仅可以降低终端设备任务计算成本,同时提高人脸识别精度。到这里就涉及到另外一个问题:什么样的计算任务在何时以及何地才需要进行任务卸载到边缘服务器计算呢? 因篇幅原因,我将分为上下两篇来研究深度强化学习如何实现机器人的人脸识别卸载计算问题,在本篇中将先介绍模拟环境的软件配置、深度强化学习的建模思想以及演示结果,在下一篇中将详细介绍DRL模块的代码。
三、实验环境
1.我们的模拟环境是以机器人的人脸识别作为切入点,在这个过程中,我们需要用到的硬件环境包括一台jetson TX2、MEC服务器分别作为智能终端与边缘服务器。软件环境 包括ubuntu系统、Tensorflow 2.0、python3以及keras等等。因为涉及到深度强化学习,我们这里默认读者是已经具有一定机器学习的基础了,在此就不再赘述相关概念,如果有不清楚的读者可以自行查阅相关资料。 如上文中所提到的,在本次实验中我们将利用深度神经网络模型OpenFace来进行人脸识别,而智能终端设备上面将部署openface_nn4.small2.v1.t7(轻量级),边缘服务器上部署openface_nn4.v2.t7(重量级)。接着就是卸载计算的核心,卸载模型的构建、训练以及交叉测试,在本篇中我们先简单阐述一下模型构建的思想,在下一篇文章中会具体介绍代码。深度强化学习是一种端对端的感知与控制系统,具有很强的通用性.其学习过程可以描述为: (1)在每个时刻agent与环境交互得到一个高维度的观察,并利用DL方法来感知观察,以得到具体的状态特征表示; (2)基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作; (3)环境对此动作做出反应,并得到下一个观察.通过不断循环以上过程,最终可以得到实现目标的最优策略。
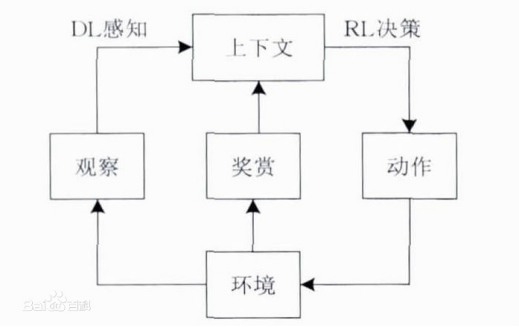
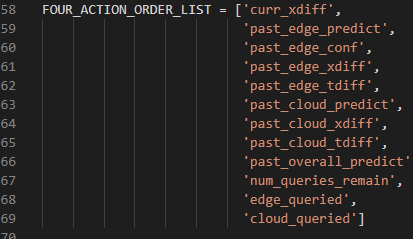
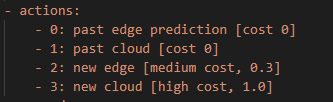
因此,我们发现深度强化学习建模的关键首先是定义状态空间以及动作空间。本文的实验中分别部署了终端模型以及边缘端模型,智能体在训练的过程中会有四个动作包括0:查询终端缓存中的数据;1:查询终端模型计算出来的数据;2:查询边缘服务器缓存中的数据;3:查询边缘模型计算出来的数据,这四个动作组成了动作空间,可观测到的状态空间包括主要分为三个方面包括过去的预测值以及当前的查询结果还有查询预算的限额等,具体如下:

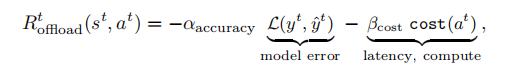
四、实验结果
接下来让我们看一下实验最终达到的效果
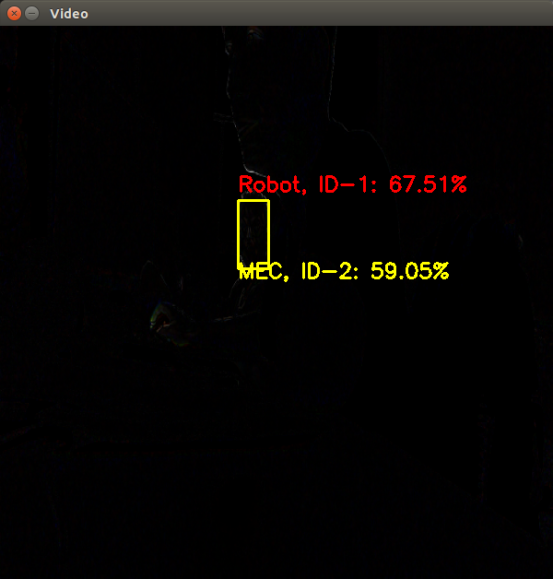
在下一篇文章中,我们会继续介绍如何通过深度强化学习来实现机器人与边缘服务器MEC中的卸载计算。
