

前言
最近在看 JVM 与高并发相关书籍,发现两本书都提到了指令重排序优化,但都没对指令重排序优化进一步解释,后面在查找了相关资料后才对指令重排序有个整体的了解,此篇文章对该部分知识做一个整理,希望对大家有所帮助
什么是指令重排序
在讲指令重排序之前,先看下面代码,试想一下程序的运行结果
public class NoVisibility {
private static boolean ready;
private static int number;
private static class ReaderThread extends Thread {
@Override
public void run() {
while (!ready)
Thread.yield();
System.out.println(number);
}
}
public static void main(String[] args) {
new ReaderThread().start();
number = 42;
ready = true;
}
}
NoVisibility 可能会持续循环下去,因为读线程可能永远都看不到 ready 的值。一种更奇怪的现象是,NoVisibility 可能会输出 0,因为读线程可能看到了写入 ready 的值,但却没有看到写入 number 的值。造成这种现象的原因就是指令重排序(Reordering)
指令重排序是指编译器/处理器对用户执行代码的一种优化手段,允许其将多条指令不按程序定义的顺序执行,而是可以以自定义的一些规则进行重排序,以达到更高的执行效率
编译器重排序
编译器重排序是指编译器在不改变单线程语义的情况下,可以重新安排语句(说成指令更加准确,但是为了方便理解,这里直接说成语句)的执行顺序,尽可能减少寄存器的读取、存储次数,充分复用寄存器的存储值
举个例子,假设第一条指令计算一个值赋值给变量A并存放在寄存器中,第二条指令与A无关,但需要占用寄存器(假设刚好占用A所在的寄存器),第三条指令使用A的值,且与第二条指令无关。那么如果按照顺序一致性模型,A在第一条指令执行后放入寄存器,第二条指令执行时A不再存在寄存器中,第三条指令执行时,A又重新被读入寄存器中,整个过程中A的值没有发生变化
这时候,编译器通常会交换第二条和第三条指令的位置,这样在执行完第一条指令的时候A存在与寄存器中,再执行第三条指令时,就可以直接使用寄存器中的值,避免了重复读取的开销
另一种常见的编译器优化:在循环读取变量的时候,为提高读存取速度,编译器会把变量读取到一个寄存器中,以后再使用该变量的时候,就直接从寄存器中读取,不再从内存中读取。这样虽然能减少不必要的内存访问,但却带来了新的并发问题,如果别的线程修改了变量的值,由于寄存器中的值一直没有发生改变,就可能导致循环无法正确结束。可以使用同步锁或 validate 关键字解决该问题
处理器重排序
指令并行重排序
编译器和处理器都可能会对操作做重排序,但是必须遵循数据依赖关系,即不能改变存在数据依赖关系的两个操作的执行顺序,如两个操作访问同一个变量,第二个操作的执行依赖上一个操作的执行结果,这时候如果改变两条语句的执行顺序,就会改变程序的语义
需要特别注意的是,这里指的依赖关系仅仅指在单线程内
举个例子
class Demo {
int a = 0;
boolean flag = false;
public void write() {
a = 1; // 1
flag = true; // 2
}
public void read() {
if (flag) { // 3
int i = a * a; // 4
}
}
}
操作 1 跟操作 2 没有依赖关系,编译器或处理器可以对这两个操作进行重排序,同样的,操作 3 跟操作 4 也没有依赖关系,编译器或处理器也可以对这两个操作进行重排序
- 当操作 1 跟操作 2 重排序时
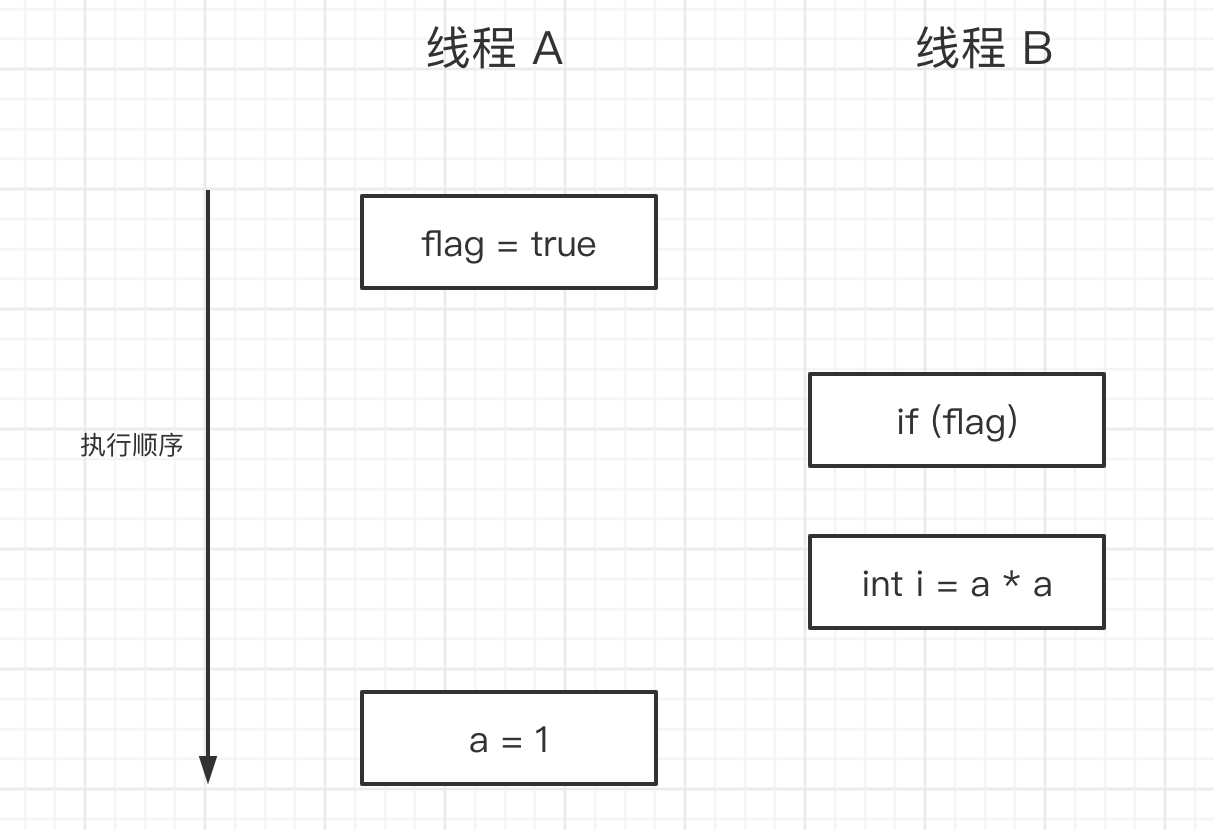
如图,操作 1 跟操作 2 被重排序了,程序执行时,线程 A 首先将 flag 设置为 true,线程 B 在判断 flag 为 true,计算 i 的值,此时 A 的值依旧是 0,还没有被线程 A 写入,这里的多线程程序语义被重排序破坏了
- 指令 3 和指令 4 重排序
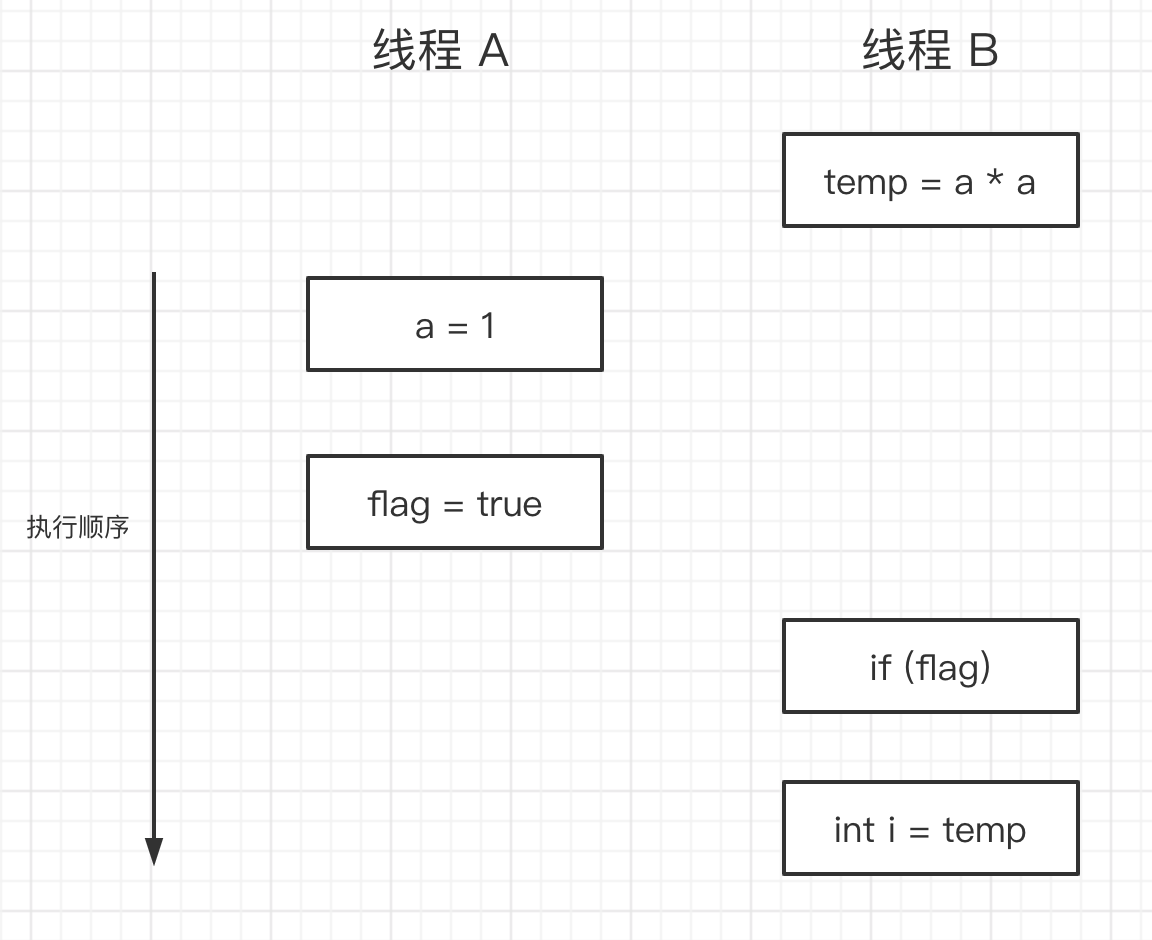
在程序中,操作 3 和操作 4 存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。
执行线程 B 的处理器可以提前读取并计算 a * a,然后把计算结果临时保存到一个名为 重排序缓冲(reorder buffer ROB) 的硬件缓存中。当接下来操作 3 的条件判断为真时,就把该计算结果写入变量 i 中
可以看到,对操作 3 和操作 4 进行重排序,同样破坏了多线程程序的语义
指令乱序重排序
从硬件架构上讲,指令重排序是指处理器采用了允许将多条指令不按程序规定的顺序分开发送给各个相应的电路单元进行处理。比如,CPU有一个加法器和一个除法器,那么,一条加法指令跟一条除法指令就有可能由这两个单元并行执行,如果是两条加法指令,就只能串行工作
这样一来,乱序可能就产生了。比如:一条加法指令原本出现在一条除法指令的后面,但是由于除法的执行时间很长,在它执行完之前,加法可能先执行完了。再比如两条访存指令,可能由于第二条指令命中了cache而导致它先于第一条指令完成。一般情况下,指令乱序并不是CPU在执行指令之前刻意去调整顺序。CPU总是顺序的去内存里面取指令,然后将其顺序的放入指令流水线。但是指令执行时的各种条件,指令与指令之间的相互影响,可能导致顺序放入流水线的指令,最终乱序执行完成。这就是所谓的 “顺序流入,乱序流出”
举个例子:
a++;
a = f(b);
c++;
由于a=f(b)这条指令依赖于前一条指令a++的执行结果,所以在执行a=f(b)时,必须确保a++已经成功执行并返回,假设a++是一条耗时指令,那么就会导致第二条指令因在等待第一条指令的执行结果而产生阻塞等待
像这样有依赖关系的指令如果挨得很近,后一条指令必定会因为等待前一条执行的结果,而在流水线中阻塞很久,占用流水线的资源。而编译器的重排序,作为编译优化的一种手段,则试图通过指令重排将这样的两条指令拉开距离,以至于后一条指令进入CPU的时候,前一条指令结果已经得到了,那么也就不再需要阻塞等待了。比如,将指令重排序为:
a++;
c++;
a=f(b);
参考:
猿码道:《啃碎并发(11):内存模型之重排序》
童云兰等译:《Java并发编程实战》

