今日内容
1.redis
1.概念
2.下载安装
3.命令操作
1.数据结构
4.持久化操作
5.使用Java客户端操作redis
* redis中文网中有教程。
一、Redis
1.概念:redis是一款高性能的NOSQL系列的非关系型数据库。
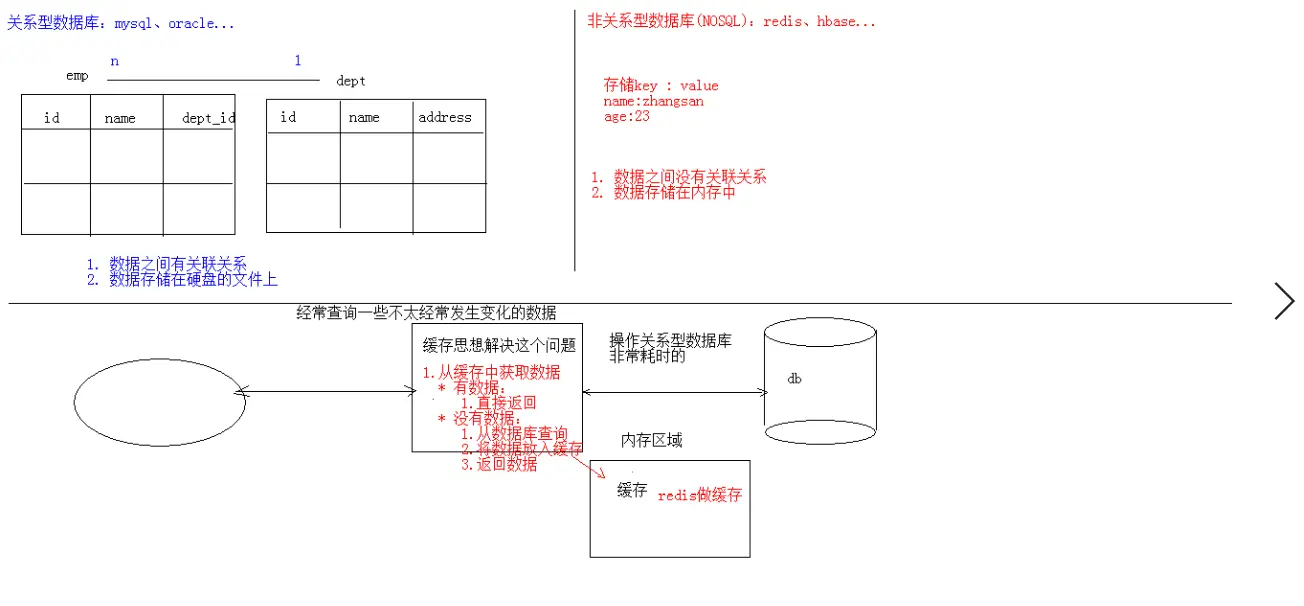
缓存的选择:
1.在内存中开辟一片空间,比如一个map集合。但是map集合只能让当前项目下有缓存。
2.将来我们需要做一些分布式的部署有多台电脑,map集合就显然不合适了。就可以采
用一些非关系型的数据库来做缓存。
因为非关系型的数据库,它的数据是存储在内存中的,而且它可以部署独立的机器。
我们可以让一个机器的所有内存都被redis数据独占,而map是运行在JAVA虚拟机里面,
虚拟机开启只能固定分配一些内存,分的内存也比较小。
所以现今的互联网应用中,redis这种非关系型(NOSQL)数据库来做缓存是很多的。
1.1.什么是NOSQL
NoSQL(NoSQL = Not Only SQL),意即“不仅仅是SQL”,是一项全新的数据库理念,
泛指非关系型的数据库。随着互联网web2.0网站的兴起,传统的关系数据库在应付
web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不
从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了
非常迅速的发展。NoSQL数据库的产生就是为了解决大规模数据集合多重数据种类带
来的挑战,尤其是大数据应用难题。
1.1.1. NOSQL和关系型数据库比较
优点:
1)成本:nosql数据库简单易部署,基本都是开源软件,不需要像使用oracle
那样花费大量成本购买使用,相比关系型数据库价格便宜。
2)查询速度:nosql数据库将数据存储于缓存之中,关系型数据库将数据存
储在硬盘中,自然查询速度远不及nosql数据库。
3)存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形
式等等,所以可以存储基础类型以及对象或者是集合等各种格式,而数据库
则只支持基础类型。
4)扩展性:关系型数据库有类似join这样的多表查询机制的限制导致扩展很艰难。
缺点:没有统一的标准。两个NOSQL数据库之间天差地别
1)维护的工具和资料有限,因为nosql是属于新的技术,不能和关系型数据库10
几年的技术同日而语。
2)不提供对sql的支持,如果不支持sql这样的工业标准,将产生一定用户的
学习和使用成本。
3)不提供关系型数据库对事务的处理。
1.1.2. 非关系型数据库的优势:
1)性能NOSQL是基于键值对的,可以想象成表中的主键和值的对应关系,而且
不需要经过SQL层的解析,所以性能非常高。
2)可扩展性同样也是因为基于键值对,数据之间没有耦合性,所以非常容易
水平扩展。
1.1.3. 关系型数据库的优势:
1)复杂查询可以用SQL语句方便的在一个表以及多个表之间做非常复杂的数据查询。
2)事务支持使得对于安全性能很高的数据访问要求得以实现。对于这两类数
据库,对方的优势就是自己的弱势,反之亦然。
1.1.4. 总结
关系型数据库与NoSQL数据库并非对立而是互补的关系,即通常情况下使用关
系型数据库,在适合使用NoSQL的时候使用NoSQL数据库,
让NoSQL数据库对关系型数据库的不足进行弥补。
** 一般会将数据存储在关系型数据库中,在nosql数据库中备份存储关系型数据
库的数据
1.2.主流的NOSQL产品
• 键值(Key-Value)存储数据库
相关产品: Tokyo Cabinet/Tyrant、Redis、Voldemort、Berkeley DB
典型应用: 内容缓存,主要用于处理大量数据的高访问负载。
数据模型: 一系列键值对
优势: 快速查询
劣势: 存储的数据缺少结构化
• 列存储数据库
相关产品:Cassandra, HBase, Riak
典型应用:分布式的文件系统
数据模型:以列簇式存储,将同一列数据存在一起
优势:查找速度快,可扩展性强,更容易进行分布式扩展
劣势:功能相对局限
• 文档型数据库
相关产品:CouchDB、MongoDB
典型应用:Web应用(与Key-Value类似,Value是结构化的)
数据模型: 一系列键值对
优势:数据结构要求不严格
劣势: 查询性能不高,而且缺乏统一的查询语法
• 图形(Graph)数据库
相关数据库:Neo4J、InfoGrid、Infinite Graph
典型应用:社交网络
数据模型:图结构
优势:利用图结构相关算法。
劣势:需要对整个图做计算才能得出结果,不容易做分布式的集群方案。
1.3 什么是Redis
Redis是用C语言开发的一个开源的高性能键值对(key-value)数据库,官方提供
测试数据,50个并发执行100000个请求,读的速度是110000次/s,写的速度是81000
次/s ,且Redis通过提供多种键值数据类型来适应不同场景下的存储需求,目前为
止Redis支持的键值数据类型如下:
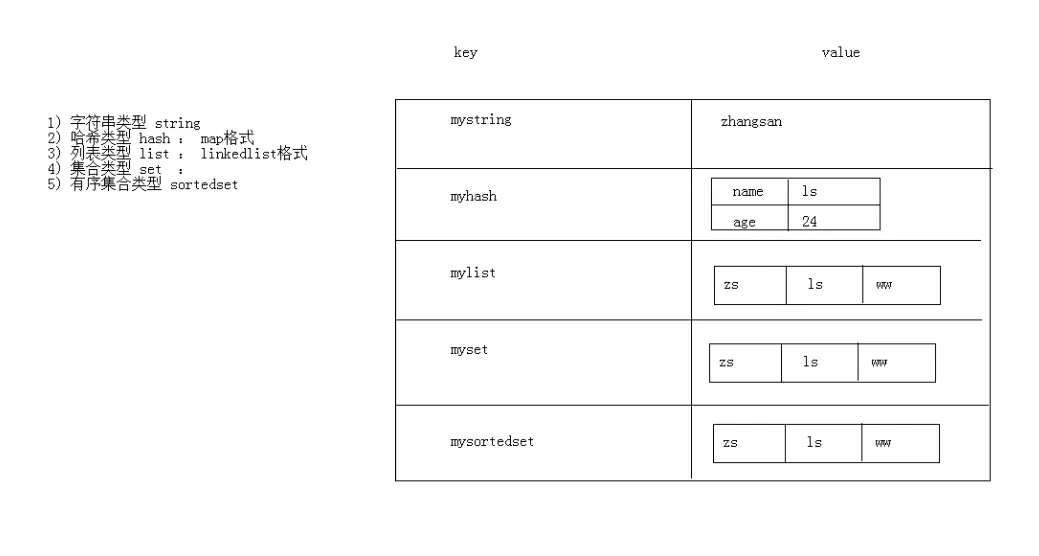
1) 字符串类型 string
2) 哈希类型 hash
3) 列表类型 list
4) 集合类型 set
5) 有序集合类型 sortedset
1.3.1 redis的应用场景
• 缓存(数据查询、短连接、新闻内容、商品内容等等)
• 聊天室的在线好友列表
• 任务队列。(秒杀、抢购、12306等等)
• 应用排行榜
• 网站访问统计
• 数据过期处理(可以精确到毫秒)
• 分布式集群架构中的session分离
2. 下载安装
1. 官网:https://redis.io
2. 中文网:http://www.redis.net.cn/
3. 解压直接可以使用:
* redis.windows.conf:配置文件
* redis-cli.exe:redis的客户端
* redis-server.exe:redis服务器端
* 先打开服务器端,再打开客户端。
3.命令存储:主要进行数据的存储和获取
1.redis的数据结构:(列表和集合都可以看做线性表)
* redis存储的是:key,value格式的数据,其中key都是字符串,value值有5种不同的
数据结构:
1).字符串类型 String
2).哈希类型 hash : map格式 key:(key:value)
3).列表类型 list : linkedlist格式
4).集合类型 set : hashset 不允许重复元素
5).有序集合类型 sortedset :不允许重复元素,且有序
* 其实无论何种结构:都是String类型的字符串构成的。
2.字符串类型 string
1.存储:set key value
2.获取:get key
3.删除:del key
3.哈希类型 hash(不会有重复的键值对:直接覆盖)
* hash存储的是map格式,key -- map; map中是:field -- value
1.存储:hset key field value
2.获取:
* hget key field:获取指定的field字段对应的值
* hgetall key:获取所有的field和value
3.删除:hdel key field
```
hset myhash username lisi
hset myhash password 123
hget myhash username
"lisi"
hgetall myhash
1) "username"
2) "lisi"
3) "password"
4) "123"
hdel myhash username
```
4.列表类型 list:允许重复元素;可以添加一个元素到列表的头部(左边)或者尾部(右边)
所以元素是有顺序的。
1.添加
1.lpush key value:从列表的左边加入
2.rpush key value:将元素加入到列表右边
2.获取:
* lrange key start end:范围获取
3.删除:
* lpop key:删除列表最左边一个元素,并返回
* rpop key:删除列表最右边一个元素,并返回
```
lpush mylist a
lpush mylist b
rlpush mylist c
lrange mylist 0 -1 //获取所有
1) "b"
2) "a"
3) "c"
lpop mylist
rpop mylist
```
5.集合类型 set:不允许重复元素,而且存入的元素没有特定书序
1.存储:sadd key value
2.获取:smembers key:获取set集合中所有元素
3.删除:srem key value:删除set集合中的某个元素
```
sadd myset a
sadd myset b
sadd myset c
sadd myset d
smembers myset
1) "c"
2) "d"
3) "a"
4) "b"
srem myset a
```
6.有序集合类型 sortedset :是string类型元素的集合,不允许重复元素,且有序。
不同的是每个元素都会关联一个double类型的分数。
redis正是通过分数来为集合中的成员进行从小到大的排序。
1.存储:zadd key score value
2.获取:zrange key start end
3.删除:zrem key value
```
zadd mysort 60 zhangsan
zadd mysort 50 lisi
zadd mysort 80 wangwu
zrange mysort 0 -1
1) "lisi"
2) "zhangsan"
3) "wangwu"
zrange mysort 0 -1 withscores
1) "lisi"
2) "50"
3) "zhangsan"
4) "60"
5) "wangwu"
6) "80"
```
7.通用命令
1.keys *:查询所有的键
2.type key:获取键对应的value的类型
3.del key:删除指定的key value
```
keys *
1) "myhash"
2) "username"
3) "mylist"
4) "myset"
5) "mysort"
type username
string
type myhash
hash
```
4.持久化
1.redis是一个内存数据库,当redis重启或者电脑重启后,数据就会丢失。我们可以将redis
中的数据持久化保存到硬盘的文件中。
2.redis持久化方式
1.RDB:默认方式,不需要进行配置,默认就是用这种机制。
* 在一定的间隔时间中,检测key的变化情况。然后持久化数据
* 对性能影响小,但是对于频繁操作的话有的数据来不及存储。
1.编辑redis.windows.conf配置文件
save 900 1 : 900s之后,只要有1个key发生了改变,就持久化一次
# after 900 sec (15 min) if at least 1 key changed
save 300 10 : 300s之后,至少有10个key发生了改变,就持久化一次
# after 300 sec (5 min) if at least 10 keys changed
save 60 10000 : 60s之后,至少有10000个key发生了改变,就持久化一次
# after 60 sec if at least 10000 keys changed
* 会生成appendonly.aof文件,将数据存到安装目录下的dump.rdb文件中
2.重新启动redis服务器,并指定配置文件名称。
在(相应目录下)命令行里面敲下:redis-server.exe redis.windows.conf
打开redis服务器端。
2.AOF:日志记录方式。
* 可以记录每一条命令的操作。可以每一次命令操作后来持久化数据。
* 对性能影响大。
1.编辑redis.windows.conf配置文件
appendonly no ---> appendonly yes
appendfsync always:每一次操作都进行持久化。
appendfsync everysec:每隔一秒进行一次持久化。
appendfsync no:不进行持久化。
2.重新启动redis服务器,并指定配置文件名称。
在(相应目录下)命令行里面敲下:redis-server.exe redis.windows.conf
打开redis服务器端。
* 会生成appendonly.aof文件,将数据持久化到appendonly.aof文件中。
5.使用Java客户端 jedis
* jedis:一款java操作redis数据库的工具。
类似于JDBC,通过导入一个mysql-connect.jar包,就可以用JDBC的代码(程序)来操作
MySql数据库。
* 使用步骤:
1.下载jedis的jar包
commons-pool2-2.3.jar //连接池的jar包
jedis-2.7.0.jar
2.使用
* 快速入门
```
public void test1(){
//1.获取连接:
// 主机参数:localhost。因为连接的是自己的。如果要连别人的redis时,就指定别人的id地址以及端口
Jedis jedis = new Jedis("localhost", 6379);
//2.操作
jedis.set("username", "zhangsan");
//3.关闭连接
jedis.close();
}
```
5.2 jedis操作各种redis中的数据结构
1).字符串类型 String
jedis.set()
jedis.get()
jedis.setex()
```
public void test2(){
// 如果使用空参构造:默认值是localhost 6379。
//所以如果我们连本机的这么一个redis服务器,那么我们可以空参
Jedis jedis = new Jedis();
jedis.set("username", "zhangsan");
String username = jedis.get("username");
System.out.println(username);
//将activecode:hehe一对键值存入redis,并且20s后自动删除-----可以操作短信验证码
jedis.setex("activecode", 20, "hehe");
jedis.close();
}
```
2).哈希类型 hash : map格式 key:(key:value)
jedis.hset()
jedis.hget()
jedis.hgetAll()
```
public void test3(){
Jedis jedis = new Jedis();
//存储hash
jedis.hset("user", "name","lisi");
jedis.hset("user", "age","23");
jedis.hset("user", "gender","male");
//获取hash
String name = jedis.hget("user", "name");
System.out.println(name);
//获取hash的所有的键值对数据
Map<String, String> user = jedis.hgetAll("user");
//遍历集合:keyset
Set<String> keySet = user.keySet();
for (String key : keySet) {
//获取value
String value = user.get(key);
System.out.println(key+":"+value);
}
//3.关闭连接
jedis.close();
}
```
3).列表类型 list : linkedlist格式
lpush/lpop
rpush/rpop
jedis.lrange("mylist", 0, -1);
```
public void test4(){
//1.获取连接:
Jedis jedis = new Jedis();
//2.操作
//存储list
jedis.lpush("mylist", "a", "b", "ccc", "dd");
jedis.rpush("mylist", "zzz", "yyy", "x", "w");
//list范围获取
List<String> mylist = jedis.lrange("mylist", 0, -1);
System.out.println(mylist);
//list的弹出
String element1 = jedis.lpop("mylist");
String element2 = jedis.rpop("mylist");
//3.关闭连接
jedis.close();
}
```
4).集合类型 set : hashset 不允许重复元素
sadd
jedis.smembers("myset");
```
public void test5(){
//1.获取连接:
Jedis jedis = new Jedis();
//2.操作
//存储set
jedis.sadd("myset", "java", "php", "c++");
//获取set
Set<String> myset = jedis.smembers("myset");
System.out.println(myset);
//3.关闭连接
jedis.close();
}
```
5).有序集合类型 sortedset :不允许重复元素,且有序
zadd
jedis.zrange("mysortedset", 0, -1)
```
public void test6(){
//1.获取连接:
Jedis jedis = new Jedis();
//2.操作
//存储sortedset
jedis.zadd("mysortedset", 100, "java");
jedis.zadd("mysortedset", 90, "c++");
jedis.zadd("mysortedset", 80, "python");
//获取sortedset
Set<String> mysortedset = jedis.zrange("mysortedset", 0, -1);
System.out.println(mysortedset);
//3.关闭连接
jedis.close();
}
```
6.Jedis连接池:JDBC的连接池时第三方提供的,Jedis连接池是自带的(JedisPool)
jedis:一款java操作redis数据库的工具。我们上面使用jedis,通过导入jar包,就可以
使用jedis的代码来操作redis数据库。
那么为什么还要用连接池呢?这样我们对于jedis的连接就可以更好的服用和管理。
* 使用:
1.创建JedisPool连接池对象
2.调用方法:getResource()方法获取Jedis连接
```
public void test7(){
//0.创建一个配置对象
JedisPoolConfig config = new JedisPoolConfig();
config.setMaxTotal(50); //最大允许连接数
config.setMaxIdle(10); //最大的空闲连接
/*
1.创建Jedis连接池对象
可以用空参的构造方法,JedisPool()有一些默认的配置参数,可以不修改,默认使用。
也可以传一些配置参数
*/
JedisPool jedisPool = new JedisPool(config, "localhost", 6379);
//2.获取连接
Jedis jedis = jedisPool.getResource();
//3.使用
jedis.set("hehe", "heihei");
//4.关闭 归还到连接池中
jedis.close();
}
```
6.2 JedisPool工具类
介绍完jedis连接池JedisPool基本使用之后,我们要对JedisPool抽取一个工具类。
因为如果这些参数都需要我们自己指定的话,不便于我们以后修改,耦合度比较高。我
们可以把参数抽取到一个配置文件里面,将来读取配置文件加载这些参数的配置,这样
更合理一些。
既然是工具类,里面的方法都会定义为静态的
* 相关代码
```
public class JedisPoolUtils {
private static JedisPool jedisPool;
static{
//读取配置文件---类加载器
InputStream is = JedisPoolUtils.class.getClassLoader().
getResourceAsStream("jedis.properties");
//创建Properties对象
Properties pro = new Properties();
//关联文件
try {
pro.load(is);
} catch (IOException e) {
e.printStackTrace();
}
//获取数据,设置到JedisPoolConfig中
JedisPoolConfig config = new JedisPoolConfig();
//读取一个设置一个:参数是int
config.setMaxTotal(Integer.parseInt(pro.getProperty("maxTotal")));
config.setMaxIdle(Integer.parseInt( pro.getProperty("maxIdle")));
//初始化JedisPool:
//JedisPool(GenericObjectPoolConfig poolConfig, String host, int port)
jedisPool = new JedisPool(config, pro.getProperty("host"),
Integer.parseInt(pro.getProperty("port")));
}
/**
* 获取连接的方法
*/
//既然是工具类,里面的方法都会定义为静态的
public static Jedis getJedis(){
return jedisPool.getResource();
}
}
```
二.案例
1.案例需求:
1. 提供index.html页面,页面中有一个省份 下拉列表
2. 当 页面加载完成后 发送ajax请求,加载所有省份
2.环境搭建
1.数据库:
```
CREATE DATABASE day23; -- 创建数据库
USE day23; -- 使用数据库
CREATE TABLE province( -- 创建表
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR(20) NOT NULL
);
-- 插入数据
INSERT INTO province VALUES(NULL,'北京');
INSERT INTO province VALUES(NULL,'上海');
INSERT INTO province VALUES(NULL,'广州');
INSERT INTO province VALUES(NULL,'陕西');
```
2.jar包:都放在web/WEB-INF/lib目录下
Json解析器:jackson序列化json的。将返回给页面的JAVA对象转成Json对象
jackson-annotations-2.2.3.jar
jackson-core-2.2.3.jar
jackson-databind-2.2.3.jar
客户端会发送ajax请求,JQuery依赖的js文件导入
注意:这两文件是放在web/js目录下
jquery-3.3.1.js
jquery-3.3.1.min.js
连接池:
druid-1.0.9.jar
MySQL的连接驱动:
mysql-connector-java-5.1.18-bin.jar
JDBCTemplate相关的:
commons-logging-1.2.jar
spring-beans-4.2.4.RELEASE.jar
spring-core-4.2.4.RELEASE.jar
spring-jdbc-4.2.4.RELEASE.jar
spring-tx-4.2.4.RELEASE.jar
BeanUtil:
commons-beanutils-1.8.3.jar
JSTL:
javax.servlet.jsp.jstl.jar
jstl-impl.jar
jedis和jedisPool:
commons-pool2-2.3.jar
jedis-2.7.0.jar
2.2 Druid配置文件:druid.properties
```
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql:///day23
username=root
password=root
initialSize=5
maxActive=10
maxWait=3000
```
3.代码编写--------缓存思想
查询数据库比较耗时一些,而且这些省份的数据不经常发生变化,省份一般是固定的。
那么我每一次都去加载数据库,性能就会受到影响。
--------------------------------缓存思想
1.做一个redis缓存
2.service先从redis中查询数据
1.没有-->再冲数据库中查询 (Dao)--->再将数据存到redis中--->返回数据
2.发现有-->直接返回数据
降低了对数据库的访问频率。
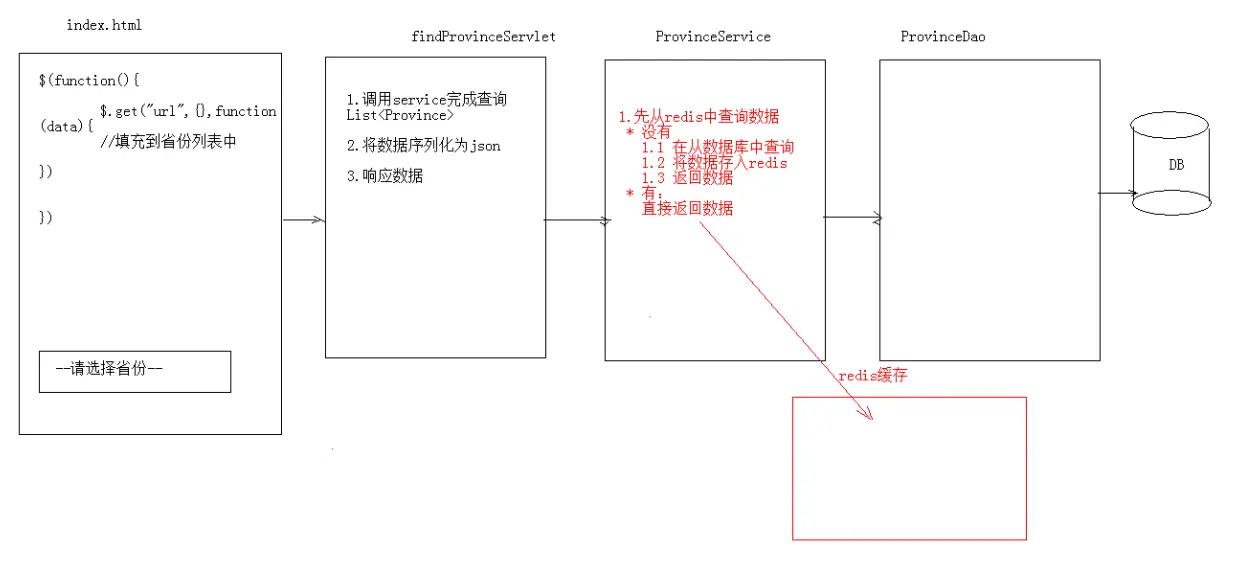
注意:使用redis来缓存一些不经常发生变化的数据。
* 数据库的数据一旦发生变化,则需要更新缓存,不然查询到的是老的缓存。
* 解决方法:在service对应的增删改方法中,去将redis数据删除。


