

作为软件开发人员,相信大家对MySQL肯定不陌生。相比于专业的DBA,我们软件开发人员对数据库的熟练要求可能没那么高,但SQL语句编写肯定是要掌握的基本技能,SQL语句执行的效率高低也是影响开发产品的重要因素之一。最近在重新翻看《高新能MySQL》一书,里面提到了不少优化的思路和策略,根据我自己的阅读感受,筛选记录如下,希望也能对看到本文的朋友有一定帮助。
首先,良好的逻辑设计和物理设计可谓是高性能的"地基",需要权衡各种因素来进行综合设计,比如,理论而言,数据库的设计最低应该满足第三范式的要求,但在许多业务复杂的系统当中,经常会有反范式的设计,从而使查询简化;比如对需要经常汇总或计数的数据,添加汇总表或计数表,将计数或汇总的数据直接保存在表中,避免了多次查询时需要多次汇总或计数,是一种较好的优化查询方式。
本篇文章将会首先谈谈这部分内容,也为后面的内容做铺垫。
1.选择合适的数据类型
一般情况下,有这么几条通用的规则:
-
更小的通常更好
更小的数据类型通常更快,因为他们占用更少的磁盘、内存和CPU缓存。但也要注意,尽量确保没有低估需要存储的值的范围,否则后期修改可能会比较耗时。
-
简单的通常更好
简单类型的操作通常需要更少的CPU周期,比如整数就比字符串操作代价更低。
-
尽量避免NULL
如果存储不需要NULL值,尽量制定列为NOT NULL。可以为NULL的列会使用更多的存储空间,同时,可以为NULL的列被索引后,每条记录都需要一个额外的字节,甚至还能导致MyISAM 中固定大小的索引变成可变大小的索引。
1.1 整数类型
主要由以下这几种整数类型,存储的范围如图所示
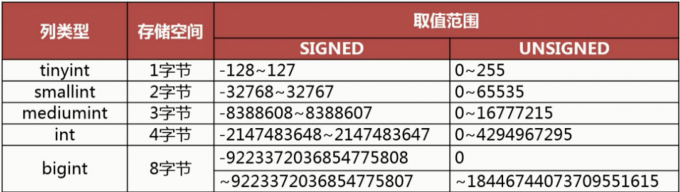
1.2 实数类型
对于实数类型,主要说明一点,我们知道,FLOAT和DOUBLE在对小数进行计算时,会有精度丢失的问题,比如财务数据,应当选择DECIMAL类型,但DECIMAL为了保持精度,在计算时需要额外的空间和计算开销,综合考虑下,可以选择将小数位数扩大N倍,将其类型可以转换为合适的整数类型,这样可以同时避免浮点数计算不精确和DECIMAL计算代价高的问题。

1.3 字符串类型
CHAR和VARCHAR
CHAR和VARCHAR是两种最主要的字符串类型。以下是他们的一些比较:
-
VARCHAR
用于存储可变长字符串,它比定长类型更节省空间,仅适用必要的空间。
需要1或2个额外字节来记录字符串的长度(长度是否大于255字节)。
适用情况:字符串最大长度比平均长度大很多,列的更新较小。
在MySQL 5.0或更高版本中,存储和检索时保留末尾空格。
-
CHAR
用于存储定长字符串。
适用情况:很短的字符串,或者所有值都接近同一个长度。
存储和检索时自动删除末尾空格。
BINARY和VARBINARY
二者与CHAR和VARCHAR类似,只不过存储的是二进制字符串,要注意,该二进制字符串存储的是字节码而不是字符,MySQL填充BINARY采用的是\0而不是空格,检索是也不会去掉填充值。
BLOB和TEXT
BLOB和TEXT都是为了存储很大的数据而设计的,分别采用二进制和字符方式存储,对他们排序时,也只会对列的最前max_sort_length字节而不是整个字符串做排序。
另外,MySQL内存临时表不支持TEXT、BLOB这样的大数据类型,如果查询中包含这样的数据,在排序等操作时,就不能使用内存临时表,必须使用磁盘临时表进行,导致查询效率缓慢。所以,应该尽量避免使用这两种类型,实在无法避免的,利用substring(column,length)函数将其改变为字符串。
1.4 时间类型
DATETIME
DATETIME 年月日时分秒格式,占用8个字节,时间范围从1000-01-01 00:00:00到9999-12-31 23:59:59
TIMESTAMP
Timestamp 时间戳,存储由格林尼治时间1970年1月1日到当前时间秒数,显示依赖于时区,占4个字节,只能存储时间范围1970-01-01到2038-01-19。如果某一行有TIMESTAMP类型的列,那么行数据修改时都会自动修改TIMESTAMP列的值
如无特殊要求,推荐使用TIMESTAMP保存时间,比DATETIME效率更高。
2. 范式和反范式
简单复习一下第一、二、三范式的内容
- 1NF:数据库表的每一列都是不可分割的原子数据项,原子性;
- 2NF:有主键,非主键字段依赖主键,唯一性 一个表只说明一个事物;
- 3NF:非主键字段不能相互依赖,每列都与主键有直接关系,不存在传递依赖;
范式优点主要包括:范式化的更新操作通常比反范式化更快;很少或者没有重复数据,修改变动小;表通常也较小,执行操作会更快。缺点就是通常需要关联。反之,反范式的优点则是可以很好的避免关联。
在实际情况下,基本采用范式与反范式混用的规则。
3. 缓存表、汇总表
有时提升性能的好方法就是把衍生的冗余数据保存起来。”缓存表“来表示存储那些比较简单就能从数据库获取的数据(但是每次获取速度比较慢,比如有额外的逻辑操作),”汇总表“则保存的是使用GROUP BY语句聚合数据的表。
比如,需要统计一个网站24小时发送的消息数,可以每小时生成一张汇总表,这样一条简单的查询或许就可以实现。
缓存表则对优化搜索和检索查询语句很有效,比如,我们可能会需要许多不用的索引组合来加速各种类型的查询,我们可以创建一张只包含主表部分数据列的缓存表。
4.计数器表
假设有如下表结构的一张计数器表,只有一行数据,保存次数
create table counter(
cnt int not null
)
对于任何想要更新这一行的事务来说,由于互斥锁的存在,这些事务只能串行进行。为了获得更高的并发性能,借鉴“分段锁”的思想,完全可以将计数保存在多行中,结构如下
create table counter(
slot tinyint not null primary key,
cnt int not null
)
在更新时,可以随机选一个slot进行更新,最终统计结果时,将cnt汇总即可。
5.加快ALTER TABLE的速度
一般情况下,我们修改表结构的操作方法都是用新的结构创建一个新表,然后把旧表的数据插入,最后删除旧表。然而这样的操作可能会花费很长的时间。尽管重建表的操作很费时间,以InnoDB引擎为例,直接修改表的.frm文件是很快的。如果愿意冒一些风险,有一些操作是有可能不需要重建表的(注意:这些技巧不受官方支持,建议做好备份):
-
移除一个列的AUTO_INCREMENT属性
-
增加、查询或更改ENUM和SET常量
基本操作如下:
- 创建一张具有相同结构的新表,并且进行所需要的修改
- 执行
FLUSH TABLES WITH READ LOCK,这会关闭所有正在使用的表,并且禁止任何表被打开 - 交换
.frm文件 - 执行
UNLOCK TABLES释放第二步的锁
6. 主要的参数配置
-
单个线程的设置
需要注意大小,避免内存溢出
sort_buffer_size排序时分配的缓存大小join_buffer_size连接时分配的缓存大小read_buffer_sizeMyISAM 引擎读文件时的内存大小 -
缓冲池的配置
Inno_db_buffer_pool_size定义innodb缓存池大小,多数表的引擎都是innodb,所以内存要足够,这直接影响mysql性能key_buffer_sizeMyISAM缓冲池大小 -
IO配置
Innodb会把sql预先保存在事务文件中,减少io次数Innodb_log_file_size控制单个事务文件的大小Innodb_log_file_in_group控制事务文件的个数Innodb_log_buffer_size事务文件缓冲区大小Innnodb_flush_log_at_trx_commit事务日志的刷新频繁程度(0每秒进行一次log写入cache,并flush到磁盘;1.每次事务提交执行log写入cache,并flush到磁盘,默认;2每次事务提交执行log写入cache,每秒执行一次flush到磁盘,建议,进程崩溃不会丢失事务)innodb_file_per_table=1innodb为每个表单独创建一个表空间,强烈建议innodb_doublewrite=1启动双写,innodb默认每页16K,写入时如果发生错误,可能会丢失,开启双写缓存增加数据安全性 -
安全配置
expire_logs_days指定自动清理binlog的天数max_allowed_packetmysql可以接受的包大小skip_name_resolve禁用DNS查找。连接服务器使mysql会利用DNS验证域名 ,禁用后避免DNS服务器有问题导致查询堆积
