

排序的分类
1.内排序:是在排序整个过程中,待排序的所有记录全部被放置在内存中;
2.外排序:由于排序的记录个数太多,不能同时放置在内存,整个排序过程需要在内外存之间多次交换数据才能进⾏。
#define OK 1
#define ERROR 0
#define TRUE 1
#define FALSE 0
typedef int Status;
//排序算法数据结构设计
//用于要排序数组个数最大值,可根据需要修改
#define MAXSIZE 10000
typedef struct {
//用于存储要排序数组,r[0]用作哨兵或临时变量
int r[MAXSIZE+1];
//用于记录顺序表的长度
int length;
}SqList;
//排序常用交换函数实现
//交换L中数组r的下标为i和j的值
void swap(SqList *L,int i,int j) {
int temp=L->r[i];
L->r[i]=L->r[j];
L->r[j]=temp;
}
//数组打印
void print(SqList L) {
int i;
for(i=1;i<L.length;i++)
printf("%d,",L.r[i]);
printf("%d",L.r[i]);
printf("\n");
}
冒泡排序算法(Bubble Sort) :
两两⽐较相邻的记录的关键字,如果反序则交换,直到没有反序的记录为⽌.
复杂度分析:
时间复杂度:O(n2);
空间复杂度: O(1)。
//冒泡排序-对顺序表L进行交换排序(冒泡排序初级版本)
void BubbleSort0(SqList *L) {
int i,j;
for (i = 1; i < L->length; i++) {
for (j = i+1; j <= L->length; j++) {
if(L->r[i] > L->r[j])
swap(L, i, j);
}
}
}
//冒泡排序-对顺序表L作冒泡排序(正宗冒泡排序算法)
void BubbleSort(SqList *L){
int i,j;
for (i = 1; i < L->length; i++) {
//注意:j是从后面往前循环
for (j = L->length-1; j>=i; j--) {
//若前者大于后者(注意与上一个算法区别所在)
if(L->r[j]>L->r[j+1])
//交换L->r[j]与L->r[j+1]的值;
swap(L, j, j+1);
}
}
}
//冒泡排序-对顺序表L冒泡排序进行优化
void BubbleSort2(SqList *L) {
int i,j;
//flag用作标记
Status flag = TRUE;
//i从[1,L->length) 遍历;
//如果flag为False退出循环. 表示已经出现过一次j从L->Length-1 到 i的过程,都没有交换的状态;
for (i = 1; i < L->length && flag; i++) {
//flag 每次都初始化为FALSE
flag = FALSE;
for (j = L->length-1; j>=i; j--) {
if(L->r[j] > L->r[j+1]){
//交换L->r[j]和L->r[j+1]值;
swap(L, j, j+1);
//如果有任何数据的交换动作,则将flag改为true;
flag=TRUE;
}
}
}
}
简单选择排序算法(Simple Selection Sort)
通过n-i次关键词⽐较,从n-i+1个记录中找出关键字最⼩的记录,并和第i(1<=i<=n) 个记录进行交换。
复杂度分析:
时间复杂度:O(n2);
空间复杂度: O(1)。
//选择排序--对顺序表L进行简单选择排序
void SelectSort(SqList *L){
int i,j,min;
for (i = 1; i < L->length; i++) {
//① 将当前下标假设为最小值的下标
min = i;
//② 循环比较i之后的所有数据
for (j = i+1; j <= L->length; j++) {
//③ 如果有小于当前最小值的关键字,将此关键字的下标赋值给min
if (L->r[min] > L->r[j]) {
min = j;
}
}
//④ 如果min不等于i,说明找到了最小值,则交换2个位置下的关键字
if(i!=min)
swap(L, i, min);
}
}
直接插⼊排序算法Straight Insertion Sort)
将⼀个记录插⼊到已经排好序的有序表中,从⽽得到⼀个新的,记录数增1的有序表.
复杂度分析
空间复杂度: O(1)
解读:在直接插⼊排序中只使⽤了i,j,temp这三个辅助元素,与问题规模⽆关。
时间复杂度: O(n2)
最好的情况: 顺序序列排序,例如{2,3,4,5,6}.
此时⽐较次数(C _{min})和移动次数(M_{min})达到最⼩值。
C_{min}=n-1
M_{min}=0
当最坏的情况是,即排序的序列是逆序的情况,例如{6,5,4,3,2}
C_{max} = 1+2+...+(n-1) = n(n-1)/2=O(n2)
M_{max} = (1+2)+ (2+2)+.....+(n-1+2)=(n-1)(n+4)/2=O(n2)
//直接插入排序算法--对顺序表L进行直接插入排序
void InsertSort(SqList *L){
int i,j;
//L->r[0] 哨兵 可以把temp改为L->r[0]
int temp=0;
//假设排序的序列集是{0,5,4,3,6,2};
//i从2开始的意思是我们假设5已经放好了. 后面的牌(4,3,6,2)是插入到它的左侧或者右侧
for(i=2;i<=L->length;i++)
{
//需将L->r[i]插入有序子表
if (L->r[i]<L->r[i-1])
{
//设置哨兵 可以把temp改为L->r[0]
temp = L->r[i];
for(j=i-1;L->r[j]>temp;j--)
//记录后移
L->r[j+1]=L->r[j];
//插入到正确位置 可以把temp改为L->r[0]
L->r[j+1]=temp;
}
}
}
希尔排序算法(Shell Sort)
在插⼊排序之前,将整个序列调整成基本有序. 然后再对全体序列进⾏⼀次直接插⼊排序
思想:
希尔排序是把记录按下标的⼀定增量分组,对每组使⽤直接插⼊排序算法排序;随着增量逐渐减少,
每组包含的关键词越来越多,当增量减⾄1时,整个序列恰被分成⼀组,算法便终止。
复杂度分析
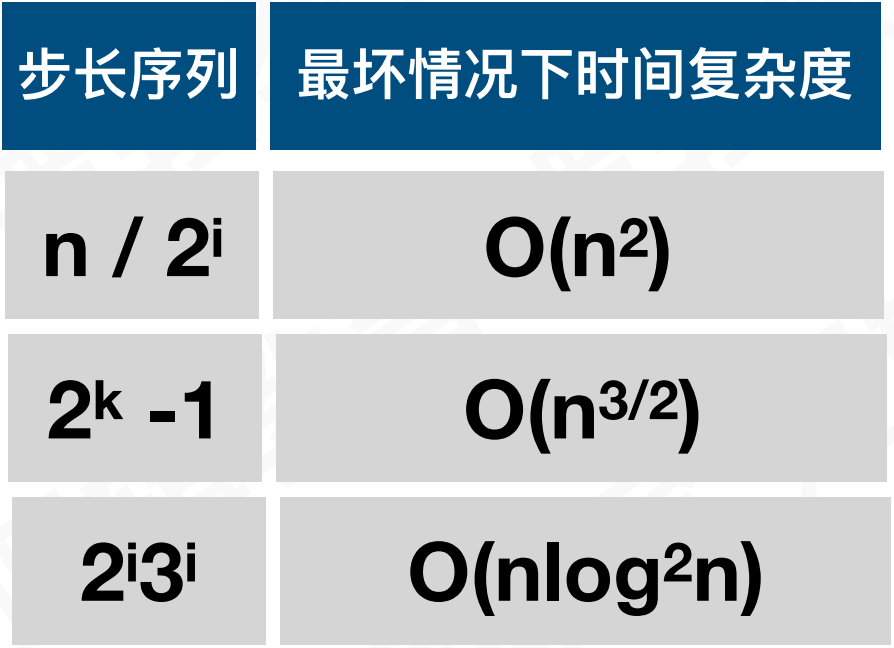
//希尔排序-对顺序表L希尔排序
void shellSort(SqList *L) {
int i,j;
int increment = L->length;
//0,9,1,5,8,3,7,4,6,2
//① 当increment 为1时,表示希尔排序结束
do {
//② 增量序列
increment = increment/3+1;
//③ i的待插入序列数据 [increment+1 , length]
for (i = increment+1; i <= L->length; i++) {
//④ 如果r[i] 小于它的序列组元素则进行插入排序,例如3和9. 3比9小,所以需要将3与9的位置交换
if (L->r[i] < L->r[i-increment]) {
//⑤ 将需要插入的L->r[i]暂时存储在L->r[0].和插入排序的temp 是一个概念;
L->r[0] = L->r[i];
//⑥ 记录后移
for (j = i-increment; j > 0 && L->r[0]<L->r[j]; j-=increment) {
L->r[j+increment] = L->r[j];
}
//⑦ 将L->r[0]插入到L->r[j+increment]的位置上;
L->r[j+increment] = L->r[0];
}
}
}while (increment > 1);
}
堆排序算法(Heap Sort)
”堆”结构
堆是具有下⾯性质的完全⼆叉树:
每个结点的值都⼤于或等于其左右孩⼦结点的值,称为⼤顶堆;
或者每个结点的值都⼩于等于其左右孩⼦的结点的值,称为⼩顶堆,
思想:
1.将⽆需序列构建成⼀个堆,根据升序降序需求选择⼤顶堆或⼩顶堆
2.将堆顶元素与末尾元素交换,将最⼤元素”沉"到数组末端;
3.重新调整结构,使其满⾜堆定义,然后继续交换堆顶元素与当前末尾元素,
反复执⾏调整+交换步骤,直到整个序列有序。
一般升序采⽤⼤顶堆,降序采⽤⼩顶堆。
复杂度分析:
时间复杂度为:O(nlogn)
空间复杂度为常数:O(1)
//大顶堆调整函数;
/*
条件: 在L.r[s...m] 记录中除了下标s对应的关键字L.r[s]不符合大顶堆定义,其他均满足;
结果: 调整L.r[s]的关键字,使得L->r[s...m]这个范围内符合大顶堆定义.
*/
void HeapAjust(SqList *L,int s,int m) {
int temp,j;
//① 将L->r[s] 存储到temp ,方便后面的交换过程;
temp = L->r[s];
//② j 为什么从2*s 开始进行循环,以及它的递增条件为什么是j*2
//因为这是颗完全二叉树,而s也是非叶子根结点. 所以它的左孩子一定是2*s,而右孩子则是2s+1;(二叉树性质5)
for (j = 2 * s; j <=m; j*=2) {
//③ 判断j是否是最后一个结点, 并且找到左右孩子中最大的结点;
//如果左孩子小于右孩子,那么j++; 否则不自增1. 因为它本身就比右孩子大;
if(j < m && L->r[j] < L->r[j+1])
++j;
//④ 比较当前的temp 是不是比较左右孩子大; 如果大则表示我们已经构建成大顶堆了;
if(temp >= L->r[j])
break;
//⑤ 将L->[j] 的值赋值给非叶子根结点
L->r[s] = L->r[j];
//⑥ 将s指向j; 因为此时L.r[4] = 60, L.r[8]=60. 那我们需要记录这8的索引信息.等退出循环时,能够把temp值30 覆盖到L.r[8] = 30. 这样才实现了30与60的交换;
s = j;
}
//⑦ 将L->r[s] = temp. 其实就是把L.r[8] = L.r[4] 进行交换;
L->r[s] = temp;
}
//堆排序--对顺序表进行堆排序
void HeapSort(SqList *L){
int i;
//1.将现在待排序的序列构建成一个大顶堆;
//将L构建成一个大顶堆;
//i为什么是从length/2.因为在对大顶堆的调整其实是对非叶子的根结点调整.
for(i=L->length/2; i>0;i--){
HeapAjust(L, i, L->length);
}
//2.逐步将每个最大的值根结点与末尾元素进行交换,并且再调整成大顶堆
for(i = L->length; i > 1; i--){
//① 将堆顶记录与当前未经排序子序列的最后一个记录进行交换;
swap(L, 1, i);
//② 将L->r[1...i-1]重新调整成大顶堆;
HeapAjust(L, 1, i-1);
}
}
