最近看了下MIT的6.824分布式系统的课程,做了下总结。MIT的开放课程作业是非常非常好的,老师会设计出若干个lab,每个lab分为若干个部分,把框架搭建好,让你来完成各个lab的各个部分,最后实现出一个完整的系统,读研的时候做过JOS,那个时候就收获颇多。
说回6.824里面的mapreduce作业,先说明这里不会把实现代码公开,因为写这个代码作业可能花不了几个小时的时间,但老师设计这个作业可能需要花费非常多的心血,建议大家如果实现了也不要随便发布到网上。这里做这个笔记是总结下老师设计的这个框架,因为我觉得这个作业框架才是精华,如何设计这么一个简单又丰富的作业框架真正体现了老师的水平。这里我是用XMind总结了下,下面会细分的讲下。
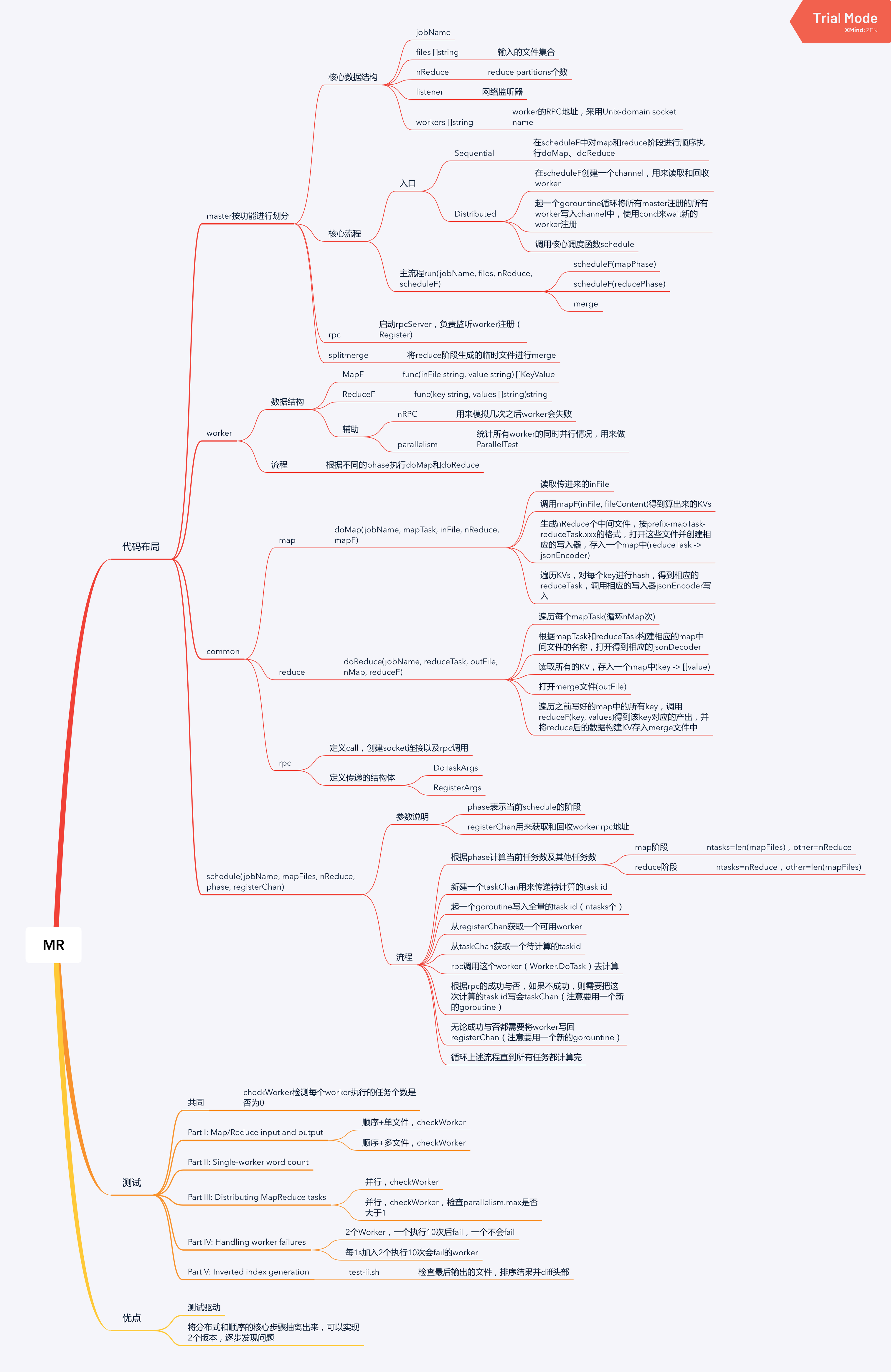
1. 代码布局
代码布局分为4大块,其实按文件名也可以看出来。
master、worker、common、schedule
除此之后还有些test的,不包含在这里面。
1.1 master
按功能划分到几个文件中:
master.go:核心的数据结构,包括jobName、files(输入的文件集合)、nReduce(reduce partition个数)、listener(网络监听器)、workers(worker的RPC地址);核心的流程,包括顺序执行的Sequential和并发执行的Distributed
master_rpc.go:负责rpc相关,启动rpc server,启动一个goroutine来注册worker
master_splitmerge.go:将reduce之后产生的临时文件进行merge
1.2 worker
部分的核心数据结构有mapF、reduceF分别是注册Worker的时候传进来的map函数和reduce函数,还有些辅助的数据结构nRPC表示执行多少次会自动失败(用来模拟网络异常),parallelism,用来记录同时并行的worker个数。
worker的流程很简单,都在对外提供的一个RPC接口中DoTask,根据传进来的phase来执行不同阶段的逻辑doMap和doReduce(在common部分)
1.3 common
这里主要包括3部分,map、reduce、rpc。
map部分只有doMap函数
doMap(jobName, mapTask, inFile, nReduce, mapF)
这代表了Worker在map阶段的处理逻辑,这个阶段每个Worker会有一个输入文件inFile,调用mapF(inFile, fileContent)算出该文件对应的KVs,根据nReduce的个数生成相应的中间文件,m个mapper和n个reducer会生成m*n个中间文件,遍历这些KVs,将其按照Key的hash写入給相应的reducer的中间文件中。
reduce部分只有doReduce函数
doReduce(jobName, reduceTask, outFile, nMap, reduceF)
这代表了Worker在reduce阶段的处理逻辑,这个阶段每个Worker会有根据map的个数(nMap)以及自己的reducer id(reduceTask)计算知道每个map task给自己生成的中间文件的名字,有nMap个,读取这些文件,解释出里面的KVs,按Key汇总成一个map,即Key => [Value],将这些数据写入这个reduceTask对应的mergeFile(outFile)中。
rpc部分是定义了一些rpc用的结构体,比如DoTaskArgs、RegisterArgs以及一个rpc的call接口。
1.4 schedule
这个部分只有一个函数schedule,这个函数是在master里面执行的。
schedule(jobName, mapFiles, nReduce, phase, registerChan)
其中phase表示是map阶段还是reduce阶段,registerChan是用来获取和回收Woker的rpc地址。
主要流程是先根据phase知道这个阶段要计算的task个数,新建一个taskChan来传递task id,这里需要启动一个gorountine来将全部的task id写入taskChan;然后启动循环执行这些task,每次执行需要先从registerChan获取一个worker,从taskChan获取一个task,通过rpc调用