

今天我们一起来学习一下语言模型N-gram,首先我们来用数学的方法来描述一下语言的规律,这个数学模型就是我们在自然语言处理中的统计语言模型(Statistical Language Model)。在自然语言处理中,所谓的一个句子是否合理通顺,就看这个句子的可能性,这里的可能性就要用概率来衡量。同一种意思的句子,不同种的表达形式,哪种形式出现的概率最大,那么就表示这个句子是最合理的。
在每一个句子中,我们可以用词来做为组成句子的最小单位,我们举个栗子,假设一个句子S是由n个词w1、w2…wn组成的,那么这个句子存在的可能性为P(S),很容易理解得到P(S)=P(w1,w2…wn),也就是n个词从w1到wn依次排列的可能性,我们回顾一下概率论里面的条件概率,这个在之前的贝叶斯理论中也介绍过,我们可以用公式来表示:
在每一个句子中,我们可以用词来做为组成句子的最小单位,我们举个栗子,假设一个句子S是由n个词w1、w2…wn组成的,那么这个句子存在的可能性为P(S),很容易理解得到P(S)=P(w1,w2…wn),也就是n个词从w1到wn依次排列的可能性,我们回顾一下概率论里面的条件概率,这个在之前的贝叶斯理论中也介绍过,我们可以用公式来表示:
P(A|B)=P(AB)/P(B)⇒P(AB)=A(A|B)⋅P(B)P(A|B)=P(AB)/P(B)⇒P(AB)=A(A|B)⋅P(B)
在B的事件已经发生的情况下发生A事件的概率等于A和B事件同时发生的概率除以B事件的概率,同时我们可以得到A和B事件同时发生的概率等于B事件发生情况下A事件的概率乘以B事件的概率。有了这个公式,我们可以得到:
P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w1,w2)⋅⋅⋅P(wn|w1,w2,...,wn−1)P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w1,w2)⋅⋅⋅P(wn|w1,w2,...,wn−1)
我们在使用百度搜索的时候会有相关的推荐搜索,如下图所示:
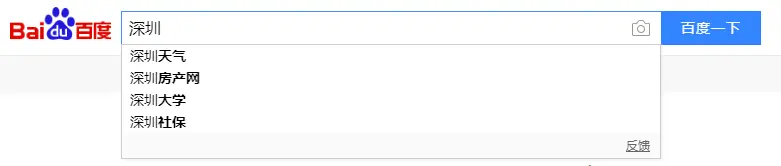
当我在搜索深圳的时候,下面列表会弹出相关的含有深圳关键字的搜索,这个也可以理解成这些词的条件概率:P(天气|深圳)、P(房产网|深圳)、P(大学|深圳)、P(社保|深圳)都是相对来说比较高的。在这个公式中,P(w1)表示w1这个词出现的概率,P(w2|w1)表示w2接在w1词后面的概率,同理P(w3|w1,w2)表示词w3接在w1和w2后面的概率。一般来说,计算词概率的时候,都是用词频除以词库的词数,这样的话,P(w1)其实不难计算,但是P(w2|w1)和P(w3|w1,w2)就很难计算出来了,因为这种条件概率涉及到的变量很多了。为了解决这样的问题,我们这里引入一个马尔可夫假设,具体是这样的:我们假设一个词wn出现的概率只和这个词前面的词wi-1有关,这样就可以简化前面的公式了:
P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w2)⋅⋅⋅P(wn|wn−1)P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w2)⋅⋅⋅P(wn|wn−1)
在引入了这个马尔可夫假设之后,计算整句话可能性机变得简单许多。上述的这个公式所对应的统计语言模型就是二元模型(Bigram model)。同样的道理,我们可以得到,当一个词的概率由前面N-1个词所决定,那么这个就是N元模型,一般来说中文N-gram模型的N不会超过4,N越大,那么计算量就越大。当N=1的时候,一元模型的计算可以写成:
P(w1,w2,...,wn)=P(w1)⋅P(w2)⋅⋅⋅P(wn)P(w1,w2,...,wn)=P(w1)⋅P(w2)⋅⋅⋅P(wn)
三元模型(Trigram)可以写成:
P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w1,w2)⋅P(w4|w2,w3)⋅⋅⋅P(wn|wn−2,wn−1)P(w1,w2,...,wn)=P(w1)⋅P(w2|w1)⋅P(w3|w1,w2)⋅P(w4|w2,w3)⋅⋅⋅P(wn|wn−2,wn−1)
一般我们在中文处理上,二元模型(Bigram)和三元模型(Trigram)是最常使用的,因为比较符合我们中文的分词逻辑。有了这些模型的基础,我们可以看看如何来计算这些条件概率呢,首先我们来看看P(wi|wi-1),我们根据条件概率公式可以得到:
P(wi|wi−1)=P(wi,wi−1)P(wi−1)P(wi|wi−1)=P(wi,wi−1)P(wi−1)
因为这些词都是在同一个语料库,我们假设wi,wi-1出现的次数为#(wi,wi-1),词wi-1出现的次数为#(wi-1),词库总词数为#,所以这些词的相对频率可以表示成:
f(wi,wi−1)=#(wi,wi−1)#f(wi−1)=#(wi−1)#f(wi,wi−1)=#(wi,wi−1)#f(wi−1)=#(wi−1)#
‘’
当然,只要数据量足够大,我们就可以认为词的概率就等于词的相对频率:
f(wi,wi−1)=#(wi,wi−1)#≈P(wi,wi−1)f(wi−1)=#(wi−1)#≈P(wi−1)f(wi,wi−1)=#(wi,wi−1)#≈P(wi,wi−1)f(wi−1)=#(wi−1)#≈P(wi−1)
所以可以将上述两个式子相除可以得到:
P(wi|wi−1)=#(wi,wi−1)#(wi−1)P(wi|wi−1)=#(wi,wi−1)#(wi−1)
通过上述的一系列推倒,我们可以将计算概率的问题简化成了统计词频的问题,我们可以了解一下,为什么通常我们会使用二元模型和三元模型,我们来看看,一元模型是每个词和前面的词是无关的,独立的,二元模型和三元模型是与前后词相关的。首先我们增大N的时候,整个语言模型的大小和速度,也就是空间复杂度和时间复杂度,成指数地增长。当N从1到2,再从2到3,整个模型的效果是明显上升的,但是N从3到4的时候,模型的效果提升就没有很显著了,然后耗费的资源却成指数增长,所以我们一般都是使用Bigram和Trigram模型。
更多免费技术资料可关注:annalin1203
