

逐渐意识到光会用Spark是远远不够的,得了解基本原理和内部实现。遂学习《大规模数据处理实战》,本文为学习笔记。
MapReduce的缺点
- 维护成本高
- 时间达不到用户期望
- 抽象层次低,大部分逻辑都需要用户手动开发
- 很多场景不适合用Map&Reduce来描述
- 每一个Job的计算结果都会存储在HDFS,每一步计算都需要的读取和写入
- 欠缺对流数据处理的支持
Spark
- MapReduce是多进程模型,多进程模型便于细粒度的控制每个任务占用的资源,但是会消耗较多的启动时间。Spark的并行机制是多线程模型,同一节点的任务以多线程的方式运行在一个JVM进程中,启动速度更快,CPU利用率更高,内存共享更好。
RDD
- Resilient Distributed Dataset,可以被分区、只读,Spark最基本的数据结构。
- 中间数据缓存在内存中,减少硬盘读写,加快处理速度。
- 每个分区指向一个存放在内存中或硬盘中的数据块,每个数据块是独立的,可以被存放在不同的节点,故天然支持并行操作。
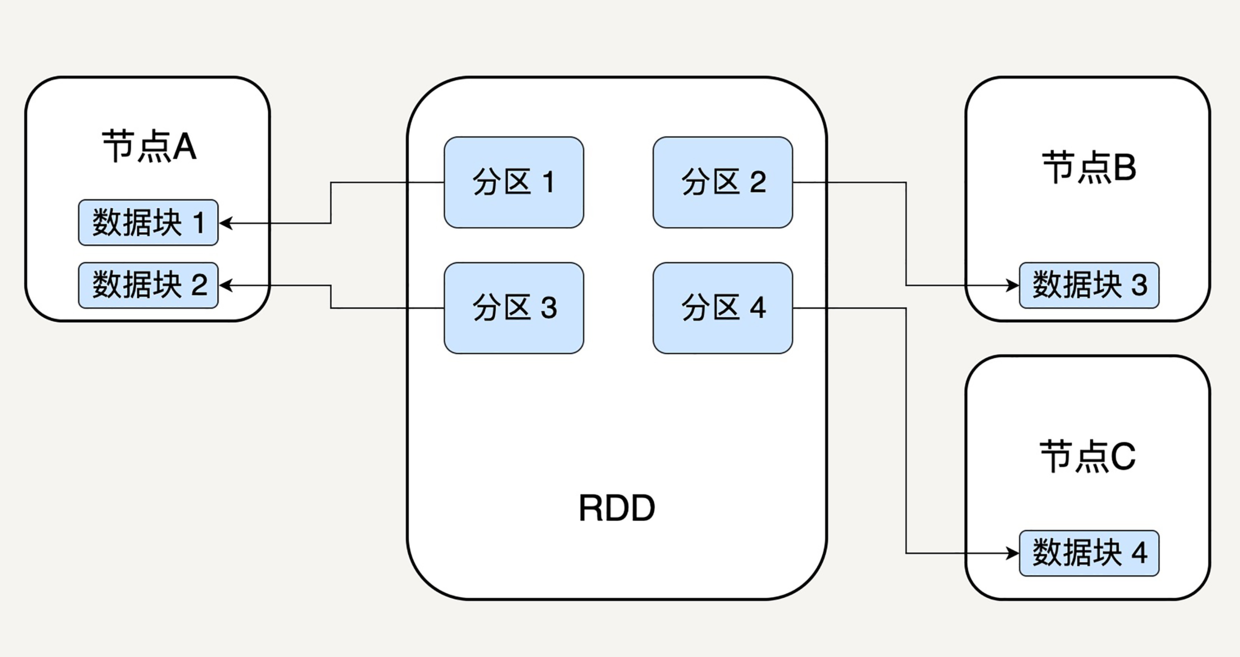
- 已有的RDD不可被改变,可以对现有的RDD进行转换,得到新的RDD
- 记录RDD的依赖关系,不需要立刻去存储计算出来的数据
- 提高Spark的计算效率,并且是错误恢复更加容易,因为当第N步输出RDD节点发生故障时,只需要从第N-1步的RDD出发,再次计算即可。
- RDD结构:
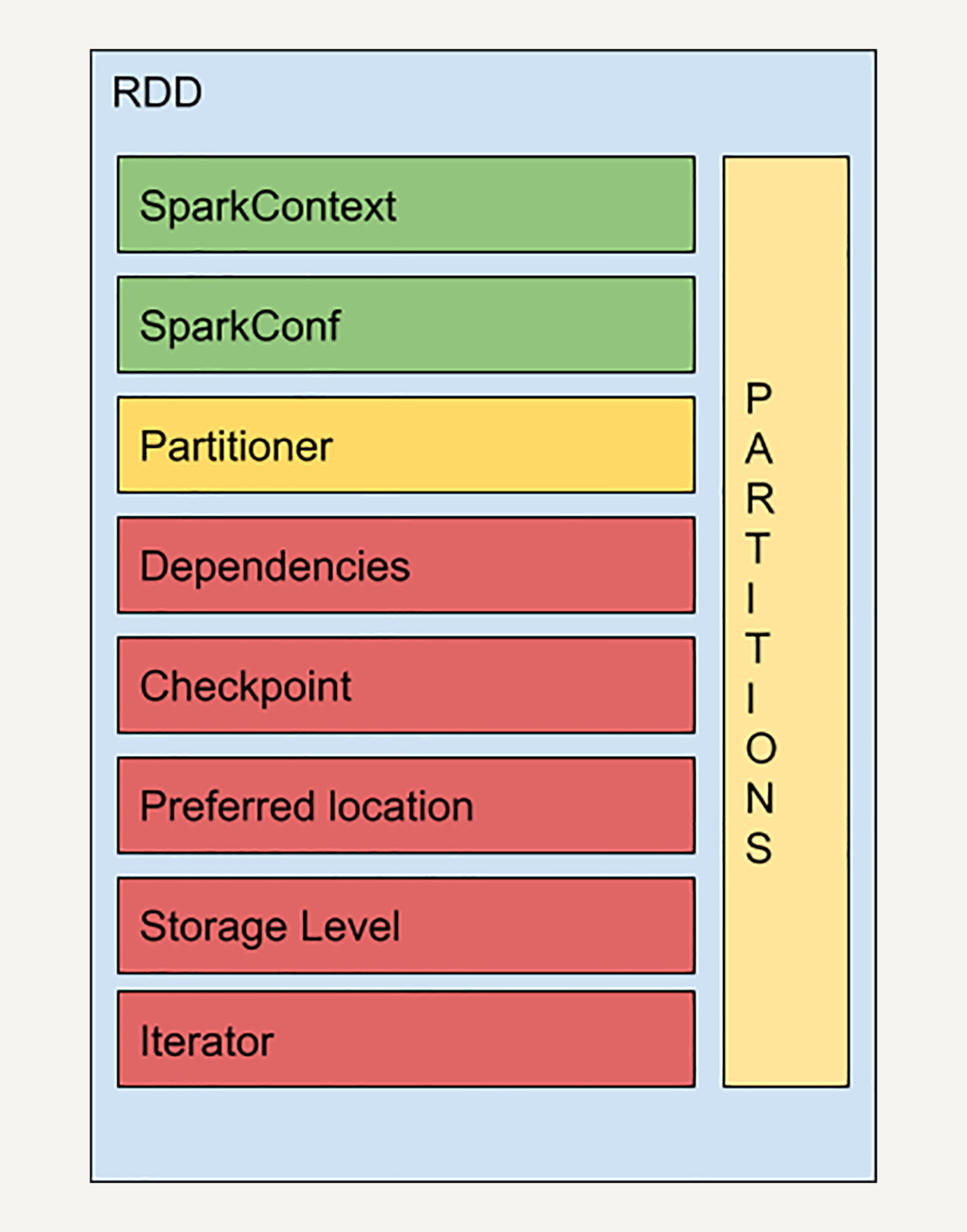
- SparkContext是与Spark节点的连接,一个线程只有一个SparkContext
- SparkConf是参数配置信息
- Partitions是RDD中数据的逻辑结构,每个Partition映射到某个节点内存或硬盘的一个数据块
- Partitioner决定分区方式,主流Hash和Range
- Dependencies存储依赖关系,通过哪个RDD经过哪个转换得到的
- 窄依赖:每个分区可以并行处理产生,map、filter等。可以支持同一个节点上链式执行多条命令;失败恢复更有效,只需要重新计算丢失的父分区即可。
- 宽依赖:必须等父RDD所有分区都计算好后才可以开始处理,join、groupBy等。需要等父分区都是可用的;失败恢复牵涉到多个父分区。
- Checkpoint对于比较耗时的RDD,将它缓存至硬盘或者HDFS,标记这个RDD被检查点处理过,并清空所有的依赖关系,同时,新建一个依赖于CheckpointRDD的依赖关系,CheckpointRDD可以用来从硬盘中读取RDD和生成新的分区信息。
- StorageLevel存储级别
- MEMORY_ONLY: 只缓存在内存中,内存不够不缓存多余的部分,默认处理级别
- MEMORY_AND_DISK: 缓存在内存中,内存不够缓存到硬盘中
- DISK_ONLY: 只缓存到硬盘中
- MEMORY_ONLY_2 和 MEMORY_AND_DISK_2 等: 与上面的级别功能相同,只不过每个分区在集群中两个节点上建立副本。
- Iterator和Compute是用来表示RDD怎样通过父RDD计算得到的。首先判断缓存中是否有想要计算的RDD,如果有就直接读取。没有就查找想要计算的RDD是否被检查点处理过,有就直接读取,没有就调用计算函数向上递归,查找父RDD进行计算。
- Spark 在每次转换操作的时候,使用了新产生的 RDD 来记录计算逻辑,这样就把作用在 RDD 上的所有计算逻辑串起来,形成了一个链条。当对 RDD 进行动作时,Spark 会从计算链的最后一个 RDD 开始,依次从上一个 RDD 获取数据并执行计算逻辑,最后输出结果。
- 在缓存 RDD 的时候,它所有的依赖关系也会被一并存下来。所以持久化的 RDD 有自动的容错机制。如果 RDD 的任一分区丢失了,通过使用原先创建它的转换操作,它将会被自动重算。 cache() 方法会默认取 MEMORY_ONLY 这一级别。
数据倾斜
DataSet
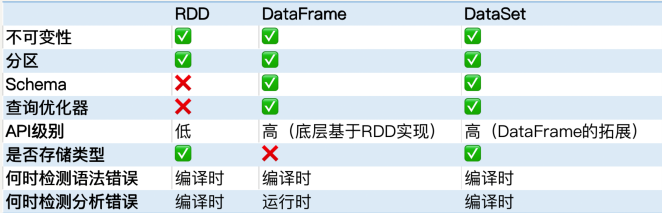
在 Spark 2.0 中,DataFrame 和 DataSet 被统一。DataFrame 作为 DataSet[Row] 存 在。在弱类型的语言,如 Python 中,DataFrame API 依然存在,但是在 Java 中, DataFrame API 已经不复存在了。
- DataFrame 和 DataSet 的性能要比 RDD 更好。
- RDD 和 DataSet 都是类型安全的,而 DataFrame 并不是类型安全的。这是因为它不存储 每一列的信息如名字和类型。
