

一、简介
我们会把一些生产流程、软件开发等当成一个项目工程. 所有的项目工程都可以分为若干个子工程.
如图, 绘制简要的电影制作流程.
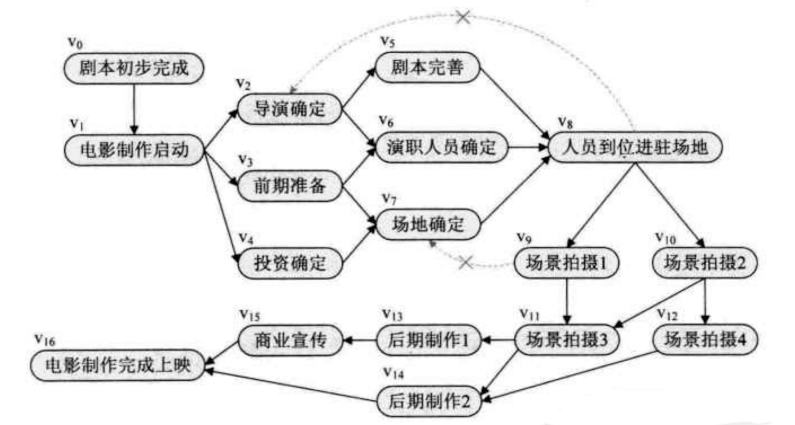
从中可以得知, 某些流程是有条件的, 必须等到前面的工程完成才能继续这个流程. 在一个表示工程的有向图中,用顶点表示活动,用弧表示活动之间的优先关系, 这样的有向图为顶点表示活动的网,我们称之为AOV网(Action On VertexNetwork).
例如V8的执行必须依赖 V5 V6 V7的执行完成, 不能从更早的V0 V1 V2 V3 V4直接进入到V8流程.
设G = (V,E)是一个具有n个顶点的有向图, V中的顶点序列V1, V2,...., Vn若满足从顶点Vi到Vj又一条路径, 则在顶点序列中顶点Vi必在顶点Vj之前, 这我们称这样的顶点序列为一种拓扑序列.
如图中的 V0 V1 V2 V3 V4 V5 V6 V7 V8 V9 V10 V11 V12 V13 V14 V15 V16是一条拓扑排序, V0 V1 V4 V2 V3 V7 V5 V6 V8 V9 V10 V11 V12 V13 V14 V15 V16也是一条拓扑排序, 拓扑序列不一定是固定的
当我们对一个图进行拓扑排序的时候, 是无法确定这个图是否具备拓扑排序的条件, 所谓拓扑排序, 其实就是对一个有向构造拓扑序列的过程, 构造过程中拓扑序列会产生两个结果:
- 如果此网中的全部顶点被输出, 则说明它不存在环(回路)的AOV网
- 如果输出的顶点数少了, 哪怕少一个, 也说明这个网存在环(回路), 不是AOV网
二、拓扑排序算法
对AOV网进行拓扑排序的基本思路是: 从AOV网中选择一个入度为0的顶点输出, 然后删去此顶点, 并删除以此顶点为尾的弧,继续此步骤, 直到输出全部顶点或者AOV网中不存在入度为0的顶点为止.
这里的入度指的是此顶点被几个顶点指向, 例如V2的入度为2.
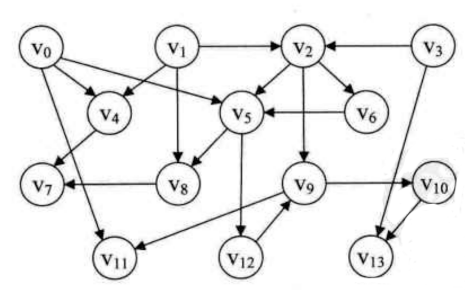
因为在拓扑排序中需要删除节点, 所以使用邻接表会比较方便一些. 所以为AOV网建立一个邻接表. 并且要为它添加一个入度:
/* 邻接表结构****************** */
//边表结点
typedef struct EdgeNode
{
//邻接点域,存储该顶点对应的下标
int adjvex;
//用于存储权值,对于非网图可以不需要
int weight;
//链域,指向下一个邻接点
struct EdgeNode *next;
}EdgeNode;
//顶点表结点
typedef struct VertexNode
{
//顶点入度
int in;
//顶点域,存储顶点信息
int data;
//边表头指针
EdgeNode *firstedge;
}VertexNode, AdjList[MAXVEX];
//图结构
typedef struct
{
AdjList adjList;
//图中当前顶点数和边数
int numVertexes,numEdges;
}graphAdjList,*GraphAdjList;
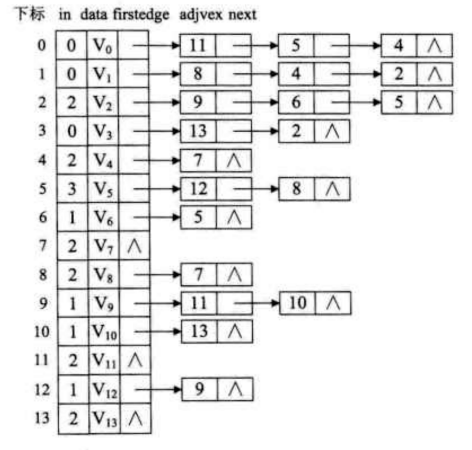
在算法中, 我们还需要一个辅助的栈结构用来处理过程中入度为0的顶点., 目的就是为了避免每个查找时都要去遍历顶点表找有没有入度为0的顶点.
//拓扑排序.若AOV网图无回路则输出拓扑排序的序列并且返回状态值1,若存在回路则返回状态值0
//拓扑排序:解决的是一个工程能否顺序进行的问题!
Status TopologicalSort(GraphAdjList GL) {
EdgeNode *e;
int i, k, gettop;
int top = 0;
int count = 0;//统计输出的顶点个数
int *stack = (int *)malloc(sizeof(int) * GL->numVertexes);
//遍历邻接表->顶点表
for (i = 0; i < GL->numVertexes; i++) {
if (GL->adjList[i].in == 0) {
stack[++top] = i;
}
}
printf("top = %d", top);
while (top != 0) {
//出栈
gettop = stack[top--];
//统计
count++;
//删除链接
for (e = GL->adjList[gettop].firstedge; e; e = e->next) {
//gettop连接的顶点
k = e->adjvex;
//连接顶点减一, 到0即入栈
if (!(--GL->adjList[k].in)) {
stack[++top] = k;
}
}
}
if (count < GL->numVertexes) {
return 0;
}
return 1;
}
三、关键路径
拓扑排序主要是为解决一个工程能否顺利进行的问题, 但是有时我们还需要解决工程完成需要的最短时间问题.
例如, 制造一辆汽车, 我们需要先制造各种各样的零件, 最终组装称一辆汽车. 加入, 造一个轮子需要0.5天, 发动机需要3天, 车底盘需要2天, 外壳需要2天, 其他零件需要2天, 全部零件集中处理需要0.5天, 组装成车需要2天.那么在汽车厂制造一辆汽车最短需要多少时间?
在发动机的三天里, 可以制造出需要的轮子、车底盘、外壳、其他零件, 所以最短的时间应该是 制造零件中最久部分的发动机3天 + 集中零件0.5天 + 组装2天, 一共5.5天可以完成.
之前是在AOV网的基础上, 这里就是在AOV的基础上增加了权值. 在一个表示工程的带权有向图中, 用顶点表示事件, 用有向边表示活动, 用边上的权值表示活动的持续时间, 这种有向图的边表示活动的网, 称之为AOE网.
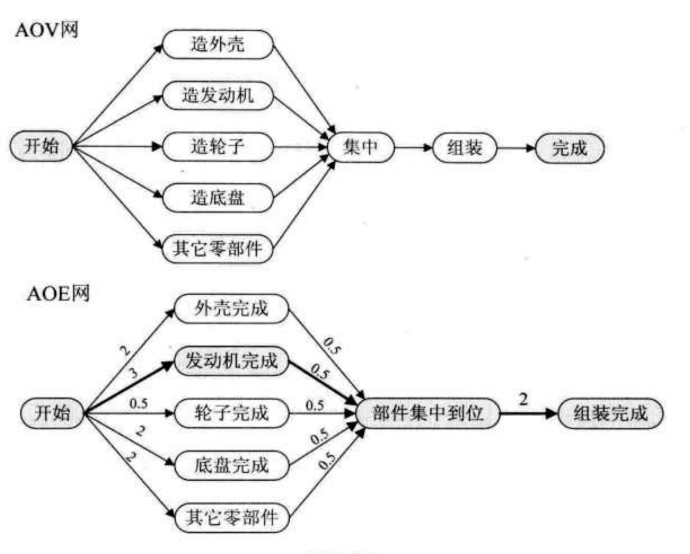
AOV与AOE虽然都是用来对工程建模的, 但是AOV主要还是体现在活动之间的制约关系, 而AOE是要建立在活动制约关系没有矛盾的基础上, 还需要分析整个工程的时间, 每个活动完成所需要的时间, 为缩短完成工程所需的时间, 应该加快哪些活动等问题.
我们把路径上各个活动所持续的时间之和称之为路径长度, 从源点到汇点具有最大长度的路径叫关键路径.
为了缩短工程时间, 只有减少关键路径的时间才能减少工程的工期. 所以首先是需要求出关键路径的
四、关键路径算法
4.1、关键路径算法原理
以造车为例子, 当在造发动的时候, 同时也可以开始制造其他的零件,但是也可以在第2.5天的时候才去造轮子, 也可以完成这个任务. 所以造轮子这个任务的最早开始时间是0, 最晚开始时间是2.5天后, 也就意味着一个活动的最早开始时间与最晚开始时间不相同的话, 那么这个活动是会存在空闲时间的.
为此, 需要定义如下几个参数:
- 事件的最早发生时间etv: 即顶点Vk的最早发生时间
- 事件的最晚发生时间ltv: 即顶点Vk的最晚发生时间
- 活动的最早开工时间ete: 即弧Ak的最早发生时间
- 活动的最晚开工时间lte: 即弧Ak的最晚发生时间, 也就是不推迟工程的最晚开工时间
4.2、关键路径算法实现
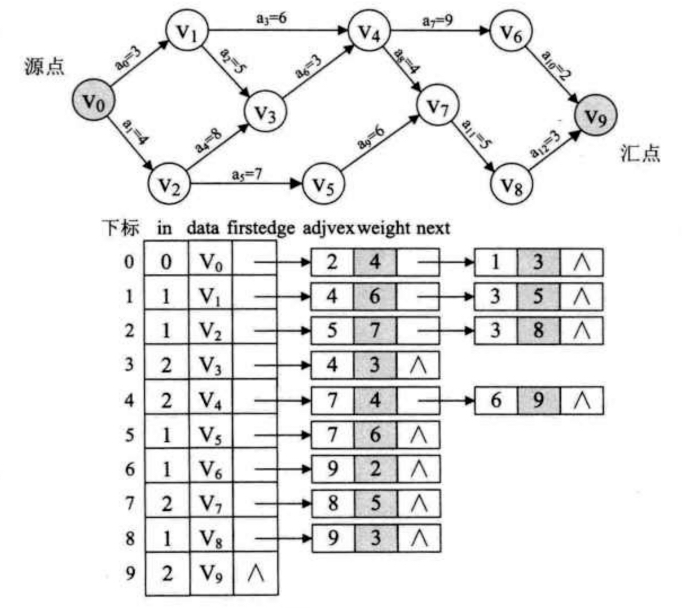
AOV网是基于拓扑排序才生成的, 所以这个AOE网也是需要求一次拓扑排序的. 求事件的最早发生时间etv的过程, 就是从头到尾去找拓扑序列的过程, 所以需要调用拓扑序列算法来计算etv和拓扑序列列表.
先来声明几个全局变量:
int *etv,*ltv; /* 事件最早发生时间和最迟发生时间数组*/
int *stack2; /* 用于存储拓扑序列的栈 */
int top2; /* 用于stack2的指针*/
这里需要对之前的拓扑排序进行改进:
//拓扑排序
Status TopologicalSort(GraphAdjList GL){
//若GL无回路,则输出拓扑排序序列且返回状态OK, 否则返回状态ERROR;
EdgeNode *e;
int i,k,gettop;
//栈指针下标;
int top = 0;
//用于统计输出的顶点个数.作为拓扑排序是否存在回路的判断依据;
int count = 0;
//建栈,将入度in = 0的顶点入栈;
int *stack = (int *)malloc(GL->numVertexes * sizeof(int));
//遍历顶点表上入度in = 0 入栈
for (i = 0; i < GL->numVertexes;i++) {
//printf("%d %d\n",i,GL->adjList[i].in);
if ( 0 == GL->adjList[i].in ) {
stack[++top] = i;
}
}
//* stack2 的栈指针下标初始化
top2 = 0;
//* 初始化拓扑序列栈
stack2 = (int *)malloc(sizeof(int) * GL->numVertexes);
//* 事件最早发生时间数组
etv = (int *)malloc(sizeof(GL->numVertexes * sizeof(int)));
//* 初始化etv 数组
for (i = 0 ; i < GL->numVertexes; i++) {
//初始化
etv[i] = 0;
}
printf("TopologicSort:\t");
while (top != 0) {
gettop = stack[top--];
printf("%d -> ", GL->adjList[gettop].data);
count++;
//将弹出的顶点序号压入拓扑排序的栈中;
stack2[++top2] = gettop;
for(e = GL->adjList[gettop].firstedge; e; e = e->next)
{
k = e->adjvex;
//将i顶点连接的邻接顶点入度减1,如果入度减一后为0,则入栈
if(!(--GL->adjList[k].in))
stack[++top] = k;
//求各顶点事件的最早发生的时间etv值
if ((etv[gettop] + e->weight) > etv[k]) {
etv[k] = etv[gettop] + e->weight;
}
}
}
printf("\n");
if(count < GL->numVertexes)
return ERROR;
else
return OK;
return OK;
}
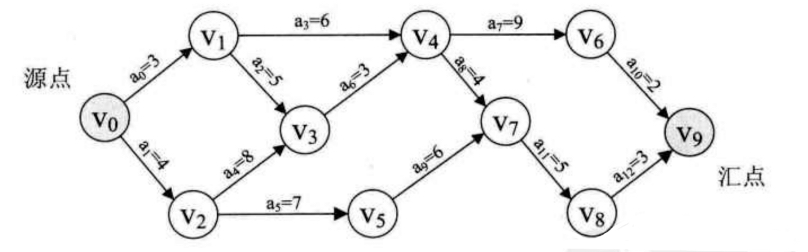
如图所示:
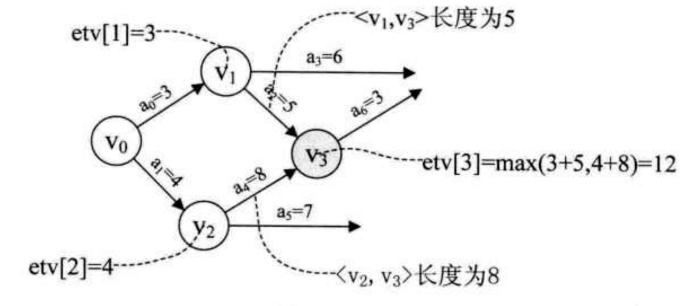
当顶点为, 则etv[0] = 0, 顶点
则是etv[1] = 3, 顶点
则是etv[2] = 4. 接下来就应该是求
的etv[3], 其实就是求etv[1] + len<
,
> 与 etv[2] + len<
,
> 的较大值. 所以etv[3] = 12.
由此可以得出计算顶点即求etv[k]的最早发生时间的公式是:
其中 P[k]表示所有到达顶点 的弧的集合.
接下来就需要求关键路径:
//求关键路径, GL为有向网,则输出G的各项关键活动;
void CriticalPath(GraphAdjList GL){
EdgeNode *e;
int i,gettop,k,j;
//声明活动最早发生时间和最迟发生时间变量;
int ete,lte;
//求得拓扑序列,计算etv数组以及stack2的值
TopologicalSort(GL);
//打印etv数组(事件最早发生时间)
printf("etv:\n");
for(i = 0; i < GL->numVertexes; i++)
printf("etv[%d] = %d \n",i,etv[i]);
printf("\n");
//事件最晚发生时间数组
ltv = (int *)malloc(sizeof(int) * GL->numVertexes);
//初始化ltv数组
for (i = 0; i < GL->numVertexes; i++) {
//初始化ltv数组. 赋值etv最后一个事件的值
ltv[i] = etv[GL->numVertexes-1];
//printf("ltv[%d] = %d\n",i,ltv[i]);
}
//计算ltv(事件最晚发生时间) 出栈求ltv
while (top2 != 0) {
//出栈(栈顶元素)
gettop = stack2[top2--];
//找到与栈顶元素连接的顶点; 例如V0是与V1和V2连接
for (e = GL->adjList[gettop].firstedge; e; e = e->next) {
//获取与gettop 相连接的顶点
k = e->adjvex;
//计算min(ltv[k]-e->weight,ltv[gettop])
if (ltv[k] - e->weight < ltv[gettop]) {
//更新ltv 数组
ltv[gettop] = ltv[k] - e->weight;
}
}
}
//打印ltv 数组
printf("ltv:\n");
for (i = 0 ; i < GL->numVertexes; i++) {
printf("ltv[%d] = %d \n",i,ltv[i]);
}
//求解ete,lte 并且判断lte与ete 是否相等.相等则是关键活动;
//2层循环(遍历顶点表,边表)
for(j=0; j<GL->numVertexes;j++)
{
for (e = GL->adjList[j].firstedge; e; e = e->next) {
//获取与j连接的顶点;
k = e->adjvex;
//ete 就是表示活动 <Vk, Vj> 的最早开工时间, 是针对这条弧来说的.而这条弧的弧尾顶点Vk 的事件发生了, 它才可以发生. 因此ete = etv[k];
ete = etv[j];
//lte 表示活动<Vk, Vj> 的最晚开工时间, 但此活动再晚也不能等Vj 事件发生才开始,而是必须在Vj 事件之前发生. 所以lte = ltv[j] - len<Vk, Vj>.
lte = ltv[k]-e->weight;
//如果ete == lte 则输出j,k以及权值;
if (ete == lte) {
printf("<%d-%d> length:%d\n",GL->adjList[j].data, GL->adjList[k].data, e->weight);
}
}
}
}
