

最近公司培训,这周四的培训主题就是“鬼斧神工之正则表达式-施**”。对于正则表达式早有所了解,但是不够系统,真正业务上要用时,还是重度依赖百度,对百度出来的答案,是否完全符合自己的需求就不得而知。而且看 Linux 组的大佬崇**在 vim 中搜索文本经常使用正则去搜,确实效率很高。除此之外,在平时用 less 命令去查日志时,自己都是直接查询子串,然而有的时候,这种直接查询需要查询多次才能得到自己想要的日志,如果可以熟练使用正则,效率一定会翻倍。还有不管是 IDEA 还是 VsCode,在做搜索时都是支持正则搜索的,比如在 IDEA 中 Command + Shift + F 或 Command +Shift + R 做全局搜索或替换使用正则都是非常方便的。所以提前准备起来,找了本《正则表达式必知必会》学习起来,此处做一笔记。
基本
- 正则表达式区分字母大小写
.字符可以匹配任意单个字符、字母、数字、空格甚至是.字符本身。但在绝大多数正则表达式实现里,.不能匹配换行符\用于转义\.匹配字符.本身\\匹配字符\
字符区间
[abc]匹配字符a或b或c,[0-9]等价于[0123456789][a-z]等价于[abcdefghijklmnopqrstuvwxyz],[A-Z]等价于[ABCDEFGHIJKLMNOPQRSTUVWXYZ],[A-z]等价于[ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz](按照 Ascii 顺序),[A-Za-z0-9]等价于[ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789]
很多程序员喜欢把一个字符也定义为一个字符区间,如
[a]等价于a,[\r]?等价于\r?,但前者可以避免产生误解、增加可读性,所以建议一个字符也定义为字符区间
排除
[^a-c]排除a或b或c
空白字符
[\b]匹配回退(并删除)一个字符(Backspace 键)\f匹配换页符\r匹配回车符\n匹配换行符\t匹配制表符(Tab 键)\v匹配垂直制表符
在 Unix 或 Linux 上使用
\n匹配行尾标记,Windows 上使用\r\n匹配行尾标记
特定字符类型
\d匹配任何一个数字字符,等价于[0-9]\D匹配任何一个非数字字符,等价于[^0-9]\w匹配任何一个字母(大小写均可)或数字类型或下划线字符,等价于[A-z0-9_]\W匹配任何一个非字母(大小写均可)或数字类型或下划线字符,等价于[^A-z0-9_]\s匹配任何一个空白字符,等价于[\f\r\n\t\v ],注意包含空格\S匹配任何一个非空白字符,等价于[^\f\r\n\t\v ]
转义
.、[、]、\、+、*、?、(、)等具有特殊含义的符号被称为元字符,如果要匹配元字符,则需要对元字符进行转义,如\.匹配字符.,\[匹配字符[,\]匹配字符],\\匹配字符\/字符并不是元字符,在绝大多数正则表达式解析器中如果要匹配字符/并不需要转义,但有些解析器却要求必须转义才能够匹配,所以建议总是在需要匹配字符/时对其进行转义,即使用\/匹配字符/,这样在所有解析器中都能够正常工作- 像
.、+这样的元字符出现在字符区间内部时,将会被解释为普通字符,可以不用转义,如[\w\.]等价于[\w.],但为了防止误解,建议显示转义
重复匹配
-
+元字符匹配一个或多个字符,如a+匹配一个或多个连续的a,[0-9]+匹配一个或多个连续的数字 -
*元字符匹配 0 个或多个字符 -
?元字符匹配 0 个或 1 个字符 -
{n}重复匹配 n 次 -
{m,n}重复匹配 m ~ n 次,如{0,1}表示最少匹配 0 次,最多匹配 1 次,等价于? -
{m,}重复匹配至少 m 次 -
*和+是贪婪型元字符,它们会尽可能地从一段文本的开头一致匹配到末尾,而不是碰到一个匹配时就停止,如果想要碰到第一个匹配时就停止,则应该使用元字符对应的懒惰型。*元字符对应的懒惰型为*?,+元字符对应的懒惰型为+?。如想要匹配 HTML<b>标签中的文本,贪婪型正则如下:<[Bb]>.*<\/[Bb]>但对于如下文本匹配却有问题:
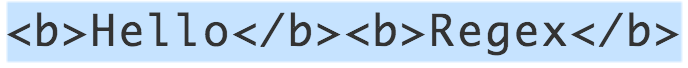
正确写法是使用懒惰型:
<[Bb]>.*?<\/[Bb]>匹配结果:
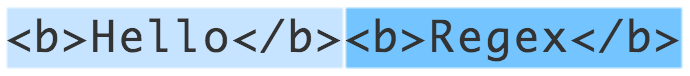
在为字符区间加后缀的时候,必须把后缀放到区间外面,如
[0-9]+是正确的,而[0-9+]是错误的,同理[0-9]*、[0-9]?是正确的,而[0-9*]、[0-9?]是错误的 注意{m,n}是正确的,{m, n}是不正确的,因为个人习惯在英文,后加一个空格,但在使用此正则时需要注意避免
位置匹配
\b表示边界(boundary),匹配单词的开头或结尾。这里所谓的单词是指能够被\w匹配的内容即称为单词,\b匹配的时字符之间的一个位置:一边是单词(能够被\w所匹配的),一边是其它内容(能够被\W所匹配的)。b匹配的是一个位置,而不是任何实际字符\B不匹配单词边界^匹配字符串开头位置。^用于字符区间中表示排除,如[^abc][^a-c]排除a或b或c,但当^用于字符区间之外时,则表示匹配字符串的起始位置$匹配字符串结尾位置(?m)用于开启多行模式,(?m)必须出现在整个模式的最前面,但实际包括 JavaScript 在内的许多正则表达式都不支持(?m)
子表达式
-
前面介绍的重复匹配只作用于紧挨着它的前一个字符或元字符,为了能够重复匹配多个字符,需要使用子表达式
-
子表达式必须出现在元字符
(和)之间 -
对于不需要使用子表达式的地方,如果加上元字符
(和)使其成为子表达式,虽然对匹配结果不会有任何影响,但可能会影响性能,如把\d{1,3}如果写成子表达式:(\d{1,3}),匹配结果完全一样,但后者可能会影响性能 -
因为模式是从左到右进行评估的,首先测试第一个,然后测试第二个,只要有任何一个模式匹配,就不再测试选择结构中的其它模式。比如 IP 地址的匹配: IP 地址范围为 0.0.0.0 ~ 255.255.255.255,总结如下:
- 任意的 1 位或 2 位数字
- 任意的以 1 开头的 3 位数字
- 任意的以 2 开头,第二位数字在 0 到 4 之间的 3 位数字
- 任意的以 25 开头,第三位数字在 0 到 5 之间的 3 位数字
很容易写出如下正则:
(((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))\.){3}((\d{1,2})|(1\d{2})|(2[0-4]\d)|(25[0-5]))但这个正则却是错误的,如 IP 地址:
12.159.46.200的匹配结果如下图,最后的 0 无法被匹配,这是因为20已经被子表达式(\d{1, 2})匹配,并没有被(25[0-5])匹配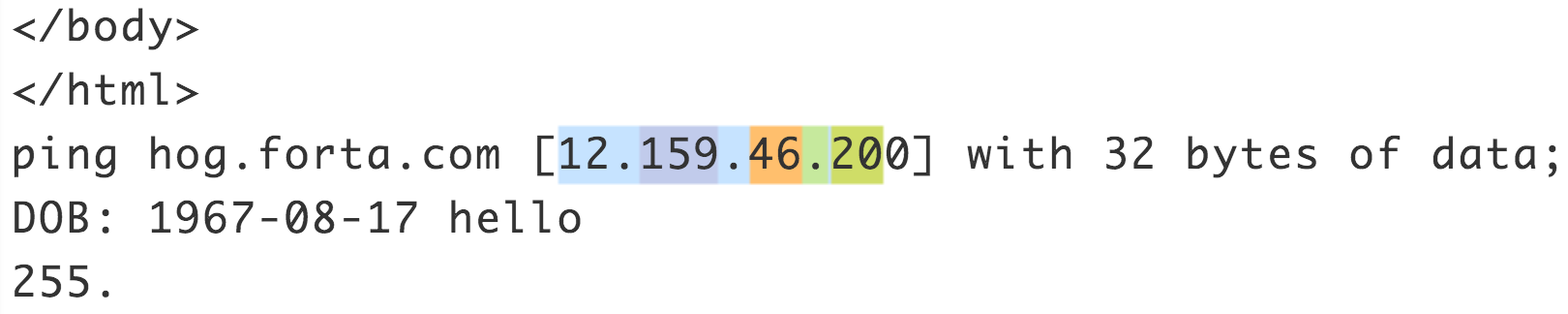
正确的写法如下:
((((25[0-5])\d)|(2[0-4]\d)|(1\d{2})|(\d{1,2}))\.){3}(((25[0-5])\d)|(2[0-4]\d)|(1\d{2})|(\d{1,2}))匹配结果:

反向引用
-
反向引用允许正则表达式模式引用之前匹配的结果,如想要匹配所有的 HTML 标题,正则如下:
(<[Hh]1>.*?<\/[Hh]1>)|(<[Hh]2>.*?<\/[Hh]2>)|(<[Hh]3>.*?<\/[Hh]3>)|(<[Hh]4>.*?<\/[Hh]4>)|(<[Hh]5>.*?<\/[Hh]5>)|(<[Hh]6>.*?<\/[Hh]6>)匹配结果也的确是正确的:

但是这样写未免过于臃肿,所以有人可能会这样写:
<[Hh][1-6]>.*?<\/[Hh][1-6]>但实际这却是错误的,因为他会将
<h2>和</h3>匹配到一块,而这是错误的 HTML 标题:
正确的写法是使用反向引用:
<[Hh]([1-6])>.*?<\/[Hh]\1>匹配结果:

使用了
\1引用了第 1 个子表达式([1-6]),如果有第 2 个、第 3 个等子表达式,则使用\2、\3引用 -
反向引用只能引用括号里的子表达式
-
不同的正则实现中,反向引用的语法存在很大差异,如 JavaScript 和 vim 在搜索时使用
\标识反向引用,在替换时使用$标识反向引用,Perl 搜索和替换都使用$标识反向引用
反向引用替换
-
如将文档中的所有邮箱地址全替换为 HTML 链接
- 先写出正则表达式,找出所有的邮箱地址,为了能够使用反向引用,加
(和)让其变成子表达式:(\w+[\w\.]*@[\w\.]+\.\w+) - 编写替换的表达式:
<a href="mailto:$1">$1</a> - 开始替换,可以使用编程语言,如 JavaScript,这里简单直接以 VsCode 操作为例(注意要选择正则表达式模式):

点击替换按钮,替换结果如下:

- 先写出正则表达式,找出所有的邮箱地址,为了能够使用反向引用,加
-
反向引用替换大小写转换(并不是所有正则表达式实现都支持):
\U把\U到\E之间的字符全部转换为大写\L把\L到\E之间的字符全部转换为小写\E结束\U或\L转换u把下一个字符转换为大写l把下一个字符转换为小写
环视
?=表示向前查看,如:?=:匹配字符:但不消耗字符:,所谓的不消耗是指匹配到的:不会在最终的匹配结果中返回。如对于如下文本:
表达式http://www.baidu.comhttp:匹配http:,而如果使用向前查看,表达式为:http(?=:),匹配结果为:http,不包含字符:?<=表示向后查看,如:?<=\$匹配字符$,但不消耗字符$,如对于如下文本:ABC01: $253.00\$[\d\.]+\d{2}匹配$253.00,而如果使用向后查看,表达式为:(?<=\$)[\d\.]+\d{2},匹配结果为:253.00,不包含字符$- 向前查看和向后查看的否定式分别为:
?!和?<!,即将肯定式中的=换成!
所有主流正则表达式实现都支持向前查看,但有些语言不支持向后查看,如 JavaScript
正则测试网站
参考
- 《正则表达式必知必会修订版》
欢迎大家关注我的微信公众号,会不定期分享实际业务架构、算法和学习笔记:

